Ważne biblioteki¶
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import scipy.stats as ss
from matplotlib.patches import Circle
import matplotlib.patches as patches%matplotlib inline
%config InlineBackend.figure_format = 'retina'## Koncepcja samplingu
exec(open('sampling_pic.py').read())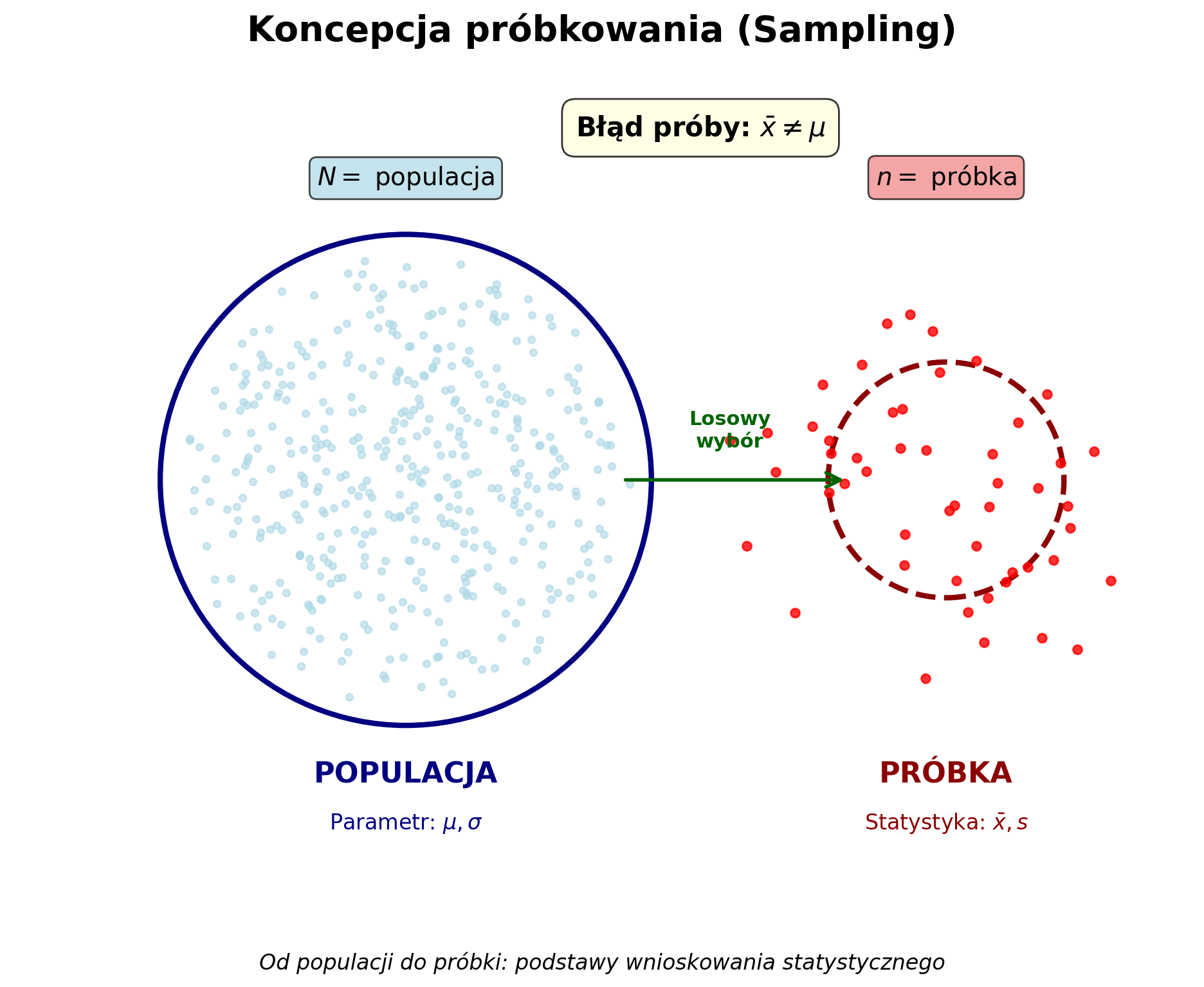
Cele tego rozdziału¶
Jest to ostatni wykład przed przejściem do modelowania statystycznego.
Ma on kilka celów:
Przejście od czysto statystyki opisowej (
średniaitp.) do wnioskowania statystycznego.Rozróżnienie między próbkami a populacjami.
Rozpoznawanie błędu próby.
Błąd standardowy i podstawy rozkładów próbnych.
Statystyka opisowa a wnioskowanie statystyczne¶
W „zestawie narzędzi” statystyki znajdują się co najmniej dwie półki:
Statystyka opisowa: opisuje posiadane dane (np.
średnia,mediana,odchylenie standardoweitp.).Statystyka matematyczna: próbuje uogólnić posiadane dane na szerszą populację.
Próbki a populacje¶
W statystyce populacja to zbiór potencjalnych obserwacji, które nas interesują. Pełen n z N zbiór.
Rzadko zdarza się, abyśmy mogli obserwować całą populację, która nas interesuje, chyba że jest ona bardzo wąska.
Na przykład „wszyscy ludzie na świecie” to bardzo szeroka populacja.
Nawet „wszyscy studenci PG” to duża populacja.
Dlatego zazwyczaj opieramy się na próbie.
Próba to rzeczywisty zbiór obserwacji pobranych z populacji.
Wyzwanie związane z uogólnianiem¶
Aby dokonać uogólnienia, próbki muszą być losowe i reprezentatywne.
W przeciwnym razie możemy nadmiernie reprezentować lub niedostatecznie reprezentować niektóre subpopulacje.
Niestety, wiele próbek to „próbki wygodne” – czyli te, które są dostępne w danym momencie.
Pytanie 1.¶
Jaki przykład z wcześniejszej części zajęć pokazuje, jak niereprezentatywna próba może prowadzić do obciążonych modeli?
Błąd próby: kolejne wyzwanie¶
Nawet jeśli próba jest reprezentatywna, nigdy nie jest identyczna z populacją bazową.
Błąd próby oznacza, że statystyki obliczone na podstawie próby (np. średnia) rzadko (o ile w ogóle) będą identyczne z parametrem populacji bazowej.
Średnia z próby¶
Średnia próby () rzadko, jeśli w ogóle, będzie identyczna ze średnią populacji ().
Symulacja 1.¶
## Najpierw należy utworzyć „populację”.
np.random.seed(10)
pop = np.random.normal(loc = 0, scale = 3, size = 1000)
pop.mean()np.float64(-0.04366990684641133)## Teraz pobierz próbkę z tej populacji za pomocą np.sample
sample = np.random.choice(pop, size = 100)
sample.mean()np.float64(-0.17870546982513766)Pytanie 2.¶
Co by było, gdybyśmy pobrali kilka próbek z naszej populacji, wszystkie tej samej wielkości, i obliczyli średnią każdej próbki?
Jak moglibyśmy nazwać ten zestaw statystyk próbek?
Jak myślisz, co byłoby prawdą w odniesieniu do „średniej” tego zestawu statystyk próbek?
Odpowiedź¶
Nazywa się to rozkładem próbkowym.
Ten rozkład próbkowy będzie miał rozkład normalny wokół rzeczywistej średniej populacyjnej!
Wprowadzenie do rozkładów z próby¶
Rozkład z próby to rozkład statystyk próbnych (np.
średniej) pobranych ze wszystkich możliwych prób o wielkości .
Rozkłady próbkowe w praktyce¶
Najpierw symulujemy naszą podstawową populację bazową.
np.random.seed(seed=10)
pop = np.random.normal(loc = 65, scale = 3, size = 5000)
g = sns.histplot(pop)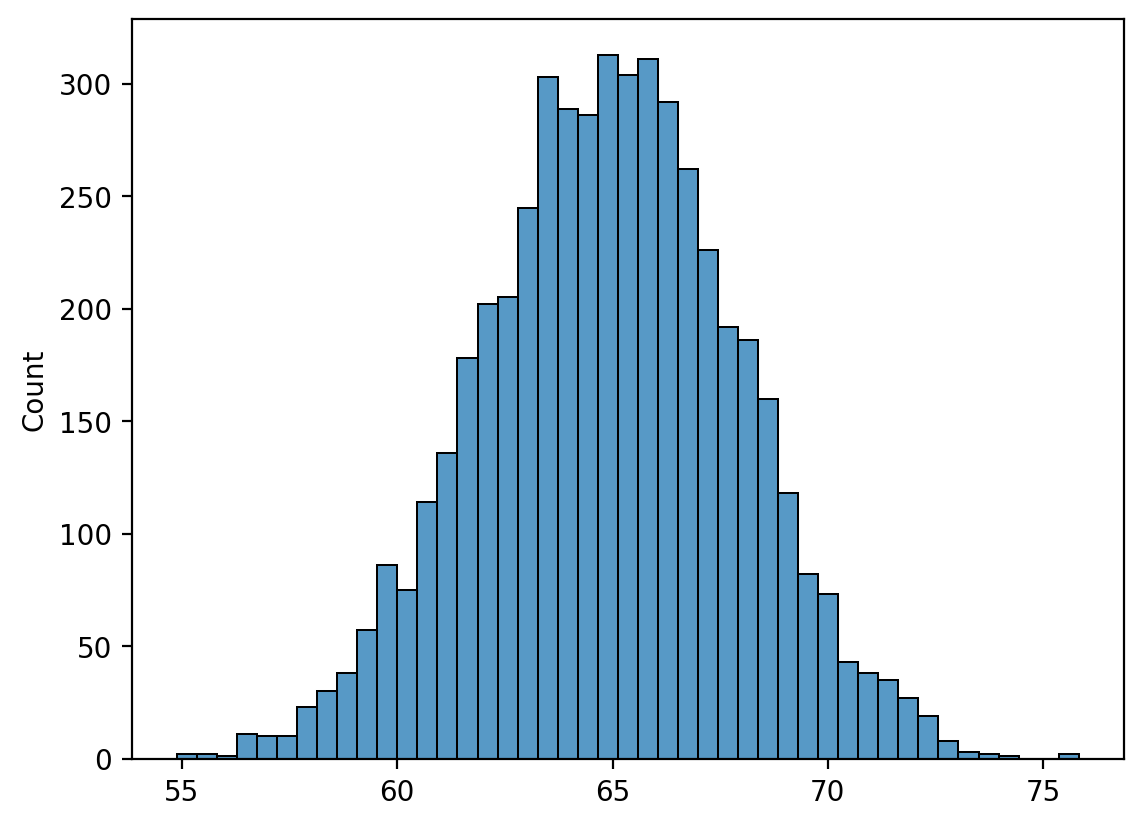
Tworzenie rozkładu próby¶
Teraz pobieramy próbki z tej populacji 300 razy, przy czym wielkość każdej próbki wynosi .
