W tym rozdziale¶
Wprowadzenie do
seaborn.Zastosowanie
seabornw praktyce:Wykresy jednowymiarowe (histogramy).
Dwuwymiarowe wykresy ciągłe (scatterplots i wykresy liniowe).
Dwuwymiarowe wykresy kategoryczne (wykresy słupkowe, wykresy pudełkowe i wykresy paskowe).
Wprowadzenie do seaborn¶
Czym jest seaborn?¶
seabornjest pakietem do wizualizacji danych opartym namatplotlib.
Ogólnie rzecz biorąc, łatwiej jest tworzyć ładnie wyglądające wykresy z
seaborn.Kompromisem jest to, że
matplotliboferuje większą elastyczność.
import seaborn as sns ### ładowanie seaborn
import pandas as pd
import matplotlib.pyplot as plt ## gdyby był potrzebny
import numpy as np%matplotlib inline
%config InlineBackend.figure_format = 'retina'Hierarchia typów wykresów w seaborn¶
W tym rozdziale (i w następnym) dowiemy się więcej o tym, co dokładnie oznacza ta hierarchia.
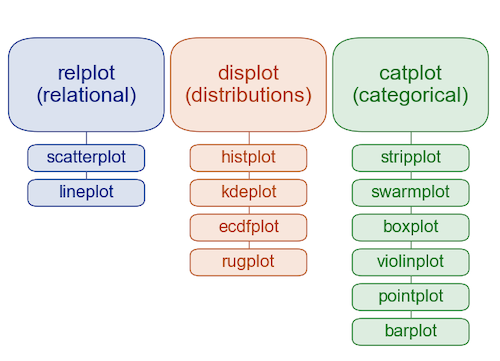
Przykładowe dane¶
Tutaj zaczerpniemy z Gapminder.
Gapminder to niezależna szwedzka fundacja zajmująca się publikowaniem i analizowaniem danych w celu korygowania błędnych przekonań na temat świata.
W latach 1952-2007 posiadała dane na temat
life_exp,gdp_capipopulation.
df_gapminder = pd.read_csv("data/viz/gapminder_full.csv")df_gapminder.head(2)df_gapminder.shape(1704, 6)Wykresy jednowymiarowe¶
Wykres jednowymiarowy jest wizualizacją tylko jednej zmiennej, tj. jej rozkładu.
Histogramy z sns.histplot¶
Poprzednio rysowaliśmy histogramy z
plt.hist.Z
seaborn, mozemy uzyćsns.histplot(...).
Zamiast df['col_name'], wykorzystujemy składnię:
sns.histplot(data = dane, x = nazwa_zmiennej)Stanie się to jeszcze bardziej przydatne, gdy zaczniemy tworzyć wykresy dwuwymiarowe.
# Histogram oczekiwanej długości zycia
sns.histplot(df_gapminder['life_exp']);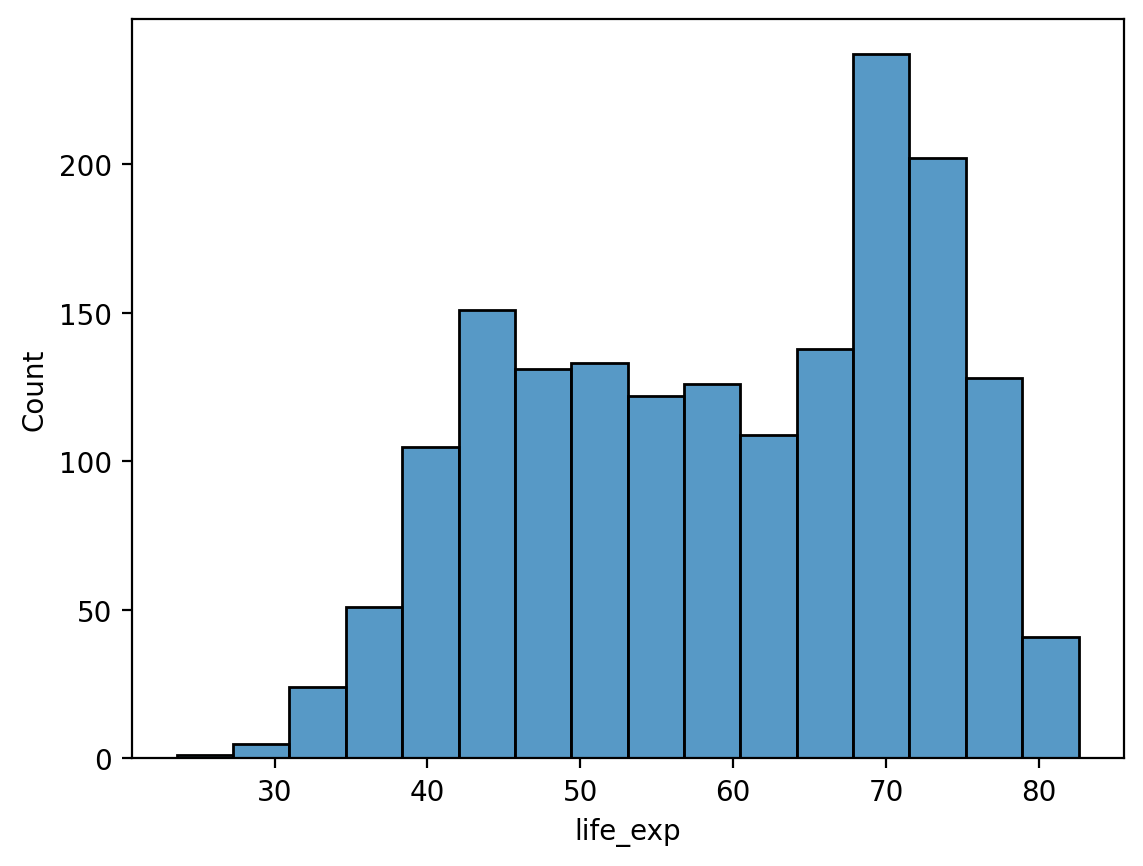
Modyfikowanie liczby przedziałów¶
Podobnie jak w przypadku plt.hist, możemy modyfikować liczbę przedziałów.
# Mniej przedziałów
sns.histplot(data = df_gapminder, x = 'life_exp', bins = 10, alpha = .6);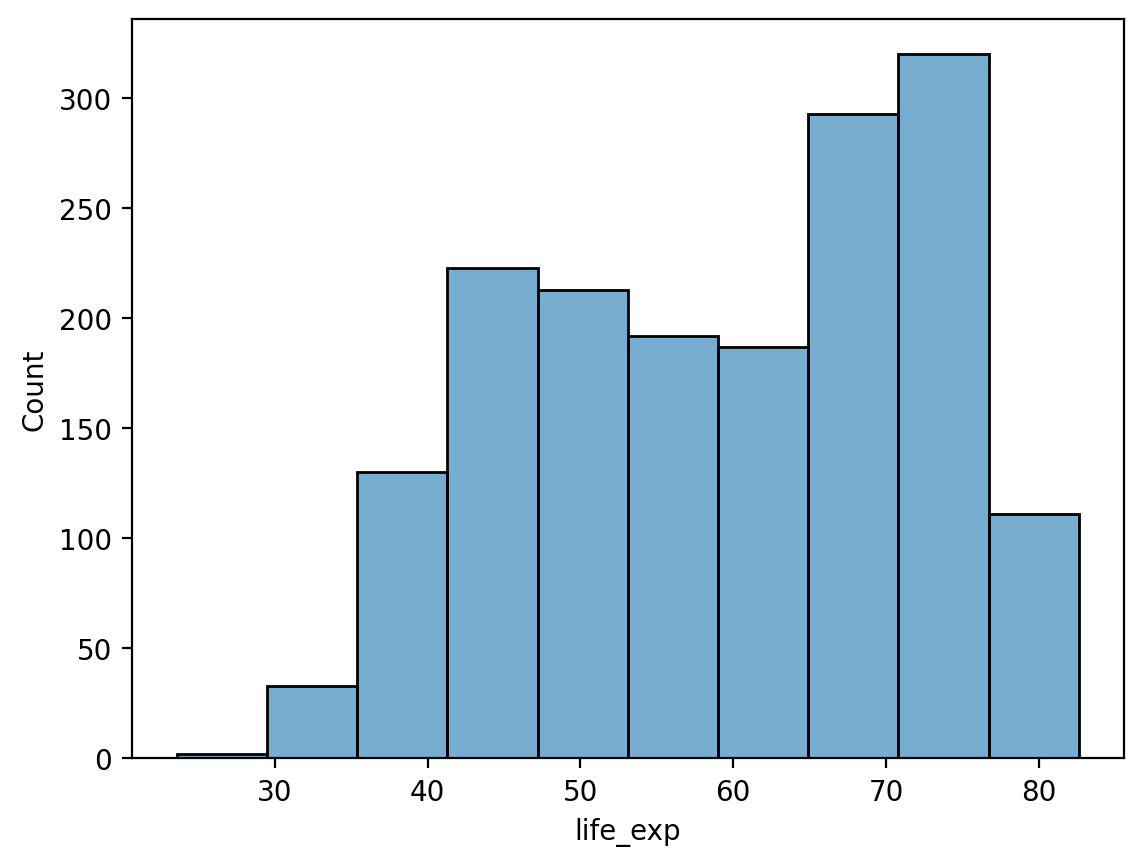
