Estymacja punktowa i przedziałowa¶
Estymacja średniej¶
exec(open('est_p.py').read())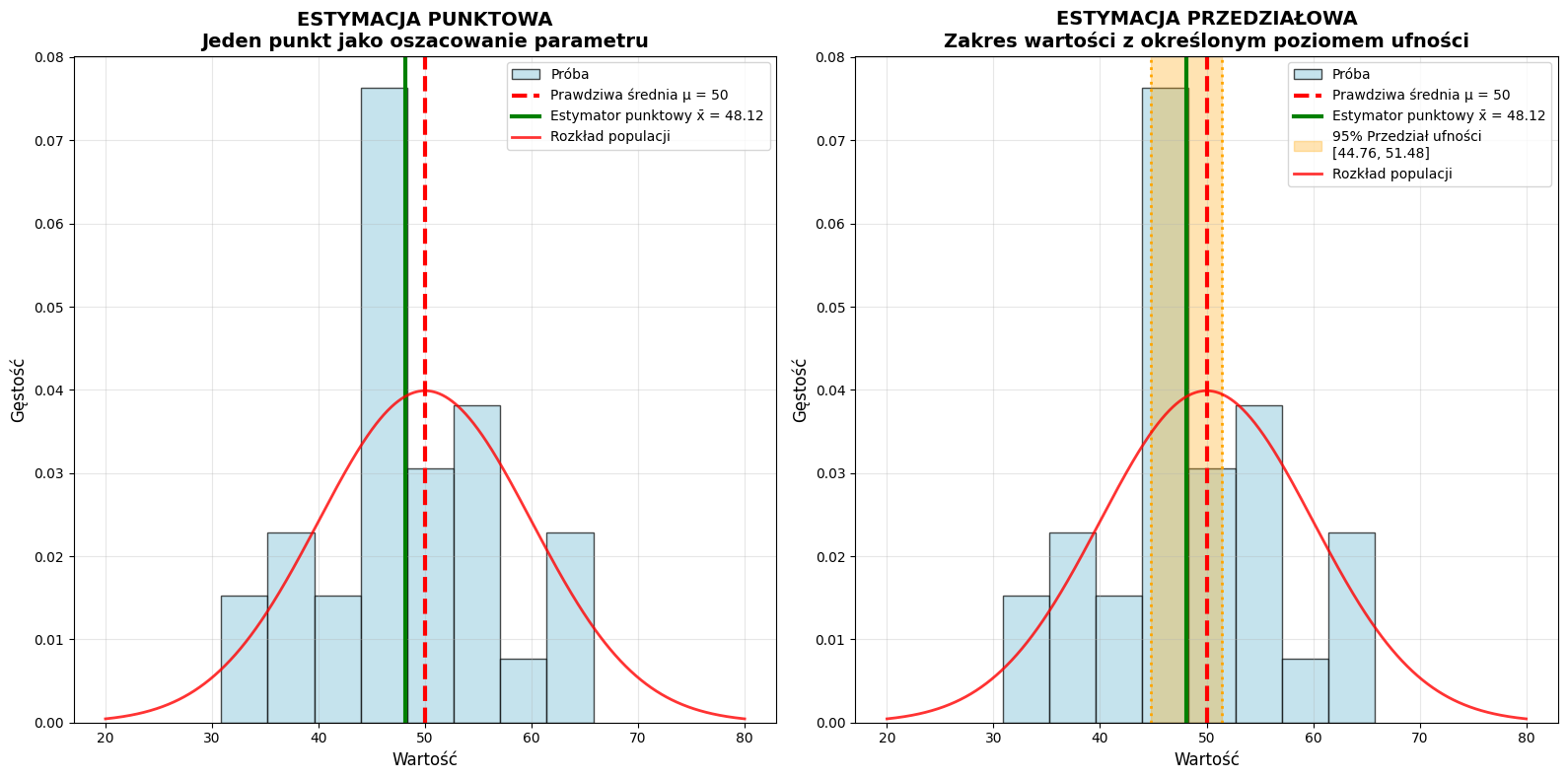
============================================================
PODSTAWOWE KONCEPCJE ESTYMACJI
============================================================
1. ESTYMACJA PUNKTOWA:
• Jeden punkt jako oszacowanie parametru populacji
• Przykład: x̄ = 48.12 jako estymator μ = 50
2. ESTYMACJA PRZEDZIAŁOWA:
• Zakres wartości z określonym poziomem ufności
• Przykład: 95% P.U. = [44.76, 51.48]
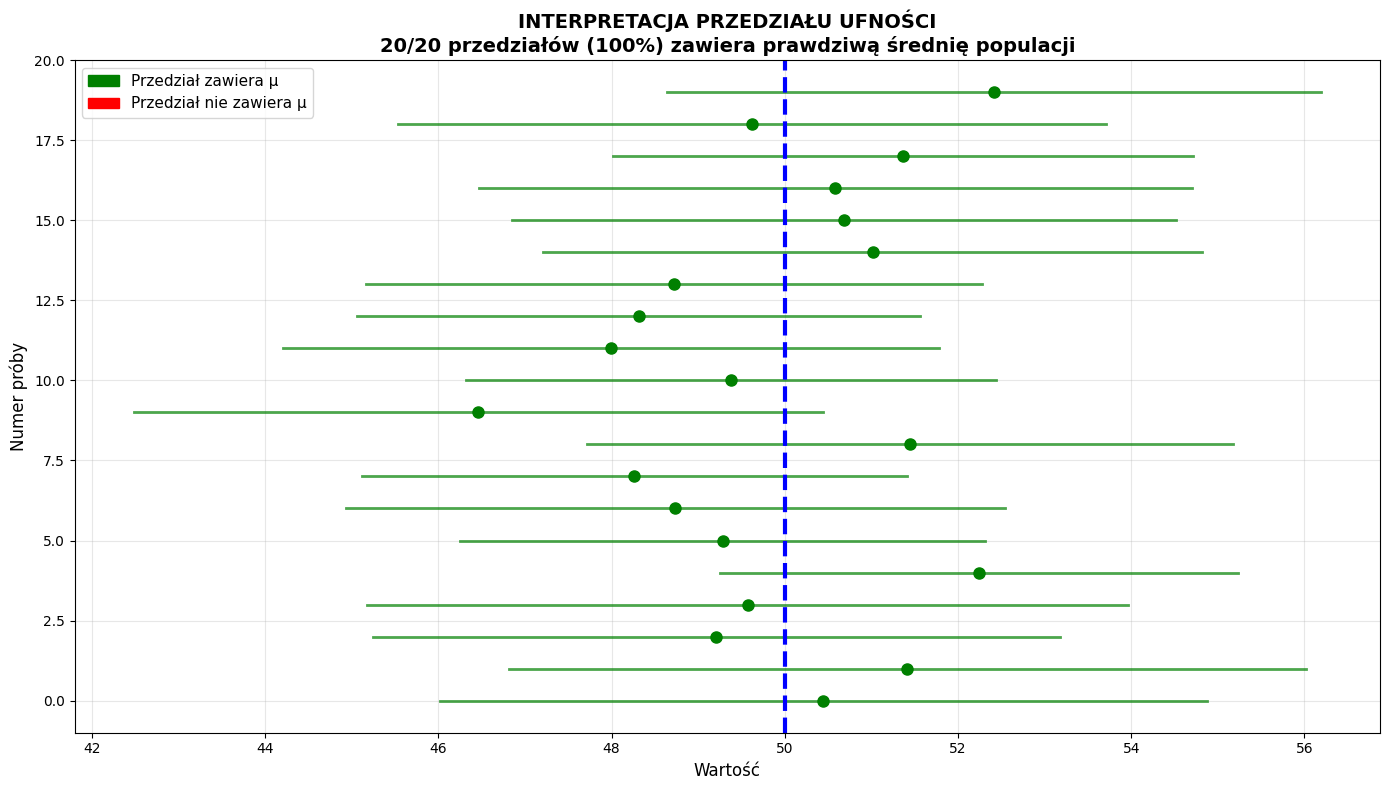
3. INTERPRETACJA PRZEDZIAŁU UFNOŚCI:
• Jeśli powtórzymy procedurę 100 razy,
• około 95 przedziałów będzie zawierało prawdziwą μ
• W naszej symulacji: 100% przedziałów zawierało μ
============================================================
Zadanie 1.¶
Twoim zadaniem jest przeanalizowanie danych ankietowych dostępnych pod poniższym linkiem: surveydata3.csv. Analiza obejmuje oszacowanie średniej z przedziałami ufności, błędem standardowym, minimalną wielkością próby dla określonej dokładności oraz oszacowanie proporcji.