Co zauważamy w rozkładzie średnich tych próbek? (Należy pamiętać, że nie jest to „prawdziwy” rozkład próby, ponieważ nie obejmuje on wszystkich możliwych próbek).
sample_means_n5 = []
for _ in range(300):
sample = np.random.choice(pop, size = 5, replace = False)
sample_means_n5.append(sample.mean())
g = sns.histplot(sample_means_n5)
plt.xlabel("Średnia z próby (n = 5)")
plt.axvline(pop.mean(), linestyle = "dotted", color = "red");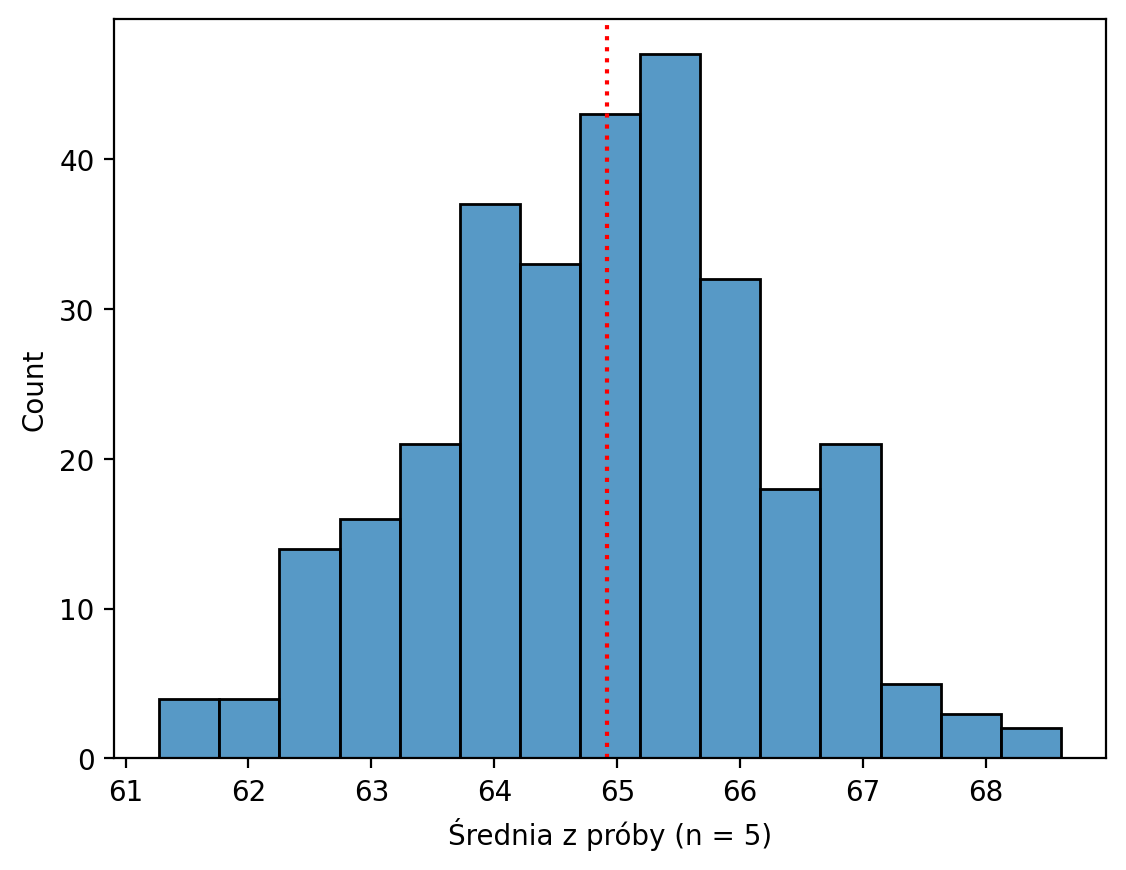
Dlaczego ma znaczenie¶
Porównajmy teraz kilka rozkładów:
Populacja pierwotna
Rozkład próby przy
Rozkład próby przy
Tworzenie nowego rozkładu próbkowania, gdzie ¶
sample_means_n40 = []
for _ in range(300):
sample = np.random.choice(pop, size = 40, replace = False)
sample_means_n40.append(sample.mean())Wizualizacja obok siebie¶
Co zauważamy w rozkładzie próbkowania, gdy staje się większe?
# Teraz wizualizujemy je wszystkie razem.
f, (ax1, ax2, ax3) = plt.subplots(1, 3, sharex = True)
f.set_figwidth(9)
og = ax1.hist(pop, alpha = .5)
ax1.title.set_text("Populacja bazowa")
og_s1 = ax2.hist(sample_means_n5, alpha = .5)
ax2.title.set_text("Średnie z próbek (n = 5)")
og_s2 = ax3.hist(sample_means_n40, alpha = .5)
ax3.title.set_text("Średnie z próbek (n = 40)")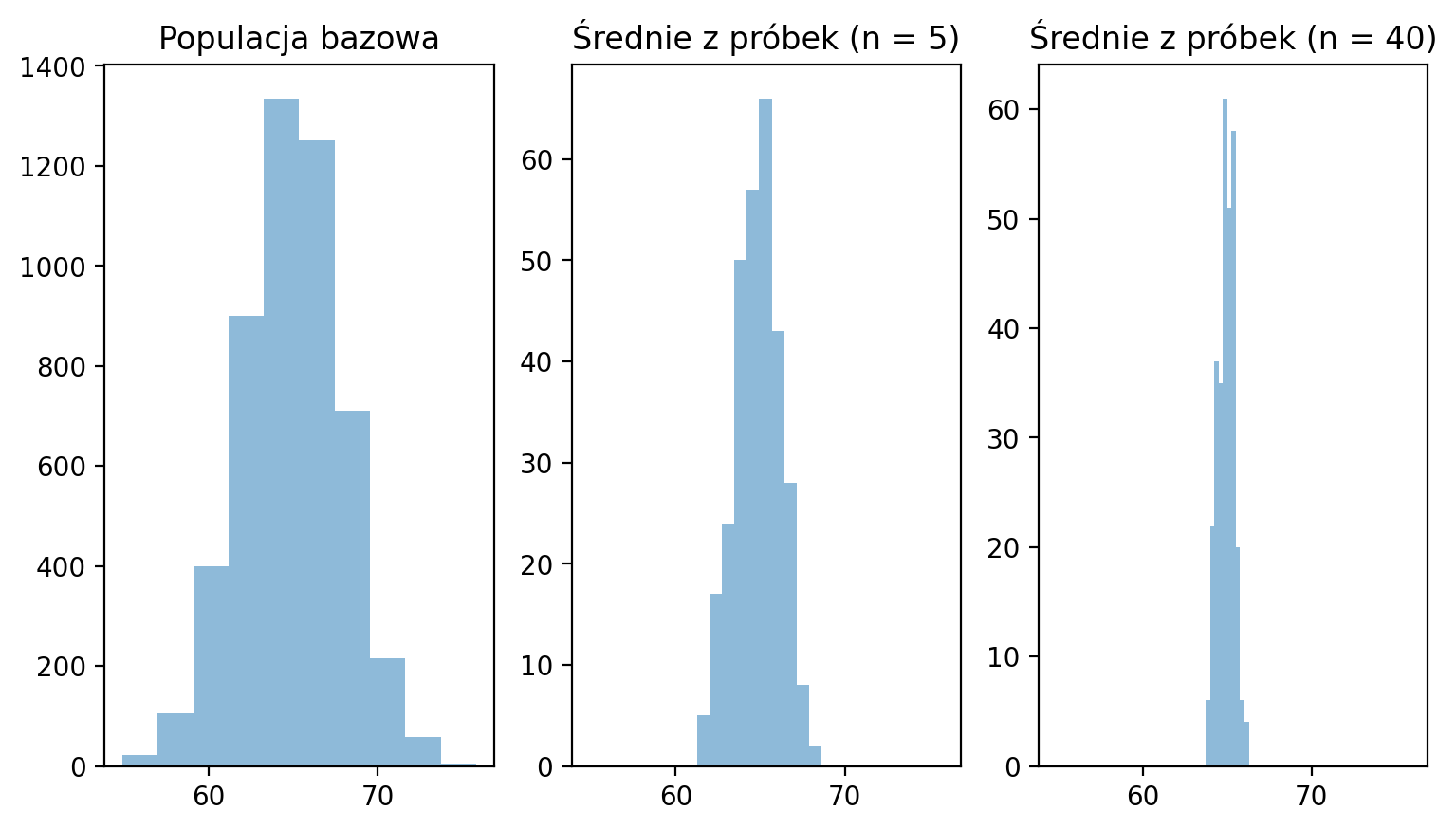
Dlaczego ma znaczenie (powtórka)¶
Wraz ze wzrostem wartości :
Rozkład próby staje się coraz bardziej normalny.