# Więcej przedziałów!
sns.histplot(data = df_gapminder, x = 'life_exp', bins = 100, alpha = .6);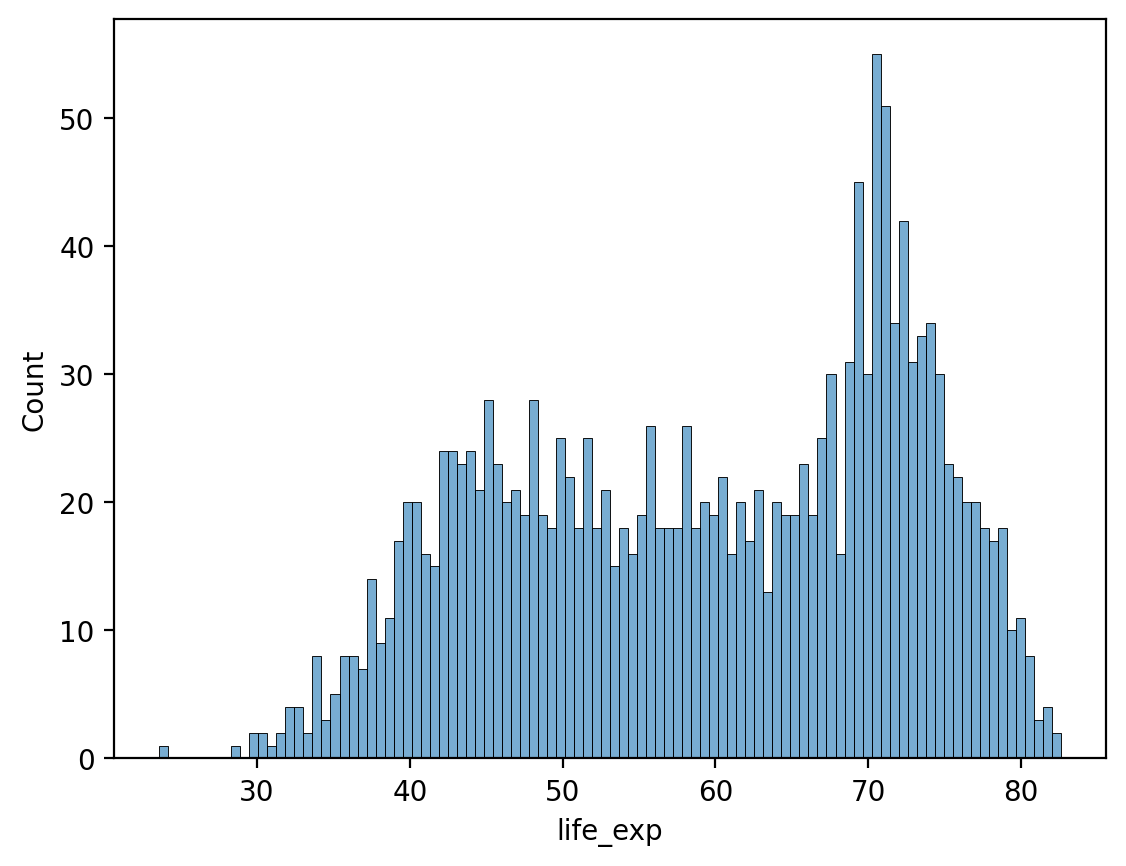
Modyfikacje osi-y z stat¶
Domyślnie, sns.histplot wykreśli liczebność każdej kategorii. Możemy to jednak zmienić za pomocą parametru stat:
probability: normalizuje tak, że wysokości słupków sumują się do1.percent: normalizuje tak, że wysokości słupków sumują się do100.density: normalizuje tak, że całkowita area sumuje się do1.
# Zwróć uwagę na zmodyfikowaną oś y!
sns.histplot(data = df_gapminder, x = 'life_exp', stat = "probability", alpha = .6);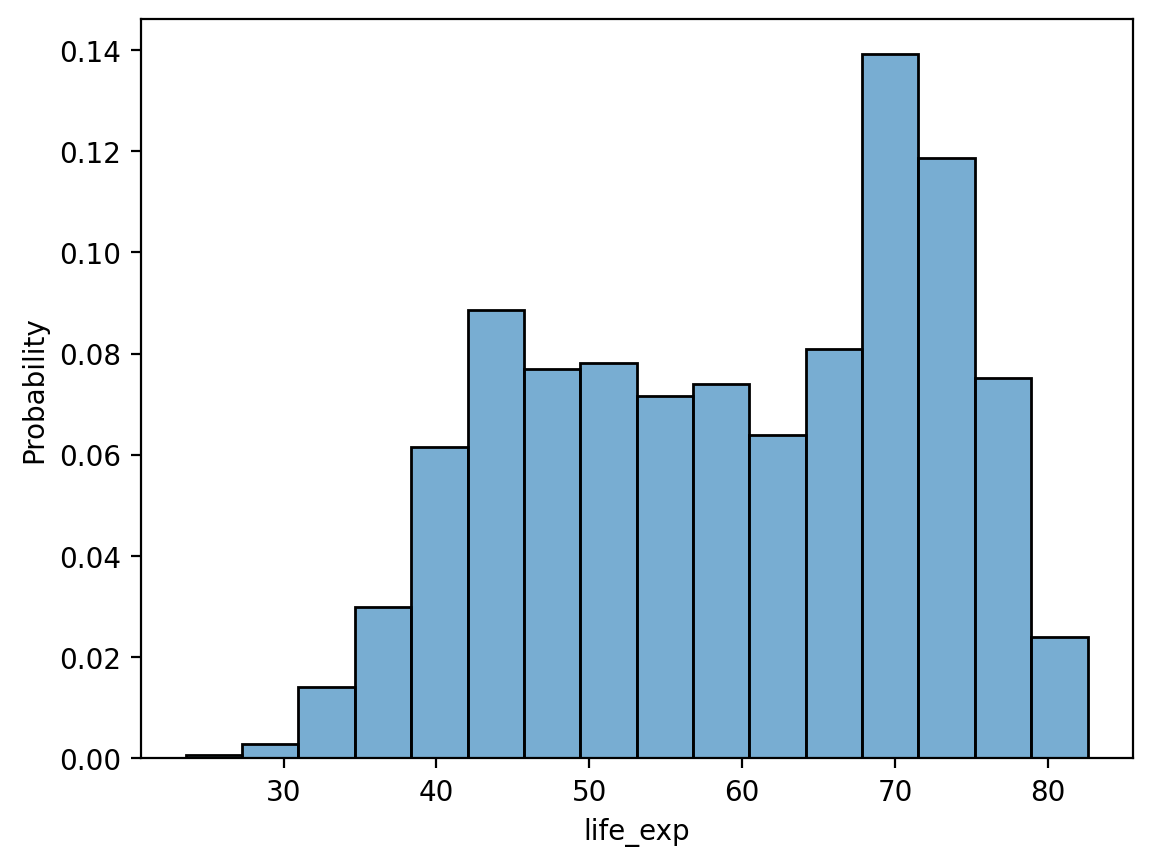
Sprawdź się!¶
Jak stworzyć histogram pokazujący rozkład wartości population w samym roku 2007?
Zmodyfikuj ten wykres, aby pokazywał „prawdopodobieństwo”, a nie „liczbę”.
Co widzimy na tym wykresie i jak mógł(a)byś go zmienić?
### Twój kod tutajCiągłe wykresy dwuwymiarowe¶
Wykres zmiennych ciągłych wizualizuje związek między dwoma zmiennymi ciągłymi.
Wykresy rozrzutu z sns.scatterplot¶
Wykres rozrzutu wizualizuje związek między dwiema zmiennymi ciągłymi.
Każda obserwacja jest wykreślana jako pojedyncza kropka/znak.
Pozycja na osiach
(x, y)odzwierciedla wartość tych zmiennych.
Jednym ze sposobów utworzenia scatterplot w seaborn jest użycie sns.scatterplot.
Zależność gdp_cap z life_exp¶
Czego dowiadujemy się o zmiennej gdp_cap?
sns.scatterplot(data = df_gapminder, x = 'gdp_cap', y = 'life_exp', alpha = .3);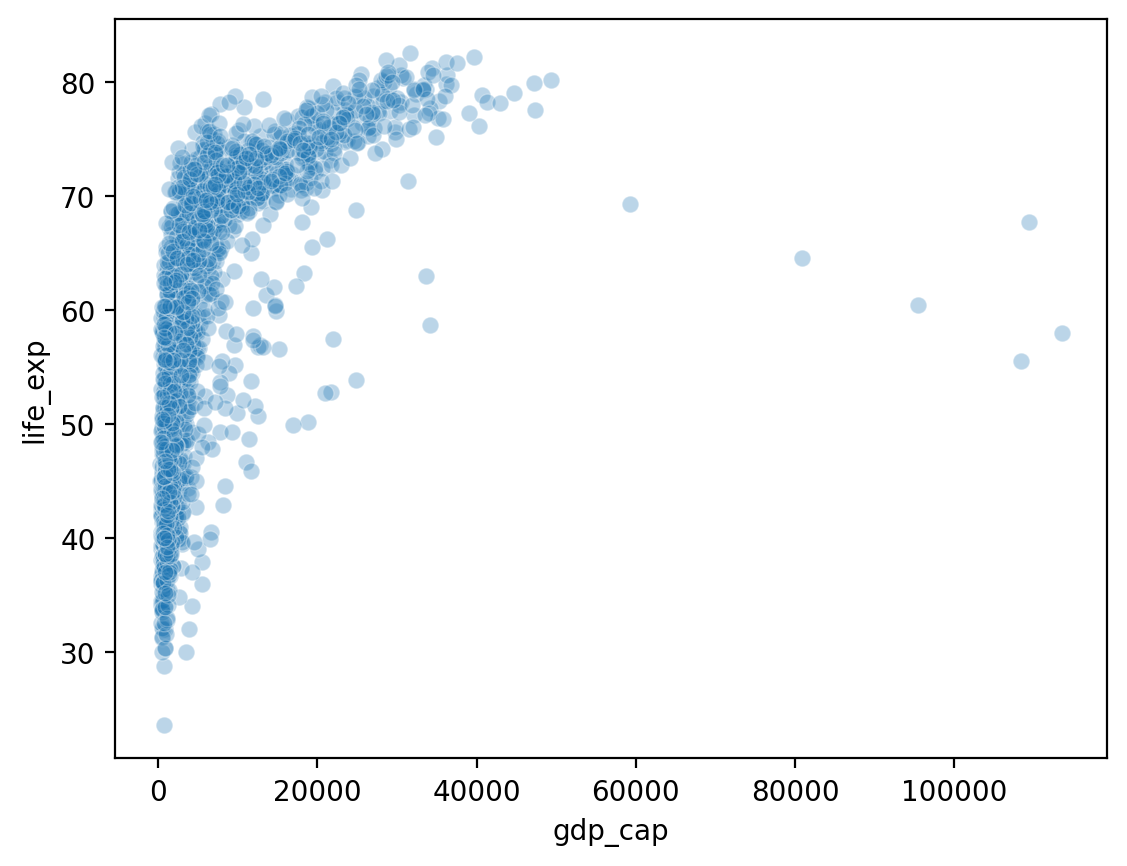
Zależność gdp_cap_log z life_exp¶
## Obliczamy i zapisujemy zmienną Log GDP
df_gapminder['gdp_cap_log'] = np.log10(df_gapminder['gdp_cap'])
## Pokaż log GDP z life exp
sns.scatterplot(data = df_gapminder, x = 'gdp_cap_log', y = 'life_exp', alpha = .3);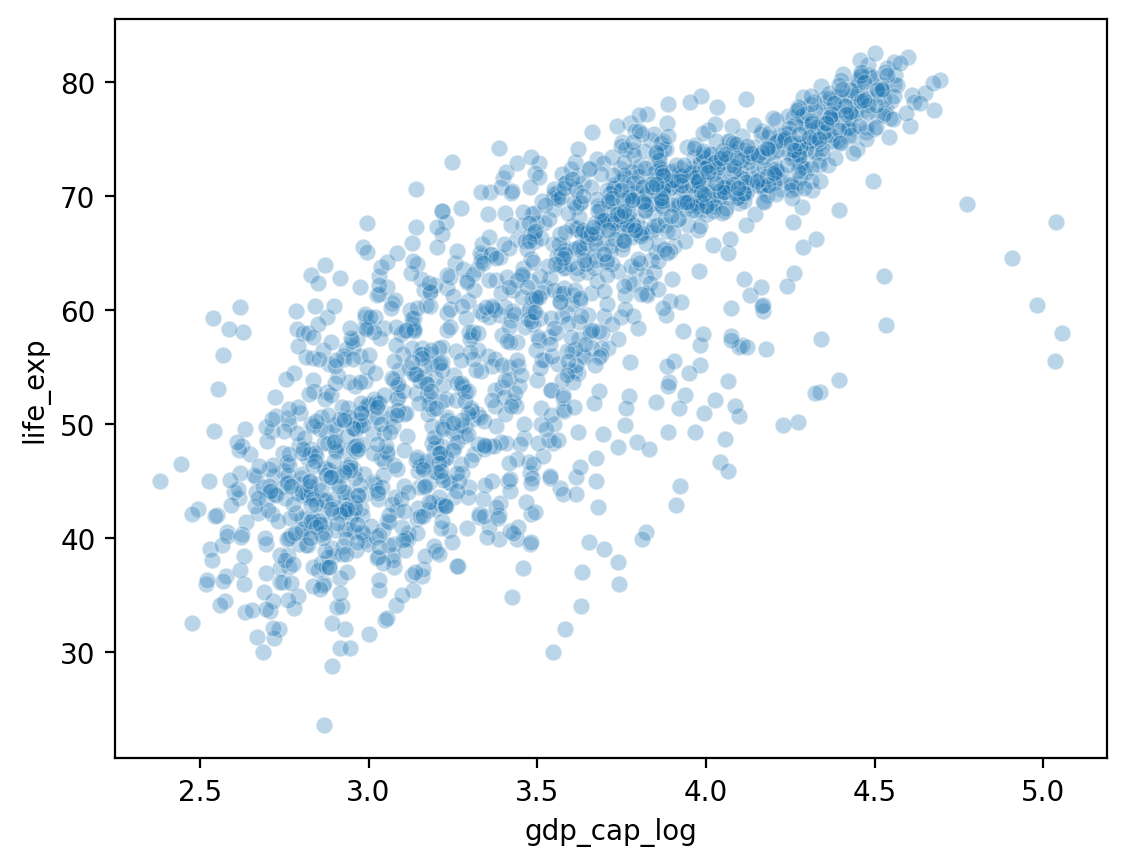
Dodajemy hue - odcień¶
Co jeśli chcemy dodać trzeci komponent, który jest kategoryczny, jak
continent?seabornpozwala nam to zrobić zhue- dodać odcienie.