Dane są ładowane z pliku CSV dostępnego pod następującym linkiem: surveydata3.csv.
Zbiór danych zawiera 753 wiersze i 55 kolumn, w tym różne zmienne demograficzne i odpowiedzi ankietowe.
Szczegółowy opis zbioru danych można znaleźć tutaj.
Instrukcje
Załaduj dane:
Załaduj dane z pliku CSV.
Oblicz średnią liczbę godzin snu na dobę.
Oblicz odsetek osób, które chcą kupić gadżety Udacity.
Oszacowanie średniej:
Oblicz średnią liczby godzin snu na dobę studentów Udemy.
Oblicz przedział ufności dla średniej.
Oblicz błąd standardowy.
Oblicz minimalną wielkość próby wymaganą do osiągnięcia określonej dokładności (np. 3%).
Wizualizuj wyniki za pomocą wykresu pudełkowego (średnia, błędy standardowe, przedział ufności).
import pandas as pd
import matplotlib.pyplot as plt
url = 'https://raw.githubusercontent.com/juanspinzon/survey-data/refs/heads/main/clean_surveydata3.xlsx?raw=true'
df = pd.read_excel(url, engine='openpyxl')
dane = df["sleep hours per night"]
dane = dane.dropna()
print(dane.head())
plt.hist(dane,bins=10);2 7.0
3 7.0
4 8.0
5 6.0
6 8.0
Name: sleep hours per night, dtype: float64
# twoje rozwiązanie tutaj# Odkomentuj następującą linię, aby zobaczyć rozwiązanie:
# %load ./solutions/solution11.pyEstymacja wariancji¶
Dlaczego stosujemy rozkład chi-kwadrat (χ²) w estymacji wariancji?¶
Podstawowe wyjaśnienie¶
Rozkład chi-kwadrat pojawia się naturalnie przy estymacji wariancji z bardzo konkretnego powodu matematycznego. Oto proste wyjaśnienie:
1. Punkt wyjścia - rozkład normalny¶
Jeśli mamy próbkę z rozkładu normalnego:
2. Standaryzacja obserwacji¶
Każdą obserwację możemy wystandaryzować:
3. Suma kwadratów zmiennych standardowych¶
Gdy podnosimy do kwadratu i sumujemy standardowe zmienne normalne:
To już jest rozkład chi-kwadrat z stopniami swobody.
4. Problem w praktyce - nieznana średnia¶
W praktyce nie znamy , więc używamy :
5. Kluczowe twierdzenie Fishera¶
Twierdzenie Fishera mówi, że:
gdzie:
- wariancja próbkowa
Tracimy jeden stopień swobody przez szacowanie średniej
6. Dlaczego chi-kwadrat?¶
Chi-kwadrat powstaje, ponieważ:
Suma kwadratów: Wariancja to średnia z kwadratów odchyleń
Zmienne normalne: Zakładamy normalność populacji
Strata stopni swobody: Szacowanie średniej “kosztuje” jeden stopień swobody
Matematyczne uzasadnienie¶
Rozkład wariancji próbkowej:¶
Gęstość chi-kwadrat:¶
gdzie to stopnie swobody.
Praktyczne konsekwencje¶
Przedział ufności dla wariancji:¶
Przekształcając na :¶
Właściwości rozkładu chi-kwadrat¶
Wartości nieujemne: (wariancja nie może być ujemna)
Asymetria: Rozkład jest prawostronnie skośny
Wartość oczekiwana:
Wariancja:
Warunki stosowania¶
Rozkład chi-kwadrat dla wariancji jest poprawny tylko gdy:
Populacja ma rozkład normalny
Obserwacje są niezależne
Próbka jest losowa
Intuicyjne wyjaśnienie¶
Wyobraź sobie, że:
Mierzysz odchylenia od średniej:
Podnosisz je do kwadratu:
Sumujesz wszystkie:
Ta suma kwadratów odchyleń, przeskalowana przez prawdziwą wariancję, ma rozkład chi-kwadrat. To naturalna konsekwencja matematyki rozkładu normalnego.