Wariancja naszego rozkładu próby maleje.
Jest to w istocie centralne twierdzenie graniczne.
Im większa próba, tym bardziej rozkład statystyki z próby zbliża się do rozkładu normalnego, nawet jeśli zmienna, którą mierzymy, nie posiada rozkładu normalnego.
Dotyczy to nawet rozkładów asymetrycznych!
Kwantyfikacja wariancji rozkładu próbkowego¶
Większa wartość powinna zwiększyć nasze przekonanie, że statystyka próbkowa jest dobrym przybliżeniem parametru populacyjnego.
Większa wartość oznacza mniejszą wariancję naszego rozkładu próbkowego.
To z kolei oznacza, że każda dana statystyka próbkowa jest stosunkowo bliska parametrowi populacyjnemu.
Jak możemy kwantyfikować wielkość wariancji w naszym hipotetycznym rozkładzie próbkowym?
Wprowadzenie pojęcia błędu standardowego¶
Błąd standardowy pozwala nam zmierzyć wariancję naszego rozkładu próbkowego.
Błąd standardowy (SE) definiuje się jako:
Gdzie jest odchyleniem standardowym próby.
Pytanie 3.¶
Czym różni się błąd standardowy od odchylenia standardowego?
Błąd standardowy zależy od ¶
Odchylenie standardowe jest niezmienne względem wielkości naszej próby.
Błąd standardowy maleje wraz ze wzrostem wielkości próby ().
SE odzwierciedla zarówno odchylenie standardowe, jak i .
Ns = np.linspace(1, 100, num = 100)
for sigma in [10, 20, 30, 40]:
se = sigma / np.sqrt(Ns)
plt.plot(Ns, se, label = r"$\sigma$ = {x}".format(x=sigma)) # Dodaj 'r' przed stringiem
plt.legend();
plt.xlabel("N");
plt.ylabel("Błąd standardowy");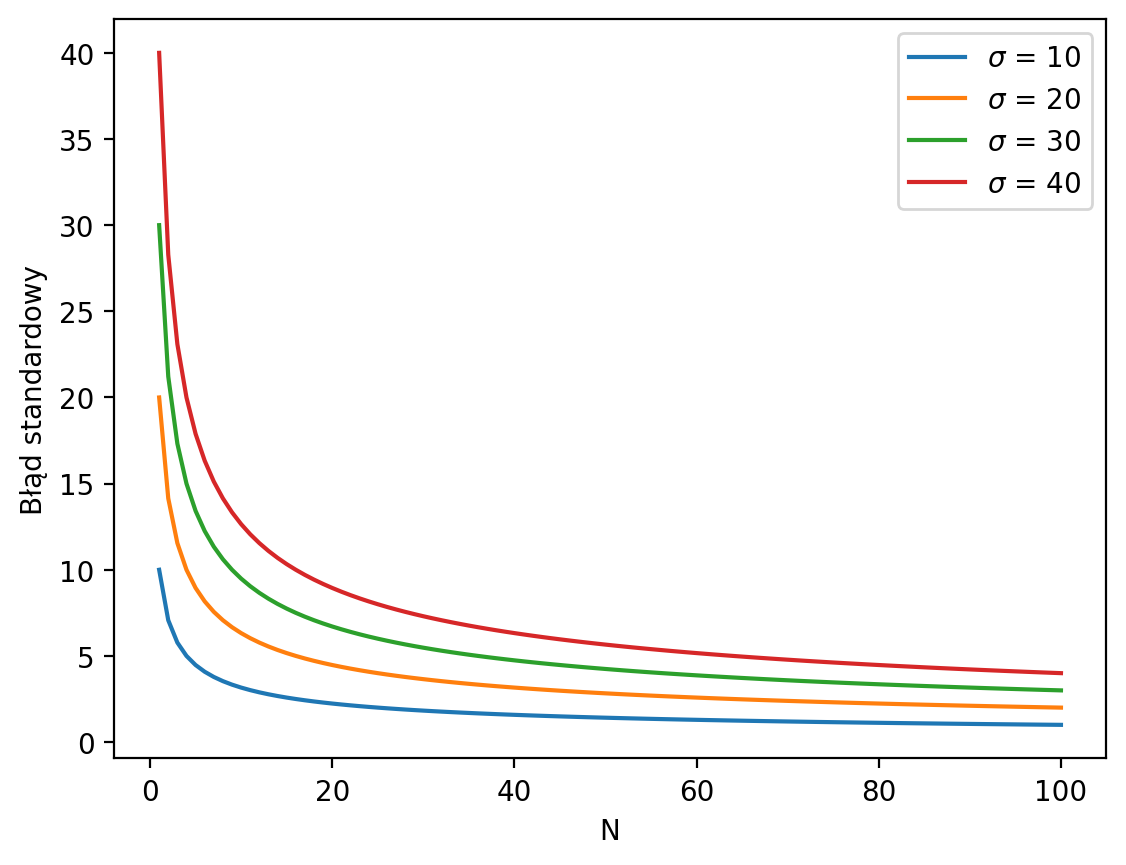
Obliczanie SE za pomocą pandas¶
pandas udostępnia funkcję (sem) do obliczania błędu standardowego średniej (SE) bezpośrednio w kolumnie.
df_height = pd.read_csv("data/wrangling/height.csv")
df_height['Father'].sem()np.float64(0.08363032857029366)Raportowanie błędu standardowego¶
Powszechną metodą wykorzystania błędu standardowego jest raportowanie go wraz ze średnią z próby:
Średnia z naszej próby wyniosła 25 USD, ± 3,5 (SE).
Symbol „±” oznacza po prostu pewną niepewność dotyczącą naszej statystyki próby.
## Koncepcja samplingu
exec(open('sampling_srednie.py').read())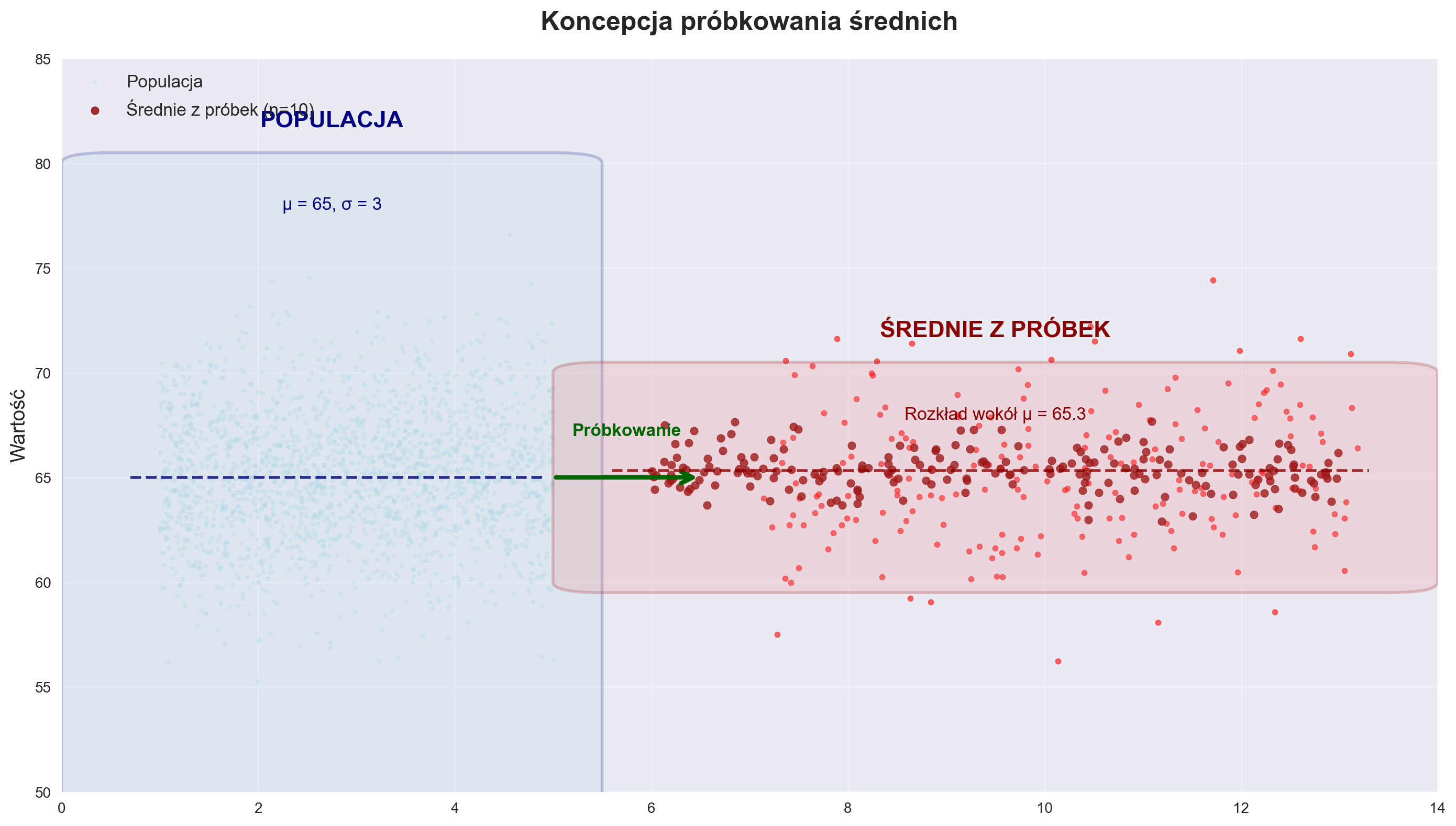
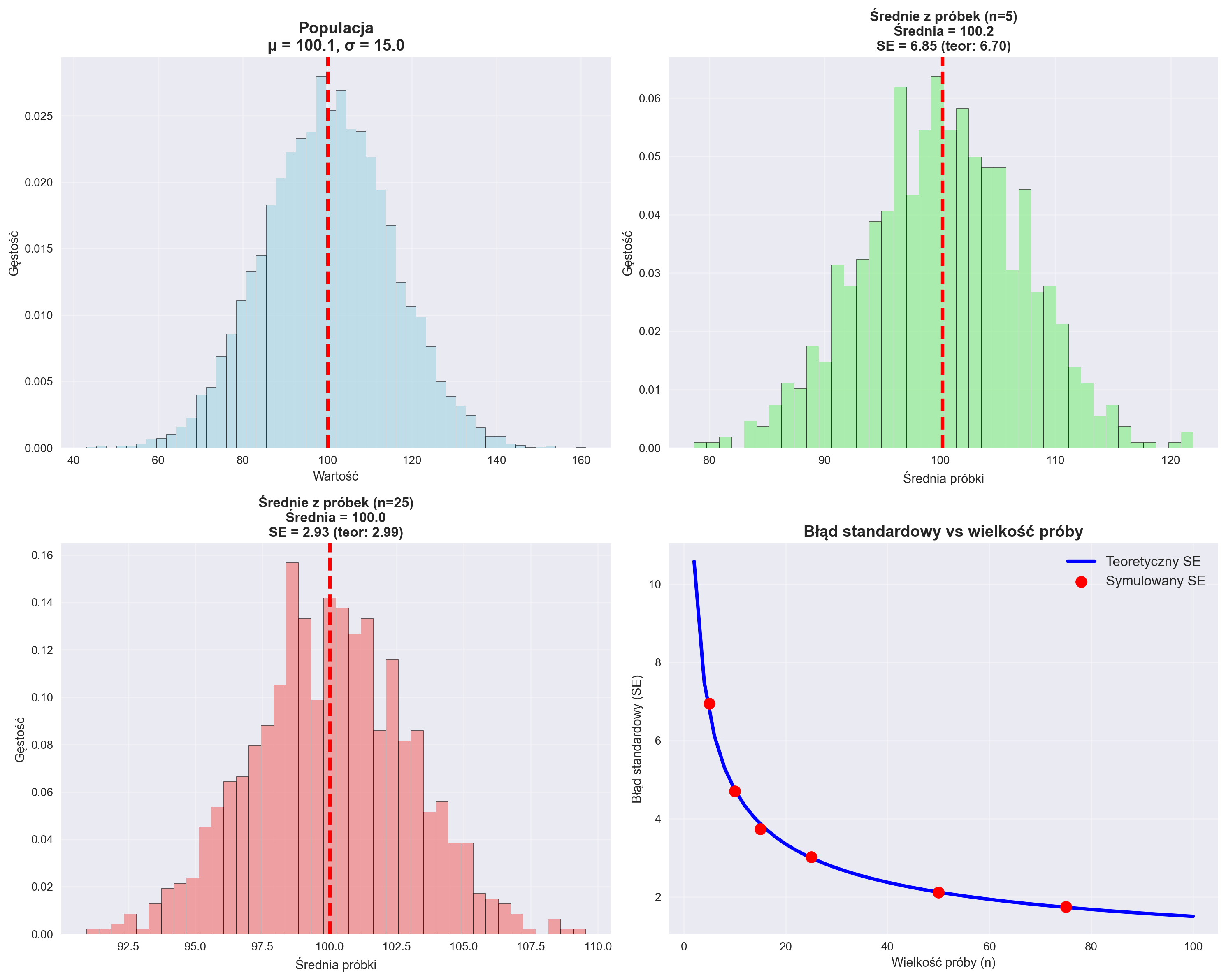

============================================================