## Log GDP
df_gapminder['gdp_cap_log'] = np.log10(df_gapminder['gdp_cap'])
## Pokaz log GDP z life exp
sns.scatterplot(data = df_gapminder[df_gapminder['year'] == 2007],
x = 'gdp_cap_log', y = 'life_exp', hue = "continent", alpha = .7);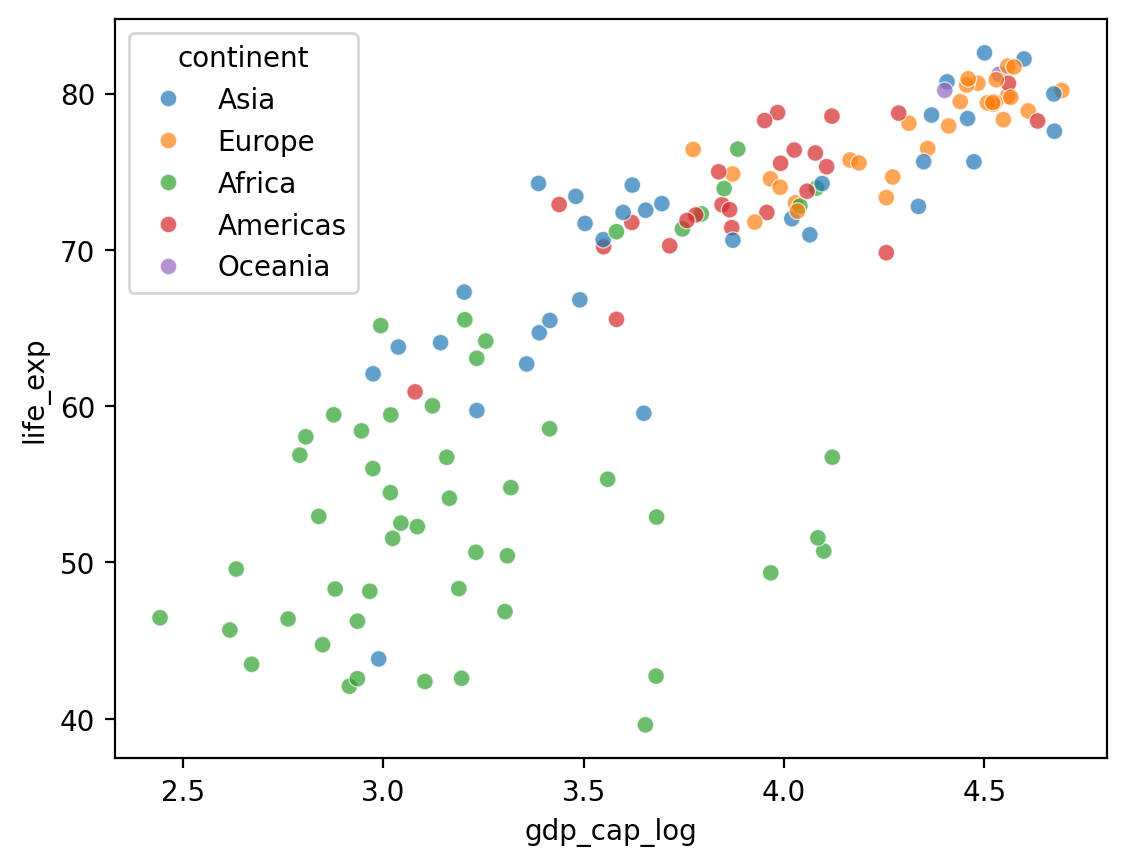
Dodajemy size¶
Co jeśli chcemy dodać czwarty komponent, który jest ciągły, jak
population?seabornpozwala nam to zrobić zsize- powstanie wykres bąbelkowy!
## Log GDP
df_gapminder['gdp_cap_log'] = np.log10(df_gapminder['gdp_cap'])
## Pokaz log GDP z life exp
sns.scatterplot(data = df_gapminder[df_gapminder['year'] == 2007],
x = 'gdp_cap_log', y = 'life_exp',
hue = "continent", size = 'population', alpha = .7);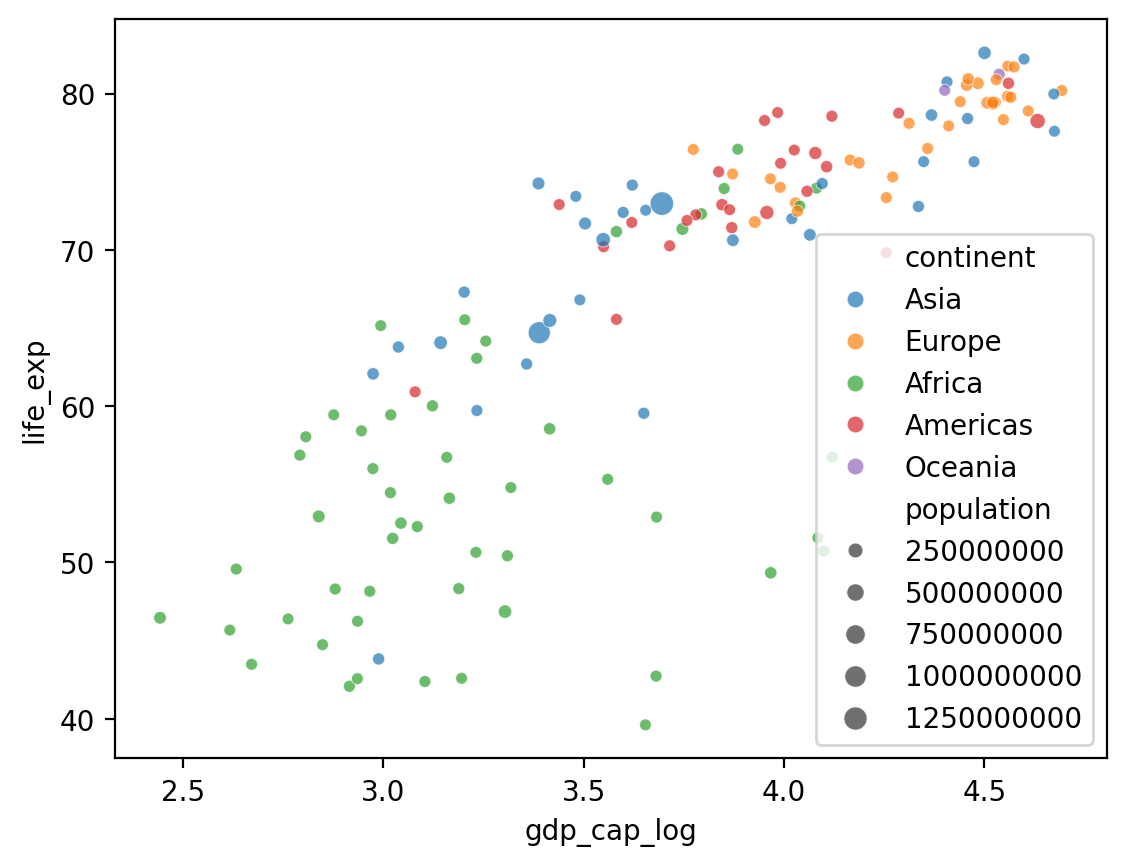
Zmiany w pozycji legendy¶
## Pokaz log GDP z life exp
sns.scatterplot(data = df_gapminder[df_gapminder['year'] == 2007],
x = 'gdp_cap_log', y = 'life_exp',
hue = "continent", size = 'population', alpha = .7)
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0);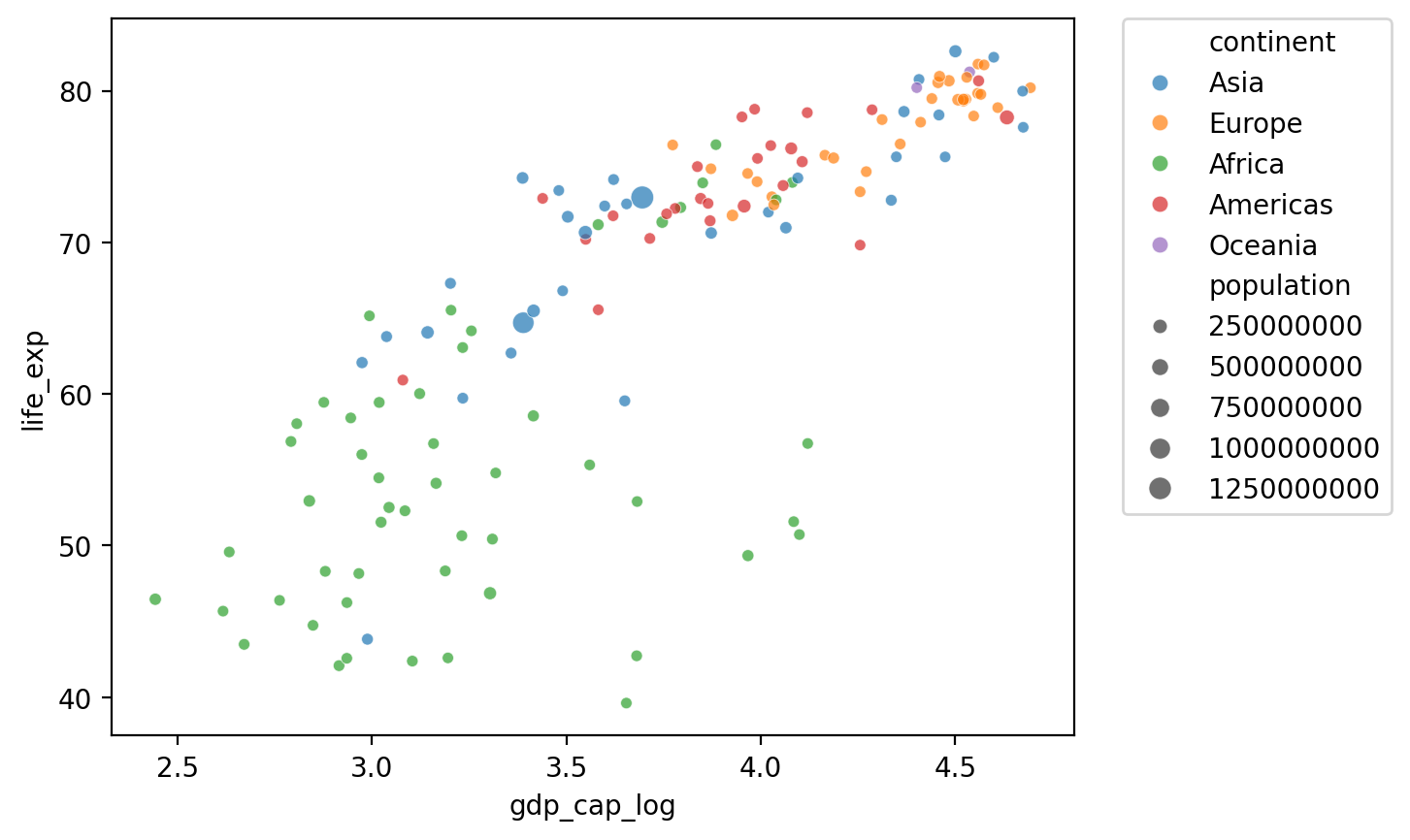
Wykres liniowy z sns.lineplot¶
Wykres liniowy równiez wizualizuje związek między dwiema zmiennymi ciągłymi.