PODSUMOWANIE SYMULACJI PRÓBKOWANIA ŚREDNICH
============================================================
Populacja: μ = 100.15, σ = 14.97
Liczba symulacji: 1000 dla każdej wielkości próby
WYNIKI:
n=5: Średnia próbkowa = 100.21, SE = 6.85
n=25: Średnia próbkowa = 100.02, SE = 2.93
WERYFIKACJA WZORU SE = σ/√n:
n=5: SE teoretyczny = 6.70, SE empiryczny = 6.85
n=25: SE teoretyczny = 2.99, SE empiryczny = 2.93
Stosunek SE: 2.34 (teoretyczny: 2.24)
Podsumowanie - średnia z próby¶
To kończy nasze krótkie wprowadzenie do statystyki matematycznej.
Jego celem było przede wszystkim przedstawienie kilku kluczowych pojęć:
Błąd próby: statystyka próby ≠ parametr populacji.
Rozkłady próby: rozkład wszystkich statystyk próby z prób o wielkości .
Błąd standardowy: kwantyfikacja wariancji w naszym rozkładzie próby.
Wszystkie te pojęcia pomogą w przyszłych dyskusjach na temat modelowania statystycznego.
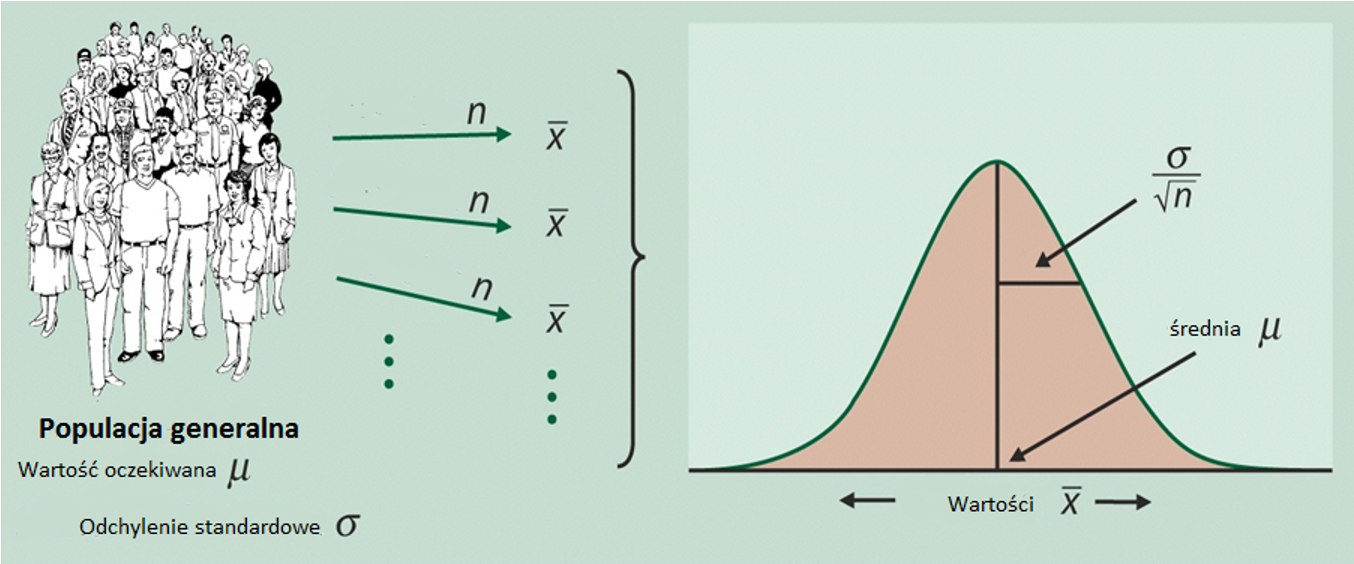
Rozkład normalny - teoria w kontekście Symulacji 1.¶
Definicja rozkładu normalnego¶
Rozkład normalny (zwany także rozkładem Gaussa) to jeden z najważniejszych rozkładów prawdopodobieństwa w statystyce. Jest to rozkład ciągły, który charakteryzuje się charakterystyczną krzywą w kształcie dzwonu.
Funkcja gęstości prawdopodobieństwa¶
Rozkład normalny opisuje wzór:
gdzie:
– średnia (parametr położenia)
– odchylenie standardowe (parametr skali)
– wariancja
Zapisujemy to jako:
Właściwości rozkładu normalnego¶
Symetryczność – krzywa jest symetryczna względem średniej
Kształt dzwonu – ma charakterystyczny kształt przypominający dzwon
Asymptoty – „ogony" krzywej zbliżają się do zera, ale nigdy jej nie osiągają
Reguła 68-95-99,7 (reguła trzech sigm):
obserwacji mieści się w przedziale
obserwacji mieści się w przedziale
obserwacji mieści się w przedziale
W kontekście Symulacji 1¶
W naszej symulacji:
Tworzymy populację z rozkładu normalnego: , czyli
Pobieramy z niej próbki i obliczamy ich średnie
Rozkład średnich z próbek również będzie normalny (zgodnie z CTG)
Centralne Twierdzenie Graniczne (CTG)¶
Najważniejsze twierdzenie w kontekście rozkładu normalnego:
Niezależnie od kształtu rozkładu populacji, rozkład średnich z próbek o wystarczająco dużej wielkości będzie zbliżony do rozkładu normalnego.
Matematycznie:
gdzie:
– średnia z próby
– średnia populacji
– wariancja rozkładu próby (maleje wraz ze wzrostem !)
Błąd standardowy średniej¶
Błąd standardowy średniej to odchylenie standardowe rozkładu próby średnich:
Standardowy rozkład normalny¶
Szczególny przypadek: – rozkład o średniej 0 i odchyleniu standardowym 1.
Standaryzacja:
Standaryzacja dla średniej z próby:
# Parametry rozkładu normalnego
mu = 0 # średnia
sigma = 1 # odchylenie standardowe
# Zakres wartości x
x = np.linspace(-4, 4, 1000)
y = stats.norm.pdf(x, mu, sigma)
# Tworzenie wykresu
fig, ax = plt.subplots(1, 1, figsize=(10, 6))
# Rysowanie krzywej gęstości
ax.plot(x, y, 'b-', linewidth=2, label=f'$\\mathcal{{N}}({mu}, {sigma}^2)$')
# Zakreskowanie obszarów zgodnie z regułą 68-95-99.7
# 68% - 1 sigma
x_1sigma = x[(x >= mu - sigma) & (x <= mu + sigma)]
y_1sigma = stats.norm.pdf(x_1sigma, mu, sigma)
ax.fill_between(x_1sigma, y_1sigma, alpha=0.3, color='green',
label='68% (±1σ)')
# 95% - 2 sigma
x_2sigma = x[(x >= mu - 2*sigma) & (x <= mu + 2*sigma)]
y_2sigma = stats.norm.pdf(x_2sigma, mu, sigma)
ax.fill_between(x_2sigma, y_2sigma, alpha=0.2, color='orange',
label='95% (±2σ)')
# 99.7% - 3 sigma
x_3sigma = x[(x >= mu - 3*sigma) & (x <= mu + 3*sigma)]
y_3sigma = stats.norm.pdf(x_3sigma, mu, sigma)
ax.fill_between(x_3sigma, y_3sigma, alpha=0.1, color='red',
label='99.7% (±3σ)')
# Dodanie linii pionowych dla σ
for i in range(1, 4):
ax.axvline(mu + i*sigma, color='gray', linestyle='--', alpha=0.7)
ax.axvline(mu - i*sigma, color='gray', linestyle='--', alpha=0.7)
ax.text(mu + i*sigma, 0.02, f'+{i}σ', ha='center', va='bottom')
ax.text(mu - i*sigma, 0.02, f'-{i}σ', ha='center', va='bottom')
# Dodanie linii dla średniej
ax.axvline(mu, color='black', linestyle='-', linewidth=2, alpha=0.8)
ax.text(mu, 0.42, 'μ = 0', ha='center', va='bottom', fontsize=12, fontweight='bold')
# Formatowanie wykresu
ax.set_xlabel('Wartość zmiennej (x)', fontsize=12)
ax.set_ylabel('Gęstość prawdopodobieństwa f(x)', fontsize=12)
ax.set_title('Rozkład normalny $\\mathcal{N}(0, 1)$ z regułą 68-95-99.7', fontsize=14, fontweight='bold')
ax.legend(loc='upper right')
ax.grid(True, alpha=0.3)
ax.set_ylim(0, 0.45)
plt.tight_layout()
plt.show()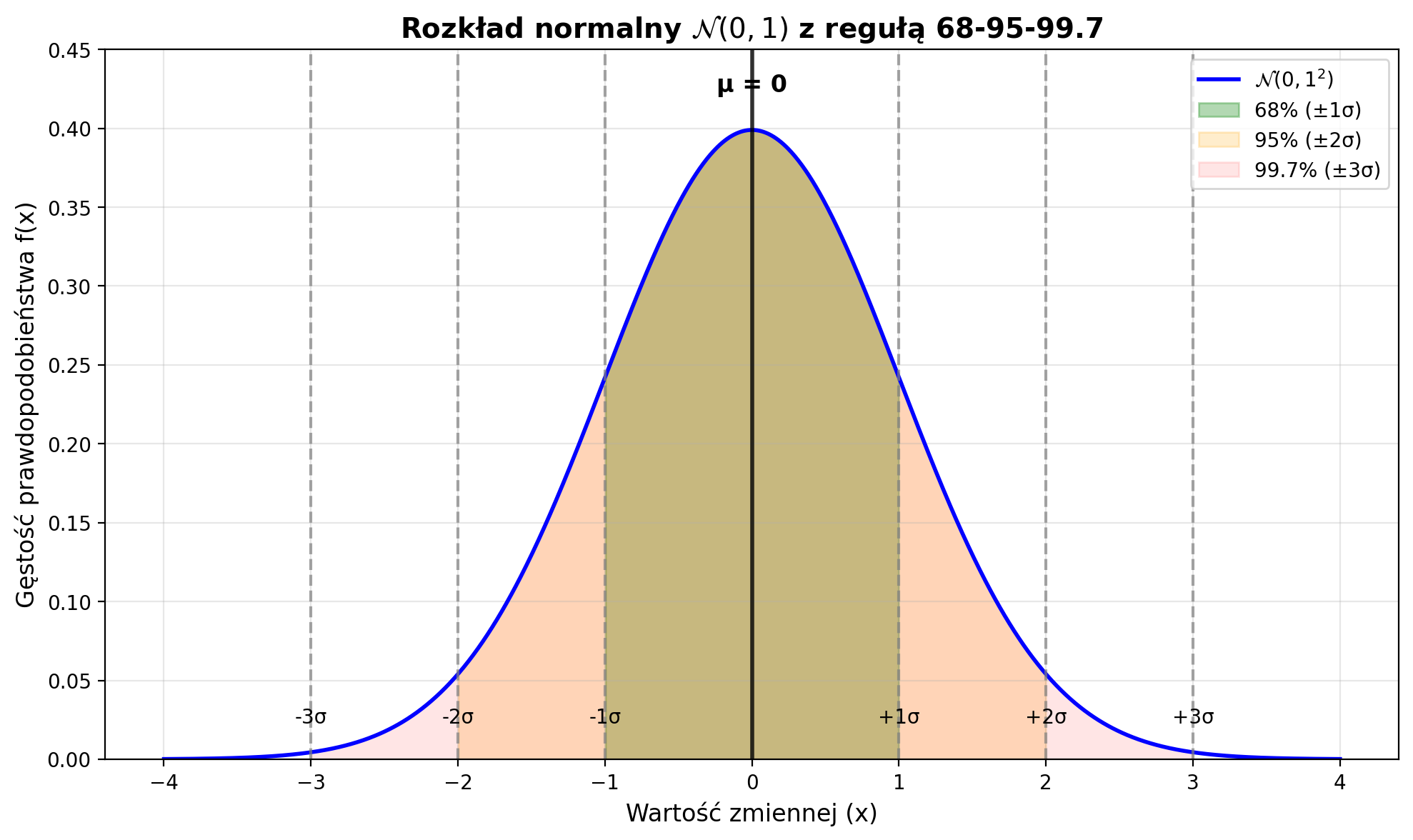
Rozkład t-Studenta¶
Rozkład t-Studenta (zwany także rozkładem Studenta) to jeden z najważniejszych rozkładów w statystyce praktycznej, szczególnie gdy nie znamy prawdziwego odchylenia standardowego populacji.
Dlaczego potrzebujemy rozkładu t-Studenta?¶
W praktyce rzadko znamy prawdziwe odchylenie standardowe populacji . Zamiast tego musimy je estymować z próby używając (odchylenie standardowe próby).
Problem z rozkładem normalnym: Gdy używamy szacunku zamiast prawdziwego , statystyka:
nie ma już rozkładu normalnego !
Definicja rozkładu t-Studenta¶
Gdy populacja ma rozkład normalny, a jest odchyleniem standardowym z próby, to:
ma rozkład t-Studenta z stopniami swobody.
Funkcja gęstości prawdopodobieństwa¶
gdzie:
– liczba stopni swobody
– funkcja gamma
Właściwości rozkładu t-Studenta¶
Symetryczny względem zera (podobnie jak rozkład normalny)
Grubsze ogony niż rozkład normalny (większe prawdopodobieństwo wartości ekstremalnych)
Kształt zależy od stopni swobody
Zbieżność do rozkładu normalnego: gdy , rozkład
Parametry rozkładu¶
Średnia: (dla )
Wariancja: (dla )
Odchylenie standardowe:
Zastosowania w praktyce¶
Rozkład t-Studenta używamy gdy:
Nie znamy prawdziwego odchylenia standardowego populacji
Próba jest względnie mała (zwykle )
Chcemy konstruować przedziały ufności dla średniej
Przeprowadzamy testy t-Studenta
Przykładowy przedział ufności dla średniej:
gdzie to wartość krytyczna z rozkładu t-Studenta.
Stopnie swobody w rozkładzie t-Studenta¶
Co to są stopnie swobody?¶
Stopnie swobody (degrees of freedom, df) to kluczowe pojęcie w statystyce, które określa liczbę niezależnych informacji dostępnych do oszacowania parametru statystycznego.
Definicja matematyczna¶
Stopnie swobody to liczba obserwacji w próbie minus liczba parametrów, które musimy oszacować z tej próby.