Zazwyczaj pozycja linii na osi
yodzwierciedla średnią zmiennej na osiydla tej wartościx.Często używany do wykreślania zmian w czasie.
Jednym ze sposobów na stworzenie wykresu liniowego w seaborn jest użycie sns.lineplot.
Wykres life_exp oraz year¶
Jaki ogólny trend zauważamy?
sns.lineplot(data = df_gapminder,
x = 'year',
y = 'life_exp');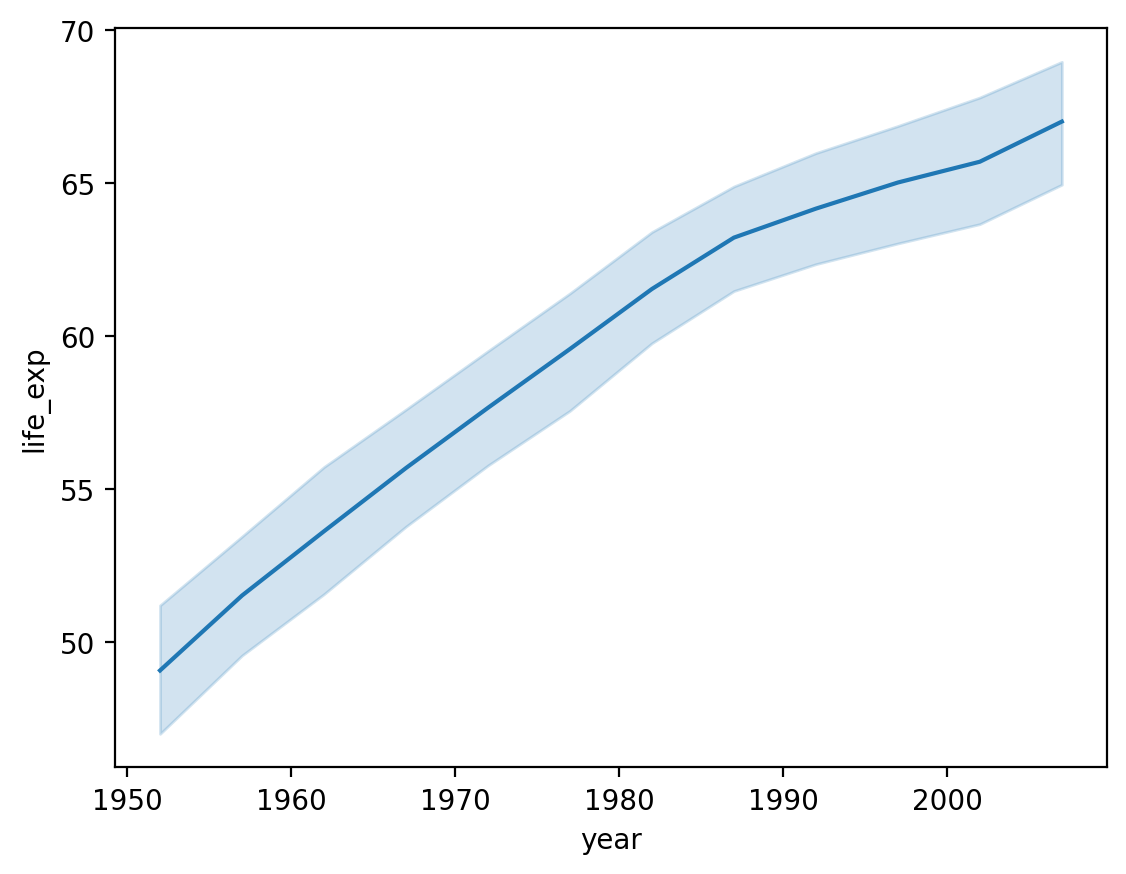
Modyfikowanie sposobu wyświetlania błędów/niepewności¶
Domyślnie,
seaborn.lineplotrysuje cieniowanie wokół linii reprezentującej przedział ufności.Możemy to zmienić za pomocą
errstyle.
sns.lineplot(data = df_gapminder,
x = 'year',
y = 'life_exp',
err_style = "bars");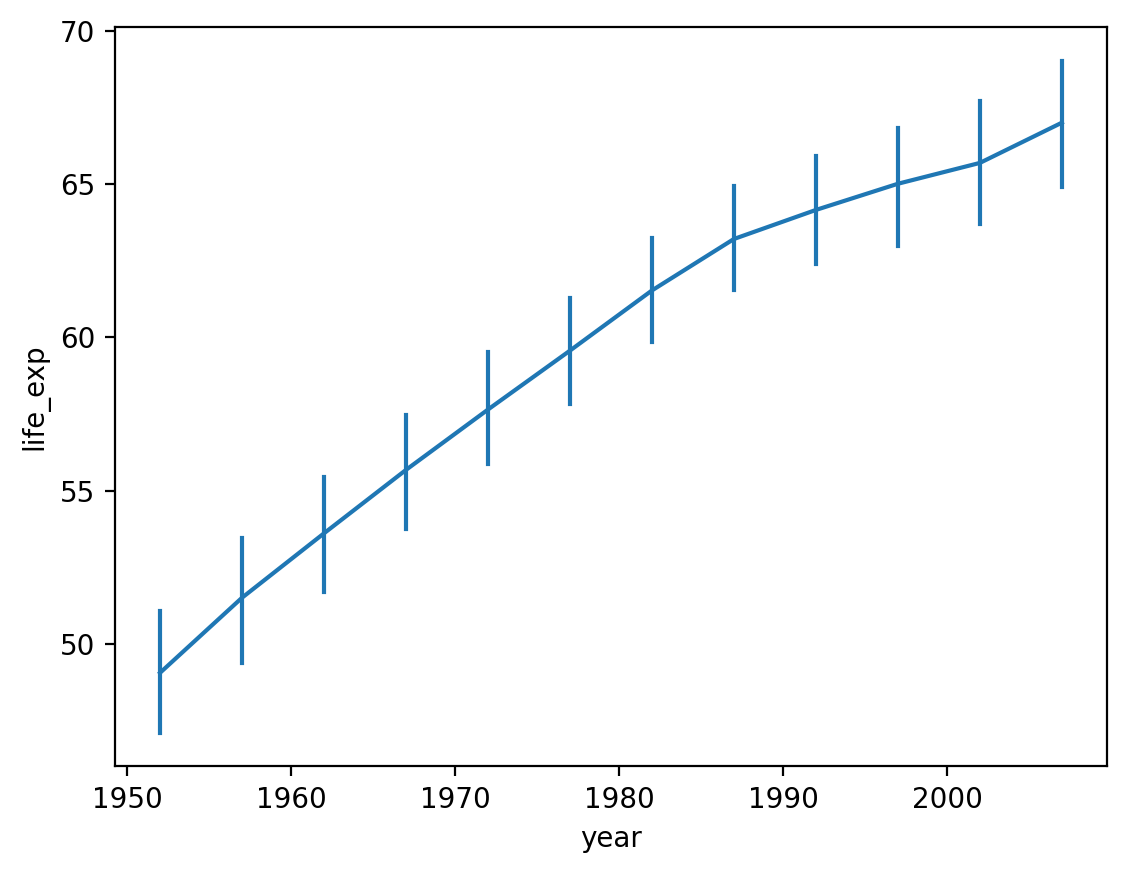
Dodawanie hue¶
Moglibyśmy również pokazać to według
kontynentów.Istnieje (na szczęście) pozytywna linia trendu dla każdego
kontynentu.