W przypadku średniej z próby:
gdzie:
– wielkość próby
1 – liczba oszacowanych parametrów (średnia )
Dlaczego odejmujemy 1?¶
Gdy obliczamy odchylenie standardowe próby , używamy wzoru:
Kluczowa obserwacja:
Mamy obserwacji:
Ale gdy znamy średnią oraz odchyleń od średniej, to ostatnie odchylenie jest automatycznie określone!
Przykład intuicyjny¶
Wyobraź sobie próbę z obserwacjami: .
Jeśli wiemy, że:
To automatycznie , ponieważ suma odchyleń od średniej musi wynosić zero:
Wpływ na rozkład t-Studenta¶
Im mniejsze stopnie swobody:
Tym grubsze ogony ma rozkład t-Studenta
Tym większa niepewność w naszych oszacowaniach
Tym bardziej ostrożni musimy być w wnioskach
Matematycznie:
Praktyczne znaczenie¶
| Wielkość próby () | Stopnie swobody () | Charakterystyka rozkładu |
|---|---|---|
| Bardzo grube ogony, duża niepewność | ||
| Zauważalnie grubsze ogony niż normalny | ||
| Bardzo blisko rozkładu normalnego | ||
| Identyczny z rozkładem normalnym |
Dlaczego to ważne?¶
Przedziały ufności są szersze dla małych
Wartości krytyczne są większe dla małych
Testy statystyczne są bardziej konserwatywne dla małych
Przykład wartości krytycznych:
Dla :
Dla :
Dla rozkładu normalnego:
Wniosek: Im mniejsza próba, tym więcej “zapasu bezpieczeństwa” potrzebujemy w naszych wnioskach!
Wzór ogólny dla stopni swobody¶
W różnych kontekstach statystycznych:
gdzie:
– liczba obserwacji
– liczba oszacowanych parametrów
Przykłady:
Średnia z próby: (oszacowujemy )
Regresja liniowa: (oszacowujemy współczynników + wyraz wolny)
Test chi-kwadrat: (w tabeli kontyngencji)
# Porównanie rozkładu normalnego z rozkładem t-Studenta
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
# Parametry
x = np.linspace(-4, 4, 1000)
# Rozkład normalny standardowy
y_normal = stats.norm.pdf(x, 0, 1)
# Rozkłady t-Studenta z różnymi stopniami swobody
y_t1 = stats.t.pdf(x, df=1)
y_t3 = stats.t.pdf(x, df=3)
y_t10 = stats.t.pdf(x, df=10)
y_t30 = stats.t.pdf(x, df=30)
# Tworzenie wykresu
fig, ax = plt.subplots(1, 1, figsize=(12, 8))
# Rysowanie krzywych
ax.plot(x, y_normal, 'k-', linewidth=2, label='$\\mathcal{N}(0,1)$ (rozkład normalny)')
ax.plot(x, y_t1, 'r--', linewidth=2, label='$t_1$ (df = 1)')
ax.plot(x, y_t3, 'b--', linewidth=2, label='$t_3$ (df = 3)')
ax.plot(x, y_t10, 'g--', linewidth=2, label='$t_{10}$ (df = 10)')
ax.plot(x, y_t30, 'm--', linewidth=2, label='$t_{30}$ (df = 30)')
# Zakreskowanie obszaru dla ilustracji grubszych ogonów
x_tail = x[x >= 2]
y_normal_tail = stats.norm.pdf(x_tail, 0, 1)
y_t3_tail = stats.t.pdf(x_tail, df=3)
ax.fill_between(x_tail, 0, y_normal_tail, alpha=0.3, color='gray',
label='Ogon rozkładu normalnego')
ax.fill_between(x_tail, 0, y_t3_tail, alpha=0.3, color='blue',
label='Ogon rozkładu t (df=3)')
# Dodanie linii pionowych
ax.axvline(0, color='black', linestyle='-', alpha=0.3)
ax.axvline(2, color='red', linestyle=':', alpha=0.7)
ax.axvline(-2, color='red', linestyle=':', alpha=0.7)
# Annotacje
ax.annotate('Grubsze ogony\nw rozkładzie t',
xy=(2.5, 0.02), xytext=(3, 0.15),
arrowprops=dict(arrowstyle='->', color='red'),
fontsize=10, ha='center')
# Formatowanie wykresu
ax.set_xlabel('Wartość zmiennej', fontsize=12)
ax.set_ylabel('Gęstość prawdopodobieństwa', fontsize=12)
ax.set_title('Porównanie rozkładu normalnego z rozkładem t-Studenta', fontsize=14, fontweight='bold')
ax.legend(loc='upper right')
ax.grid(True, alpha=0.3)
ax.set_ylim(0, 0.4)
plt.tight_layout()
plt.show()
# Tabela porównawcza wariancji
print("Porównanie wariancji:")
print("Rozkład normalny N(0,1): σ² = 1.000")
for df in [1, 2, 3, 5, 10, 30]:
if df > 2:
var_t = df / (df - 2)
print(f"Rozkład t-Studenta (df={df}): σ² = {var_t:.3f}")
else:
print(f"Rozkład t-Studenta (df={df}): σ² = nieskończona")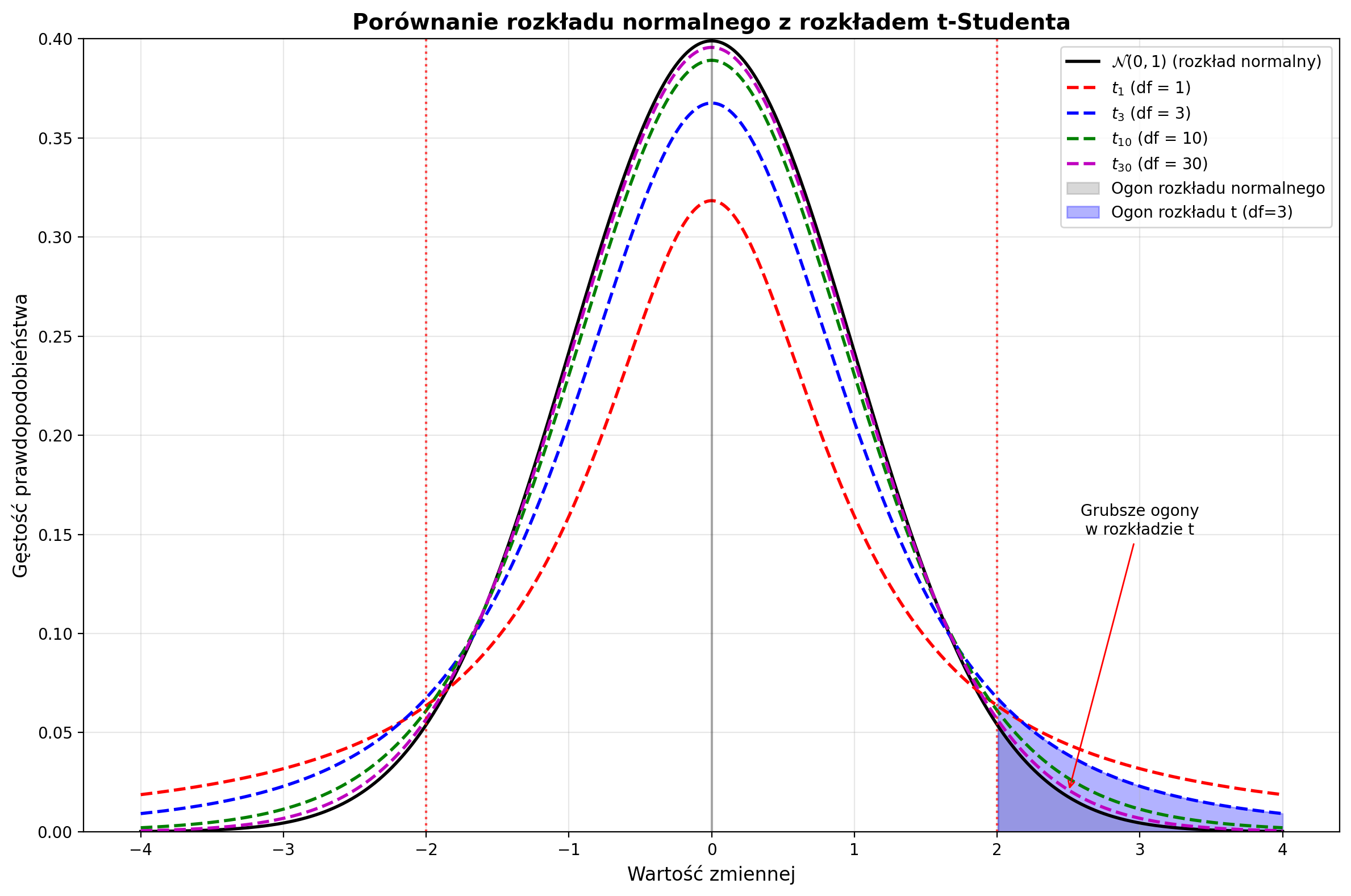
Porównanie wariancji:
Rozkład normalny N(0,1): σ² = 1.000
Rozkład t-Studenta (df=1): σ² = nieskończona
Rozkład t-Studenta (df=2): σ² = nieskończona
Rozkład t-Studenta (df=3): σ² = 3.000
Rozkład t-Studenta (df=5): σ² = 1.667
Rozkład t-Studenta (df=10): σ² = 1.250
Rozkład t-Studenta (df=30): σ² = 1.071
Proporcja z próby¶
Symulacja 2.¶
Załóżmy, że koszykarz wykonuje 10 rzutów (n=10) i trafia z prawdopodobieństwem 0,4 (prawdopodobieństwo sukcesu p=0,4).