sns.lineplot(data = df_gapminder,
x = 'year',
y = 'life_exp',
hue = "continent")
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0);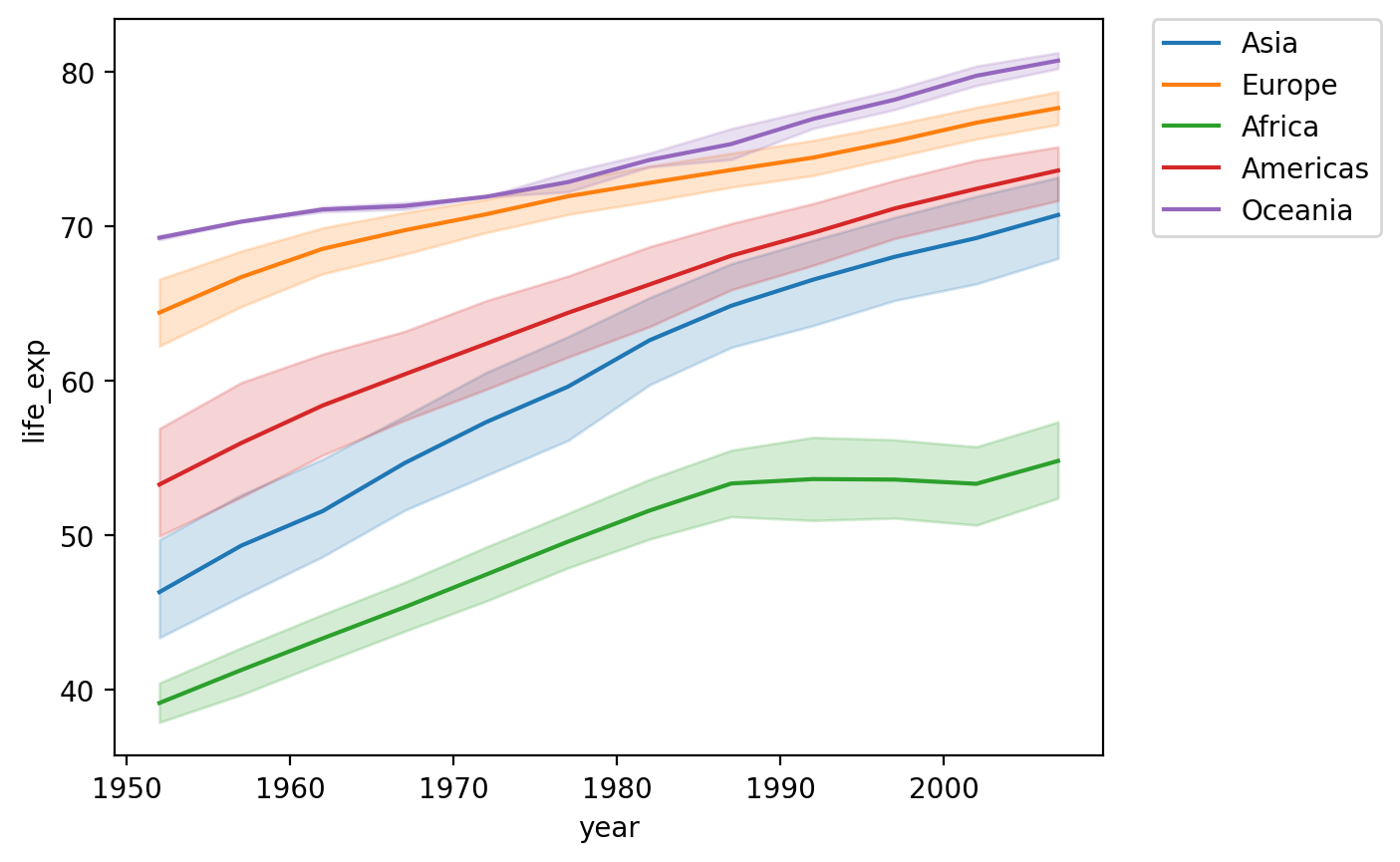
Sprawdź się!¶
Jak wykreślić zależność między year i gdp_cap tylko dla krajów w obu Amerykach?
### Twój kod tutajHeteroskedastyczność w gdp_cap według roku¶
Heteroskedastyczność to sytuacja, w której zmienność jednej zmiennej (np.
gdp_cap) zmienia się w funkcji innej zmiennej (np.roku).Jak myślisz, dlaczego tak jest w tym przypadku?
Rysowanie według kraju¶
Jest zbyt wiele krajów, aby wyraźnie wyświetlić je w
legendzie.Ale dwie górne linie to „Stany Zjednoczone” i „Kanada”.
Oznacza to, że dwa kraje stały się znacznie bogatsze w przeliczeniu na mieszkańca, podczas gdy inne nie odnotowały takiego samego wzrostu gospodarczego.
sns.lineplot(data = df_gapminder[df_gapminder['continent']=="Americas"],
x = 'year', y = 'gdp_cap', hue = "country", legend = None);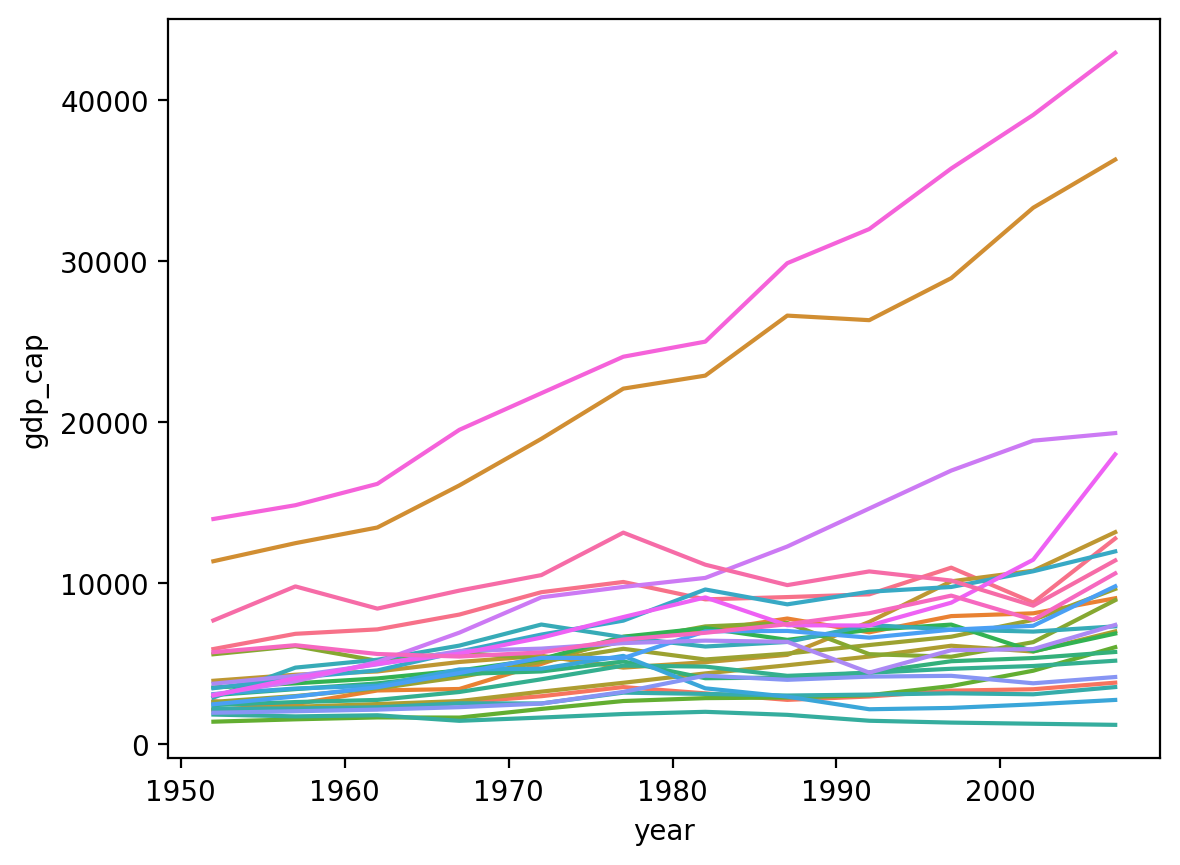
Wykorzystanie relplot¶
relplotpozwala na tworzenie wykresów liniowych lub wykresów rozproszonych przy użyciukind.relplotułatwia równieżfacet(który omówimy za chwilę).
sns.relplot(data = df_gapminder, x = "year", y = "life_exp", kind = "line");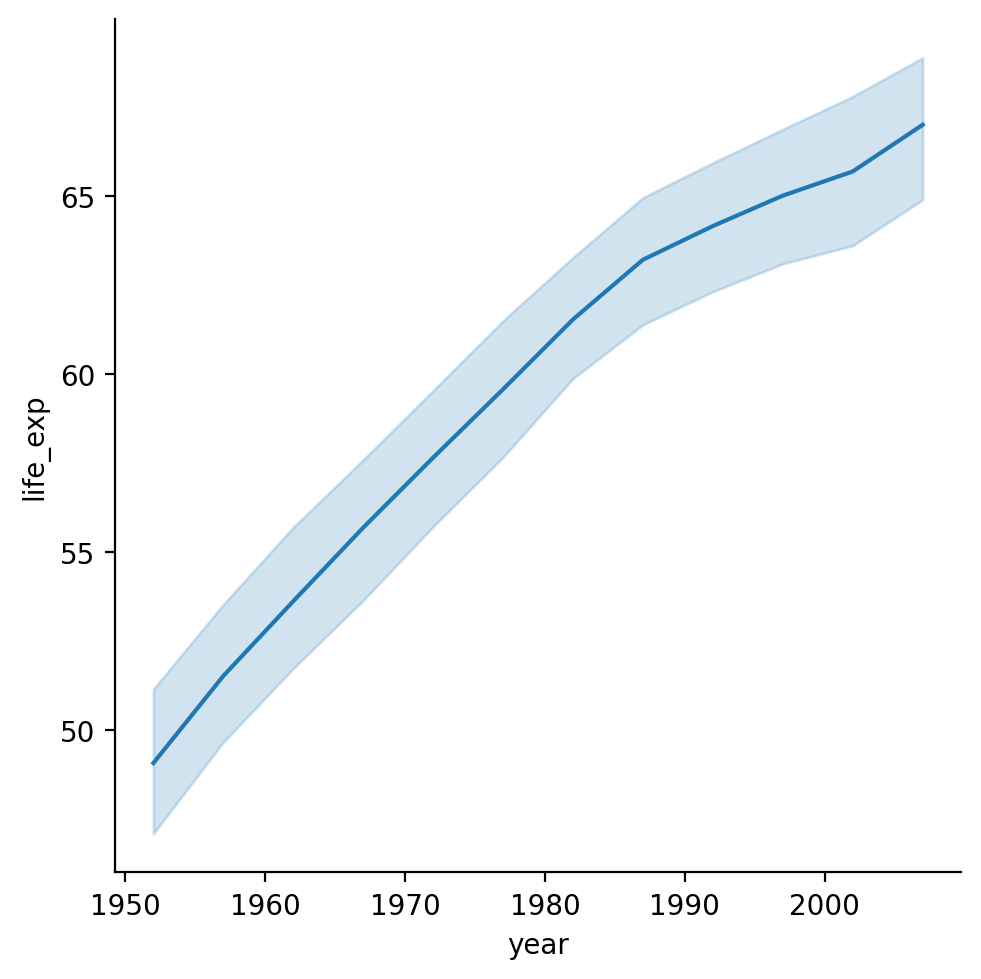
Grupowanie grafik w wiersze i kolumny¶
Możemy również wykreślić tę samą relację w wielu „oknach” lub facetach, dodając parametr rows/cols.
sns.relplot(data = df_gapminder, x = "year", y = "life_exp", kind = "line", col = "continent");
Dwuwymiarowe wykresy kategoryczne¶
Dwuwymiarowy wykres kategoryczny przedstawia (ewentualny) związek pomiędzy jedną zmienną kategoryczną (jakościową) a jedną zmienną ciągłą (ilościową).