Jeśli ten koszykarz wykona to ćwiczenie raz, możemy obliczyć liczbę sukcesów w następujący sposób
Rozkład dwumianowy w Symulacji 2.¶
W Symulacji 2. analizujemy klasyczny przykład rozkładu dwumianowego (ang. binomial distribution), który modeluje liczbę sukcesów w sekwencji niezależnych prób Bernoulliego.
Definicja i wzór¶
Rozkład dwumianowy opisuje prawdopodobieństwo uzyskania dokładnie sukcesów w niezależnych próbach, gdzie każda próba ma prawdopodobieństwo sukcesu równe .
Funkcja masy prawdopodobieństwa:
gdzie:
– zmienna losowa oznaczająca liczbę sukcesów
– liczba rzutów (prób)
– konkretna liczba trafień
– prawdopodobieństwo trafienia w pojedynczym rzucie
– współczynnik dwumianowy
Parametry rozkładu¶
Dla rozkładu dwumianowego :
Wartość oczekiwana:
Wariancja:
Odchylenie standardowe:
# Generuje losowe dwumianowe próbki
scoring_success_1 = np.random.binomial(n=10, p=0.4, size=1)
prob_1 = scoring_success_1 / 10# Dziennie
scoring_success_10 = np.random.binomial(n=10, p=0.4, size=10)
prob_10 = scoring_success_10 / 10# Tygodniowo
scoring_success_50 = np.random.binomial(n=10, p=0.4, size=50)
prob_50 = scoring_success_50 / 10# Miesięcznie
scoring_success_200 = np.random.binomial(n=10, p=0.4, size=200)
prob_200 = scoring_success_200 / 10# Rocznie
scoring_success_2600 = np.random.binomial(n=10, p=0.4, size=2600)
prob_2600 = scoring_success_2600 / 10# Rysujemy histogramy
fig, axs = plt.subplots(4, 1, figsize=(10, 20))
axs[0].hist(prob_10, bins=5, edgecolor='k', alpha=0.7)
axs[0].set_title('Dzienne prawdopodobieństwo sukcesu')
axs[0].set_xlabel('Proporcja z próby')
axs[0].set_ylabel('Liczebność')
axs[1].hist(prob_50, bins=10, edgecolor='k', alpha=0.7)
axs[1].set_title('Tygodniowe prawdopodobieństwo sukcesu')
axs[1].set_xlabel('Proporcja z próby')
axs[1].set_ylabel('Liczebność')
axs[2].hist(prob_200, bins=10, edgecolor='k', alpha=0.7)
axs[2].set_title('Miesięczne prawdopodobieństwo sukcesu')
axs[2].set_xlabel('Proporcja z próby')
axs[2].set_ylabel('Liczebność')
axs[3].hist(prob_2600, bins=10, edgecolor='k', alpha=0.7)
axs[3].set_title('Roczne prawdopodobieństwo sukcesu')
axs[3].set_xlabel('Proporcja z próby')
axs[3].set_ylabel('Liczebność')
plt.tight_layout()
plt.show()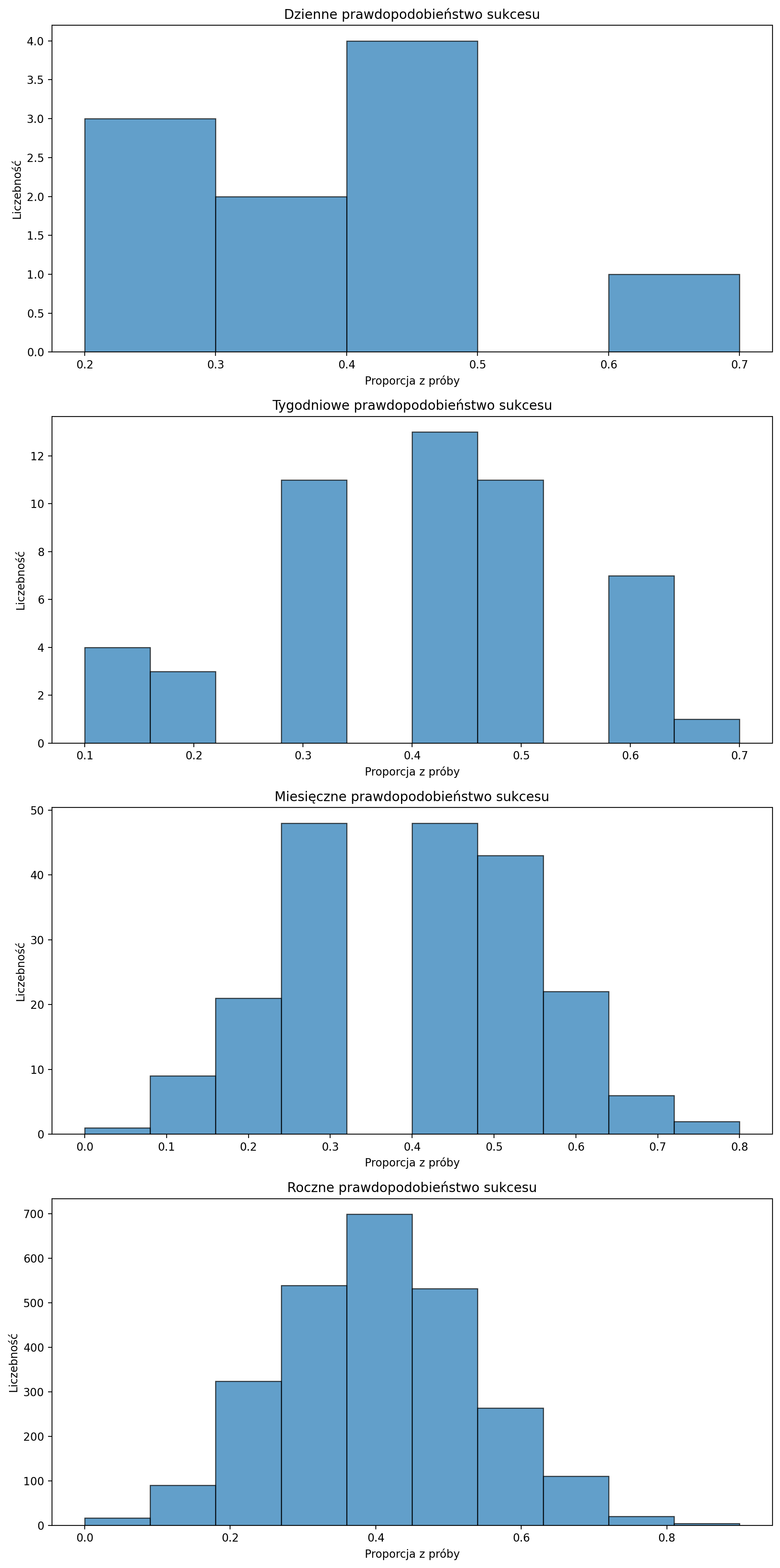
Proporcja z próby¶
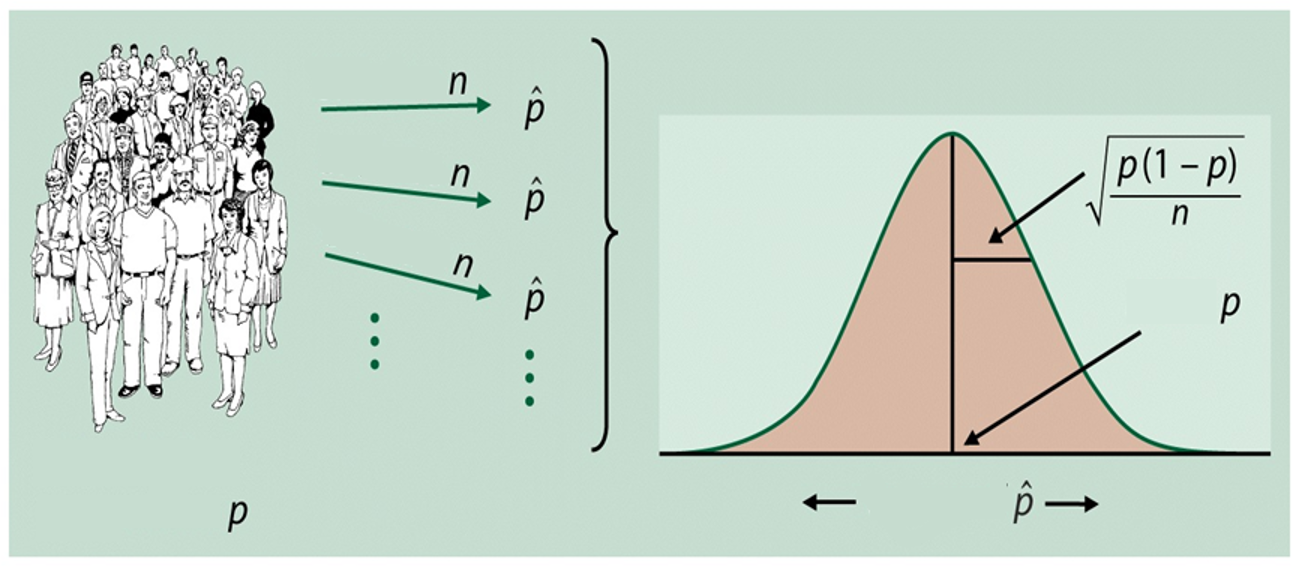
W symulacji obliczamy proporcję sukcesów:
gdzie jest estymatorem prawdziwego prawdopodobieństwa .