Przykładowe dane¶
W tym miejscu powrócimy do naszego zbioru danych Pokemon, który zawiera więcej przykładów zmiennych kategorialnych.
df_pokemon = pd.read_csv("data/pokemon.csv")Wykresy słupkowe sns.barplot¶
Wykres słupkowy wizualizuje związek pomiędzy jedną zmienną ciągłą a zmienną kategorialną.
Wysokość każdego słupka zazwyczaj wskazuje średnią zmiennej ciągłej.
Każdy słupek reprezentuje inny poziom zmiennej kategorialnej.
Z seaborn, możemy użyć funkcji sns.barplot.
Średni Attack według statusu Legendary¶
sns.barplot(data = df_pokemon,
x = "Legendary", y = "Attack");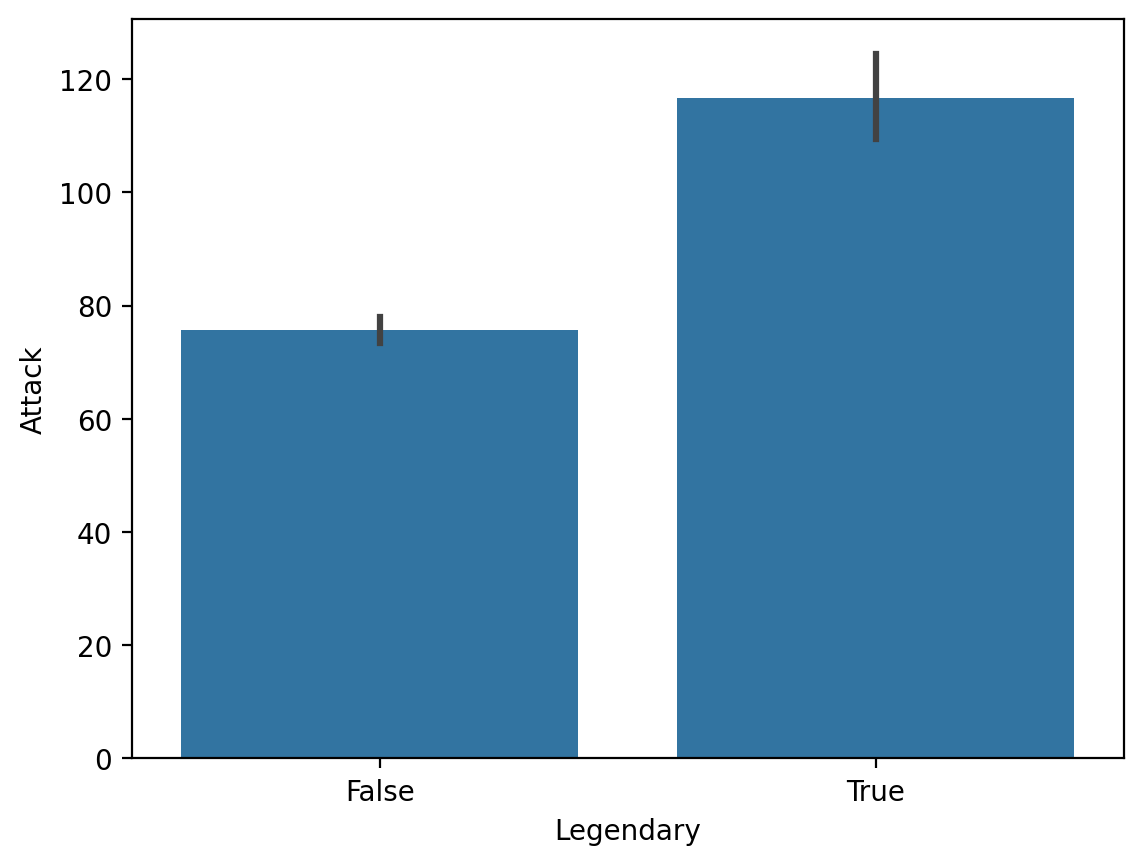
Średni Attack według Type 1¶
Zauważ, że rysunek jest większy, aby upewnić się, że wszystkie etykiety pasują.
plt.figure(figsize=(15,4))
sns.barplot(data = df_pokemon,
x = "Type 1", y = "Attack");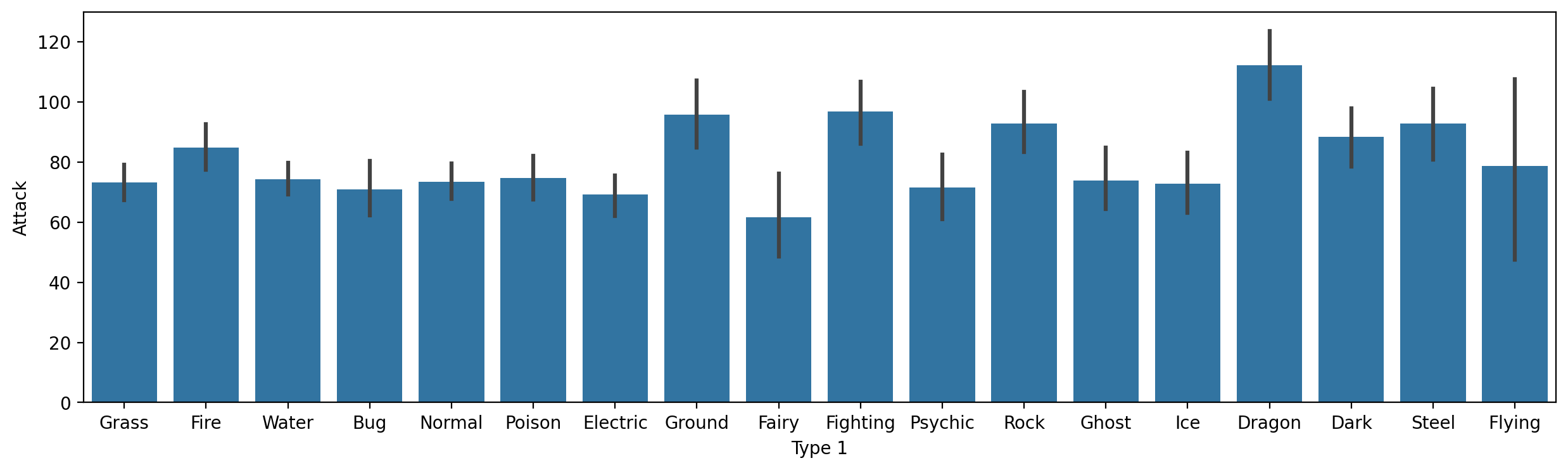
Sprawdź się¶
Jak wykreślić HP według Type 1?
### Twój kod tutajModyfikowanie hue¶
Podobnie jak w przypadku wykresu rozrzutu i liniowego, możemy zmienić hue, aby uzyskać większą przejrzystość.
Na przykład,
HPprzezType 1, dalej podzielone przez statusLegendary.
plt.figure(figsize=(15,4))
sns.barplot(data = df_pokemon,
x = "Type 1", y = "HP", hue = "Legendary");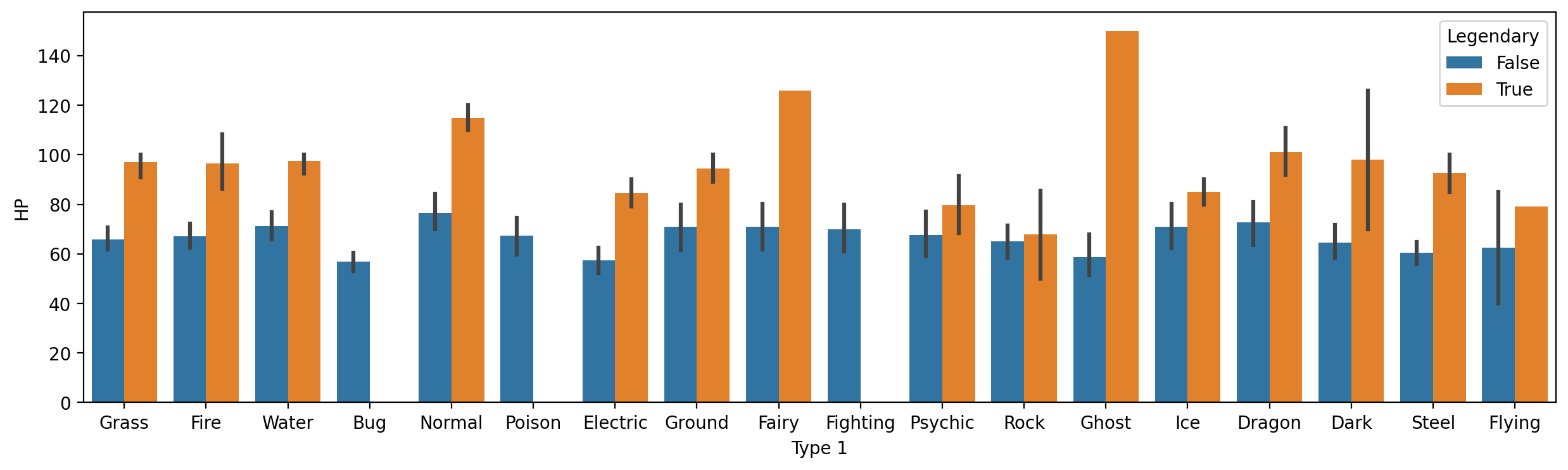
Wykorzystanie catplot¶
seaborn.catplotjest wygodną funkcją do wykreślania dwuwymiarowych danych kategorycznych przy użyciu szeregu typów wykresów (bar,box,strip).
sns.catplot(data = df_pokemon, x = "Legendary",
y = "Attack", kind = "bar");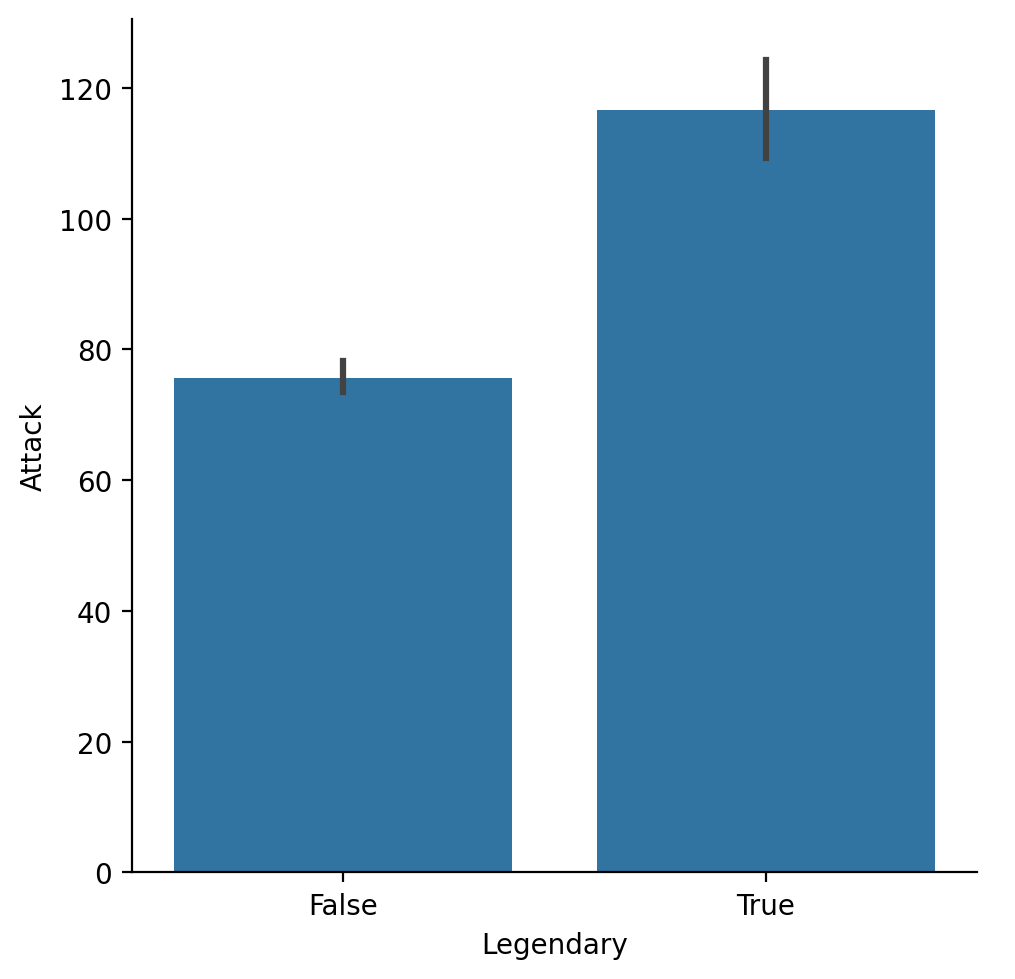
Wykresy paskowe¶
Wykres paskowy pokazuje każdy pojedynczy punkt (jak scatterplot), podzielony przez etykietę kategorii.
sns.catplot(data = df_pokemon, x = "Legendary",
y = "Attack", kind = "strip", alpha = .5);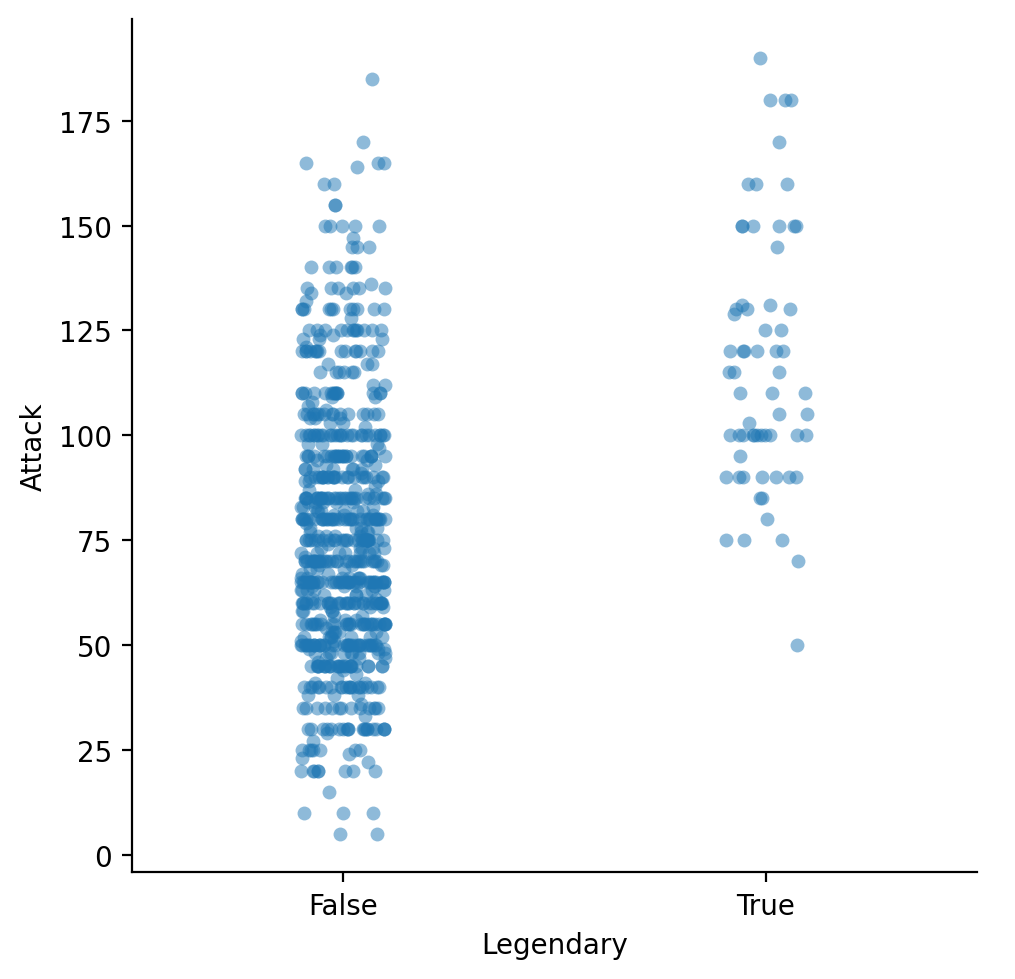
Dodanie średniej do wykresu paskowego¶
Możemy wykreślić dwa wykresy w tym samym czasie, pokazując zarówno poszczególne punkty, jak i średnie.
sns.catplot(data = df_pokemon, x = "Legendary",
y = "Attack", kind = "strip", alpha = .1);
sns.pointplot(data = df_pokemon, x = "Legendary",
y = "Attack", hue = "Legendary");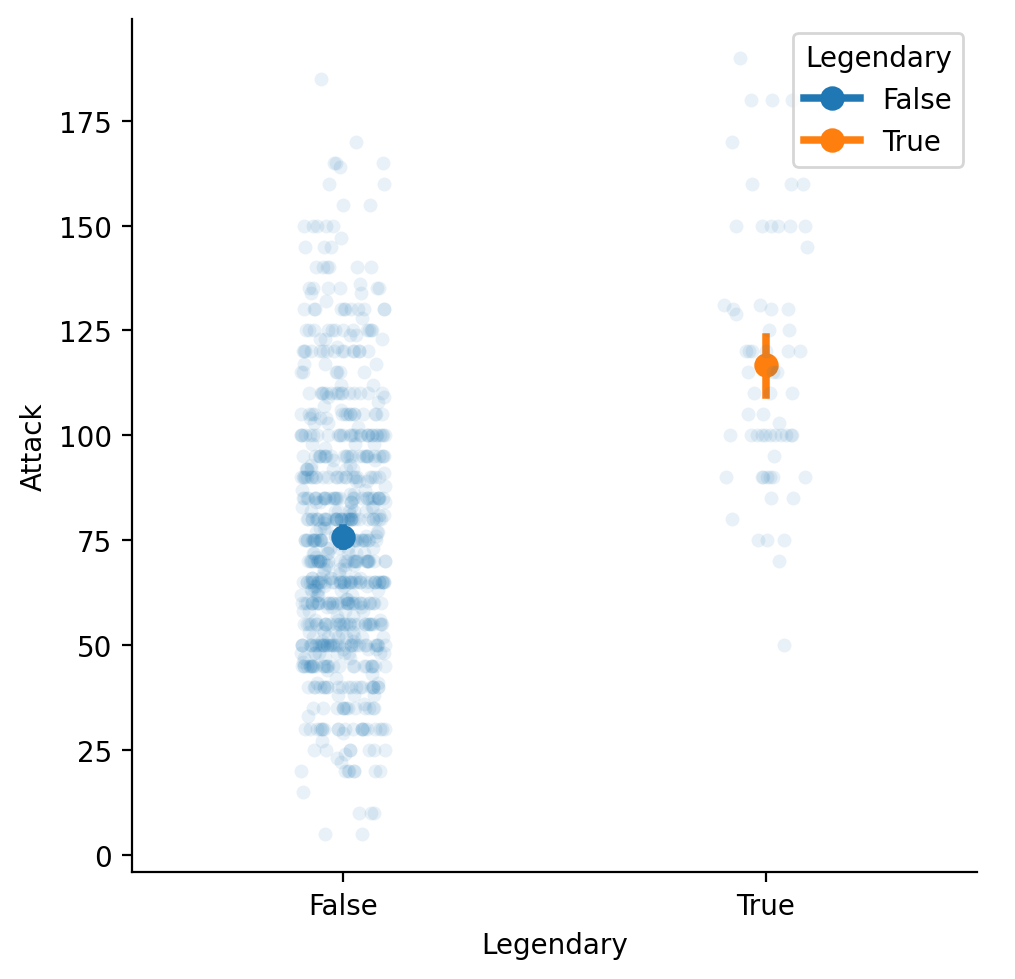
Wykresy pudełkowe¶
Wykres pudełkowy w teorii pokazuje zakres międzykwartylowy (środkowe 50% danych), medianę wraz z minimum i maksimum.
Typowy boxplot zawiera kilka komponentów, które są częścią jego anatomii:
Mediana: Jest to środkowa wartość danych, reprezentowana przez linię w ramce.
Ramki: Reprezentują one zakres międzykwartylowy danych (IQR), który reprezentuje zakres między Q1 i Q3. Dolna i górna krawędź reprezentują odpowiednio Q1 i Q3.
Wąsy: Są to pionowe linie, które rozciągają się od obu końców pudełka, aby reprezentować wartości minimalne i maksymalne, z wyłączeniem wartości odstających.
Wartości odstające: Są to punkty poza wąsami uważane za nietypowe lub skrajne w porównaniu z resztą danych.
Ograniczniki: Są to poziome linie na końcach wąsów, reprezentujące wartości minimalne i maksymalne, w tym wszelkie wartości odstające.
Czy wąsy pokazują minimum i maksimum?
Z punktu widzenia statystyki - końcówki wąsów nie są więc min oraz max - ponieważ nie zawierają części nietypowych wartości.
Standardowe zasady:
Wartości odstające (outliers): Są to punkty znajdujące się poza zakresem wąsów. Wartości te są uznawane za nietypowe w porównaniu do reszty danych.
Zakres wąsów: Wąsy rozciągają się do wartości, które mieszczą się w granicach:
Dolny wąs:
Górny wąs:
Ekstremalne wartości odstające: Jeśli wartości znajdują się znacznie dalej poza wąsami (np. lub ), mogą być uznane za ekstremalne odstające.