Centralne Twierdzenie Graniczne dla proporcji¶
Gdy liczba niezależnych eksperymentów rośnie, rozkład proporcji zbliża się do rozkładu normalnego:
czyli:
Błąd standardowy proporcji:
To właśnie obserwujemy na histogramach – wraz ze wzrostem liczby symulacji rozkład proporcji staje się coraz bardziej normalny i skupiony wokół prawdziwej wartości .
Reguła 5¶
Przybliżenie normalne jest dokładne, gdy spełnione są warunki:
W naszym przypadku:
(nie spełnione)
(spełnione)
To właśnie obserwujemy na histogramach – wraz ze wzrostem liczby symulacji rozkład proporcji staje się coraz bardziej normalny i skupiony wokół prawdziwej wartości .
## Koncepcja samplingu - proporcje
exec(open('sampling_proporcje.py').read())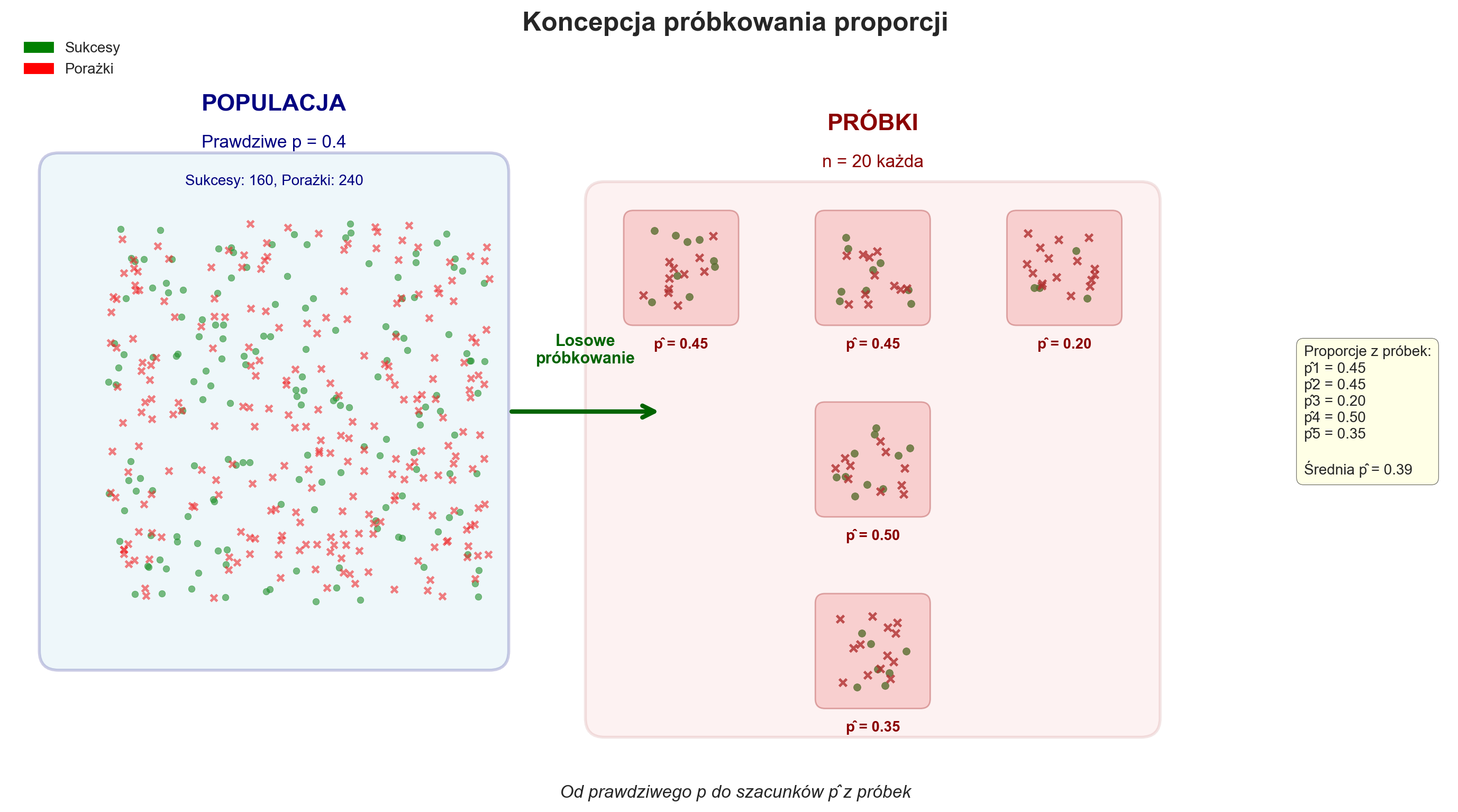
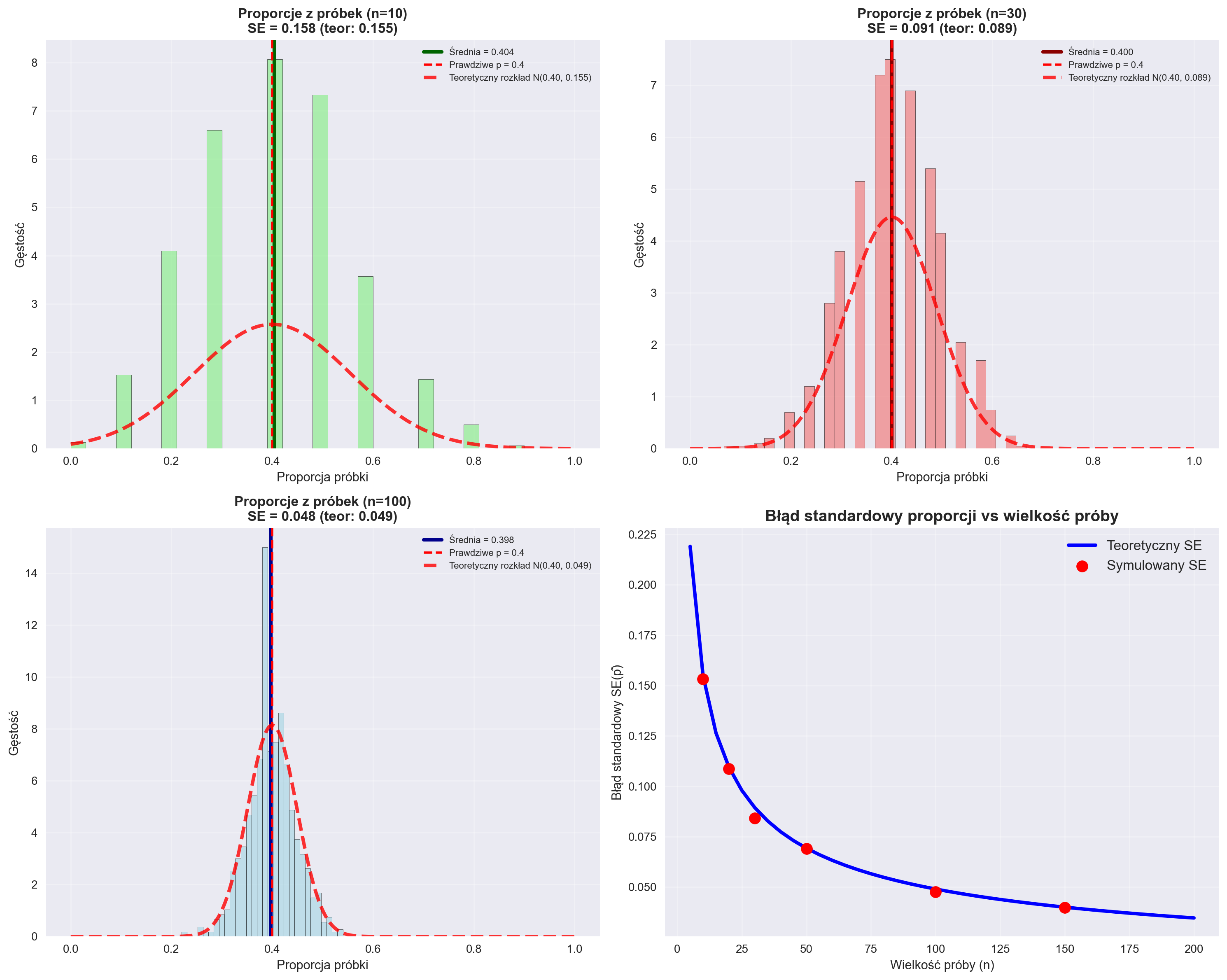

======================================================================
PODSUMOWANIE SYMULACJI PRÓBKOWANIA PROPORCJI
======================================================================
Prawdziwe p = 0.4
Liczba symulacji: 1000 dla każdej wielkości próby
WYNIKI:
n=10: Średnia p̂ = 0.404, SE = 0.158
n=30: Średnia p̂ = 0.400, SE = 0.091
n=100: Średnia p̂ = 0.398, SE = 0.048
WERYFIKACJA WZORU SE(p̂) = √[p(1-p)/n]:
n=10: SE teoretyczny = 0.155, SE empiryczny = 0.158
n=30: SE teoretyczny = 0.089, SE empiryczny = 0.091
n=100: SE teoretyczny = 0.049, SE empiryczny = 0.048
SPRAWDZENIE REGUŁY 5:
n=10: np = 4.0, n(1-p) = 6.0 → Reguła 5: ✗
n=30: np = 12.0, n(1-p) = 18.0 → Reguła 5: ✓
n=100: np = 40.0, n(1-p) = 60.0 → Reguła 5: ✓