Wartości odstające są zazwyczaj wyświetlane jako pojedyncze punkty na wykresie pudełkowym, co pozwala na ich łatwą identyfikację.
Dlaczego wartości odstające są ważne?
Mogą wskazywać na błędy w danych (np. literówki, błędy pomiarowe).
Mogą reprezentować rzeczywiste, ale rzadkie zdarzenia, które warto zbadać.
Wartości odstające mogą znacząco wpływać na statystyki opisowe, takie jak średnia, dlatego ich identyfikacja jest kluczowa w analizie danych.
Dlaczego 1,5 × IQR?
× to standardowa wartość używana do identyfikacji umiarkowanych wartości odstających.
Rozstęp międzykwartylowy (IQR) to różnica między trzecim kwartylem (Q3) a pierwszym kwartylem (Q1), czyli zakres, w którym znajduje się środkowe 50% danych.
Wartości, które znajdują się poza zakresem:
Dolny próg: - 1.5 ×
Górny próg: + 1.5 × są uznawane za wartości odstające.
Wartość została wybrana empirycznie jako rozsądny kompromis między wykrywaniem wartości odstających a ignorowaniem naturalnych fluktuacji w danych.
Dlaczego 3 × IQR?
3 × jest używane do identyfikacji wartości ekstremalnych odstających, które są znacznie bardziej odległe od reszty danych.
Wartości poza zakresem:
Dolny próg: - 3 ×
Górny próg: + 3 × są uznawane za ekstremalne wartości odstające.
Wartość 3 × jest bardziej rygorystyczna i pozwala na identyfikację punktów, które są bardzo nietypowe i mogą wskazywać na błędy w danych lub rzadkie zdarzenia.
sns.catplot(data = df_pokemon, x = "Legendary",
y = "Attack", kind = "box");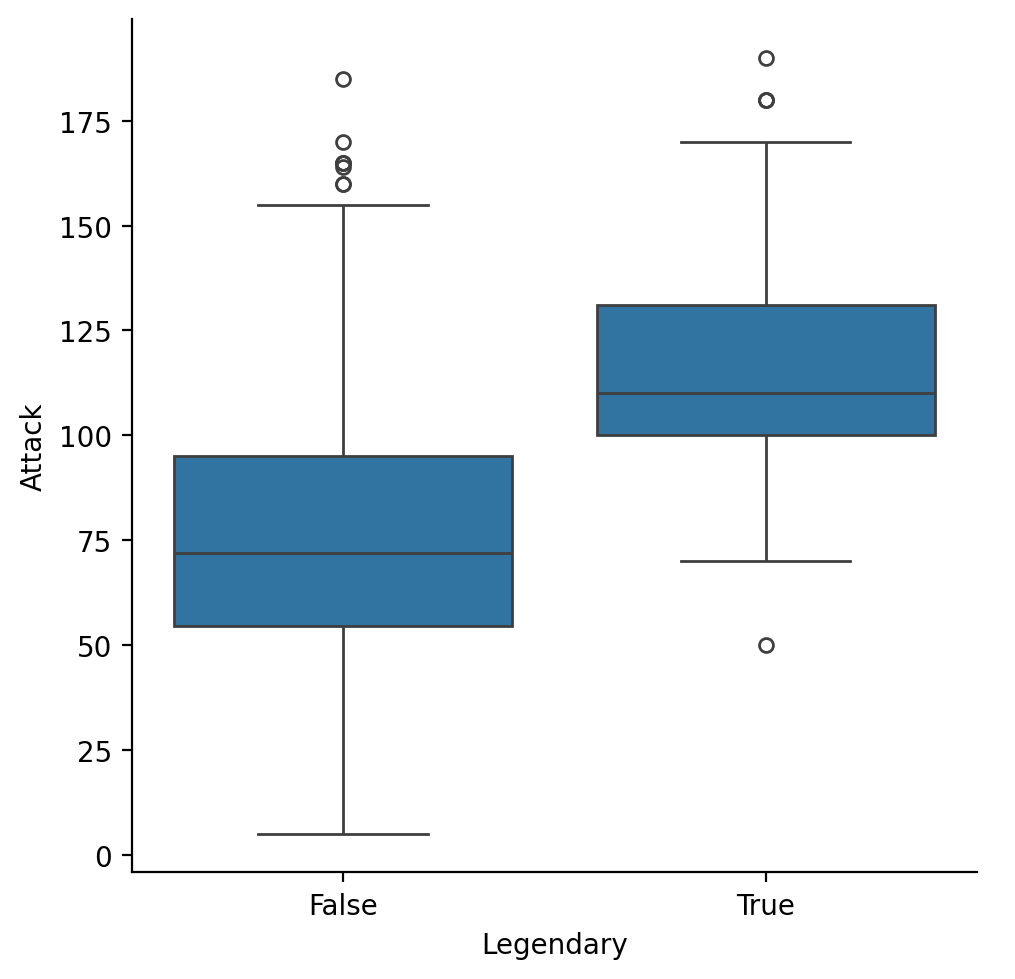
Mozna łatwo oczywiście wykreślić jedną zmienną i jej wykres pudełkowy:
titanic = pd.read_csv('data/titanic.csv')
titanic.head()
sns.boxplot(x=titanic["age"]);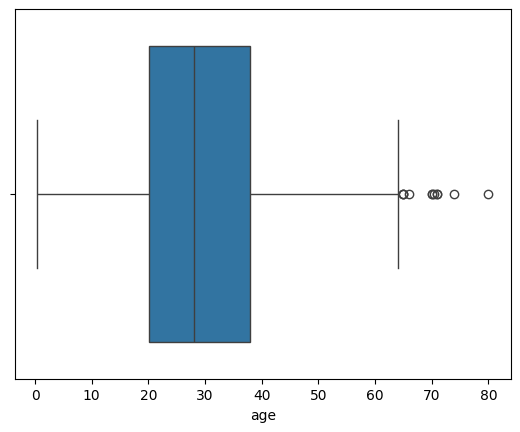
Pogrupujemy teraz boxplot według zmiennej kategorialnej, odwołując się do kolumn w ramce danych:
sns.boxplot(data=titanic, x="age", y="class");
sns.violinplot(data=titanic, x="age", y="class", alpha=0.5 );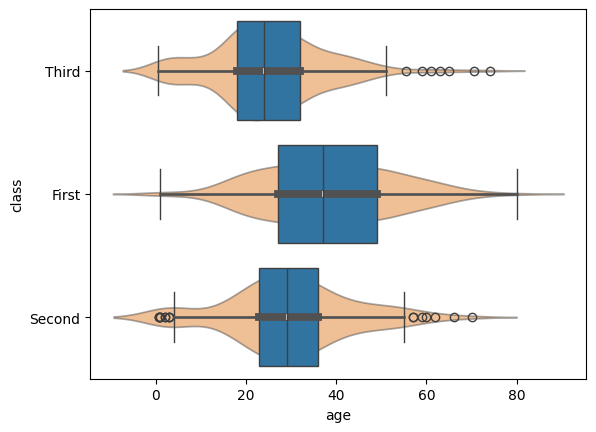
Narysujmy pionowy wykres pudełkowy z zagnieżdżonym grupowaniem według dwóch zmiennych:
sns.boxplot(data=titanic, x="class", y="age", hue="alive");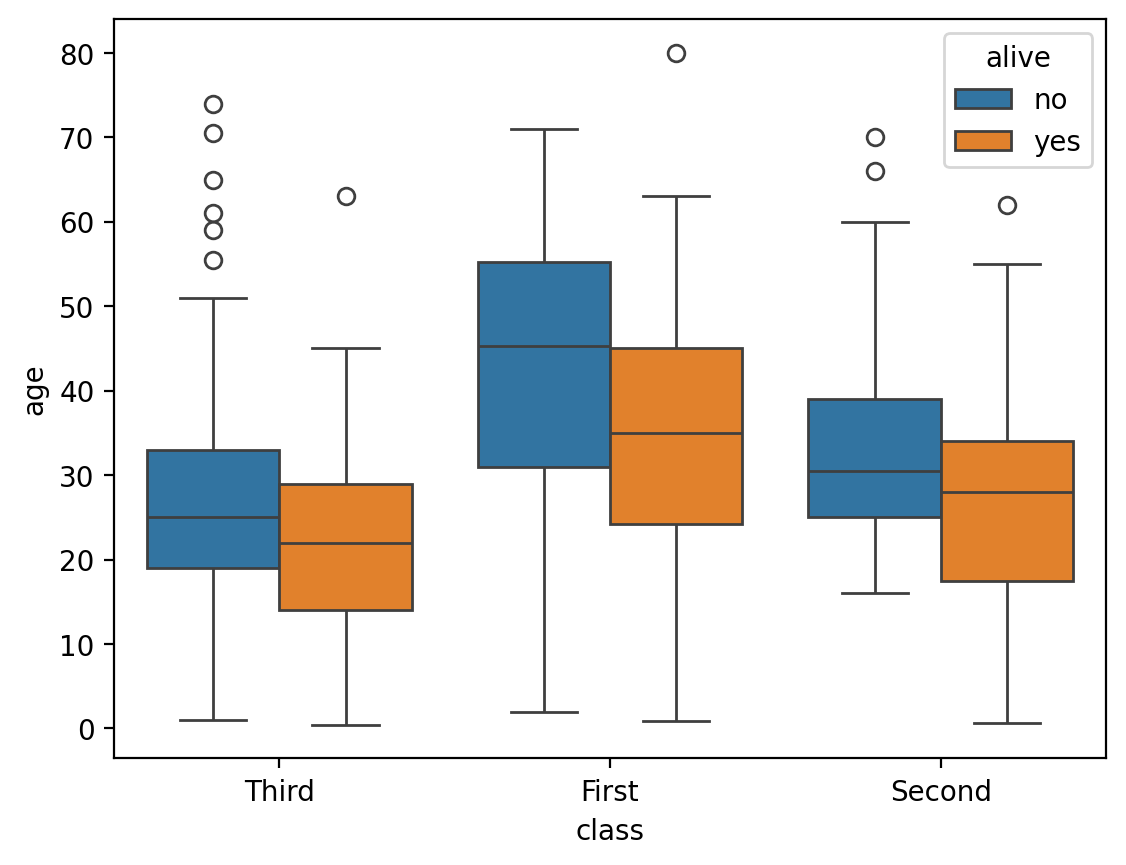
Zobacz takze, jak narysować wykresy wiolinowe, wykresy tzw. roju (podobne do paskowego) - więcej informacji tutaj.
Podsumowanie¶
Były to dwa rozdziały o wizualizacji danych na początek - absolutne minimum, aby zacząć wykonywać eksploracyjną analizę danych.
W szczególności, w tym rozdziale było to wprowadzenie do:
Pakietu
seaborn.Wykreślania danych jednowymiarowych i różnowymiarowych.
Tworzenia wykresów z wieloma warstwami.