Porównanie z rozkładem t-Studenta¶
| Parametr | Rozkład t | Rozkład χ² |
|---|---|---|
| Estymacja | Średnia | Wariancja |
| Gdy σ² jest | Nieznana | Szacowana |
| Statystyka | ||
| Symetryczny | Tak | Nie (prawostronna skośność) |
| Zakres |
Kluczowe wnioski¶
Chi-kwadrat używamy dla wariancji, bo matematycznie tak wynika z teorii
Jedna średnia = jeden stopień swobody mniej
Tylko dla rozkładu normalnego!
Przedziały ufności są asymetryczne (w przeciwieństwie do średniej)
exec(open('est_war.py').read())
Zadanie 2.¶
Oszacowanie wariancji:
Oblicz wariancję i odchylenie std. liczby godzin snu na dobę studentów Udemy.
Oblicz 95% przedział ufności dla wariancji.
# twoje rozwiązanie tutajEstymacja proporcji¶
exec(open('est_prop.py').read())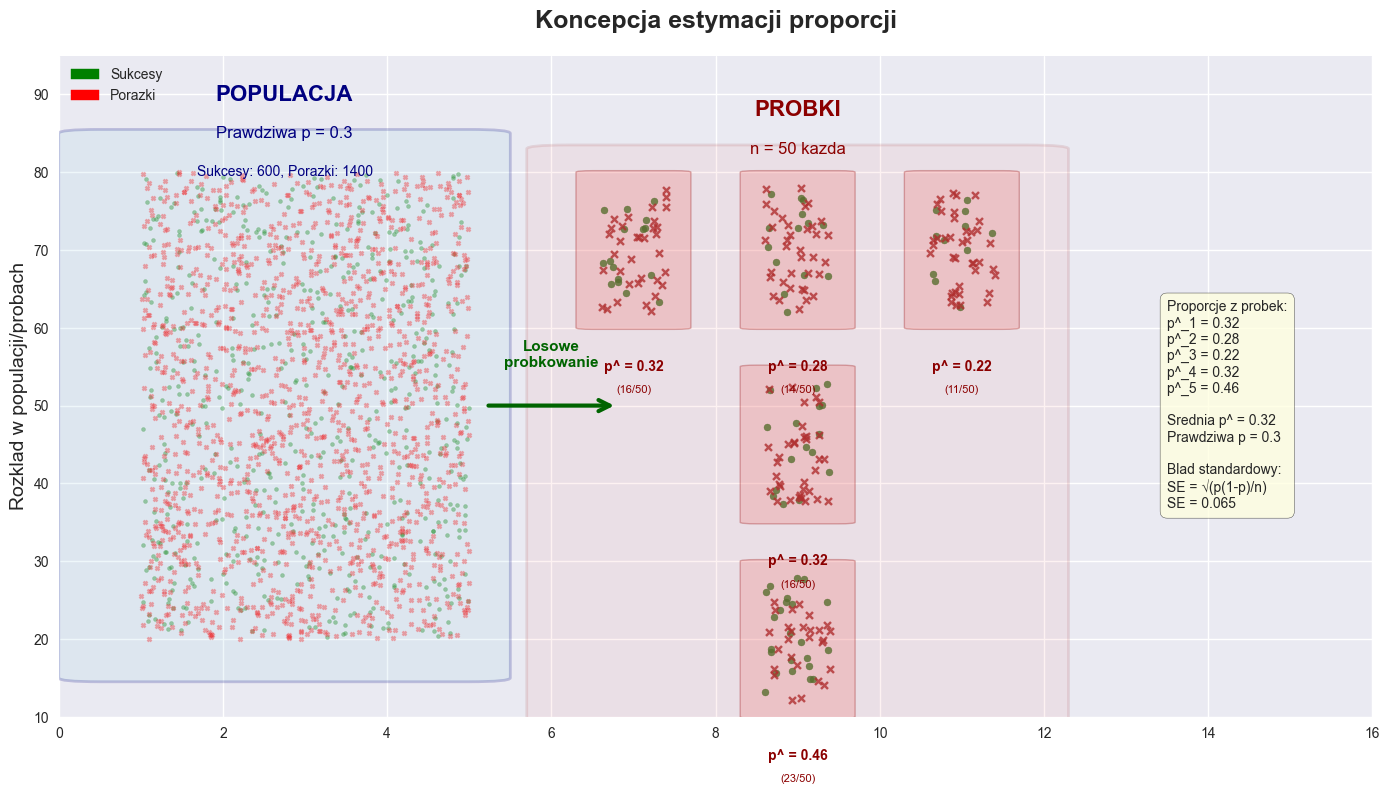
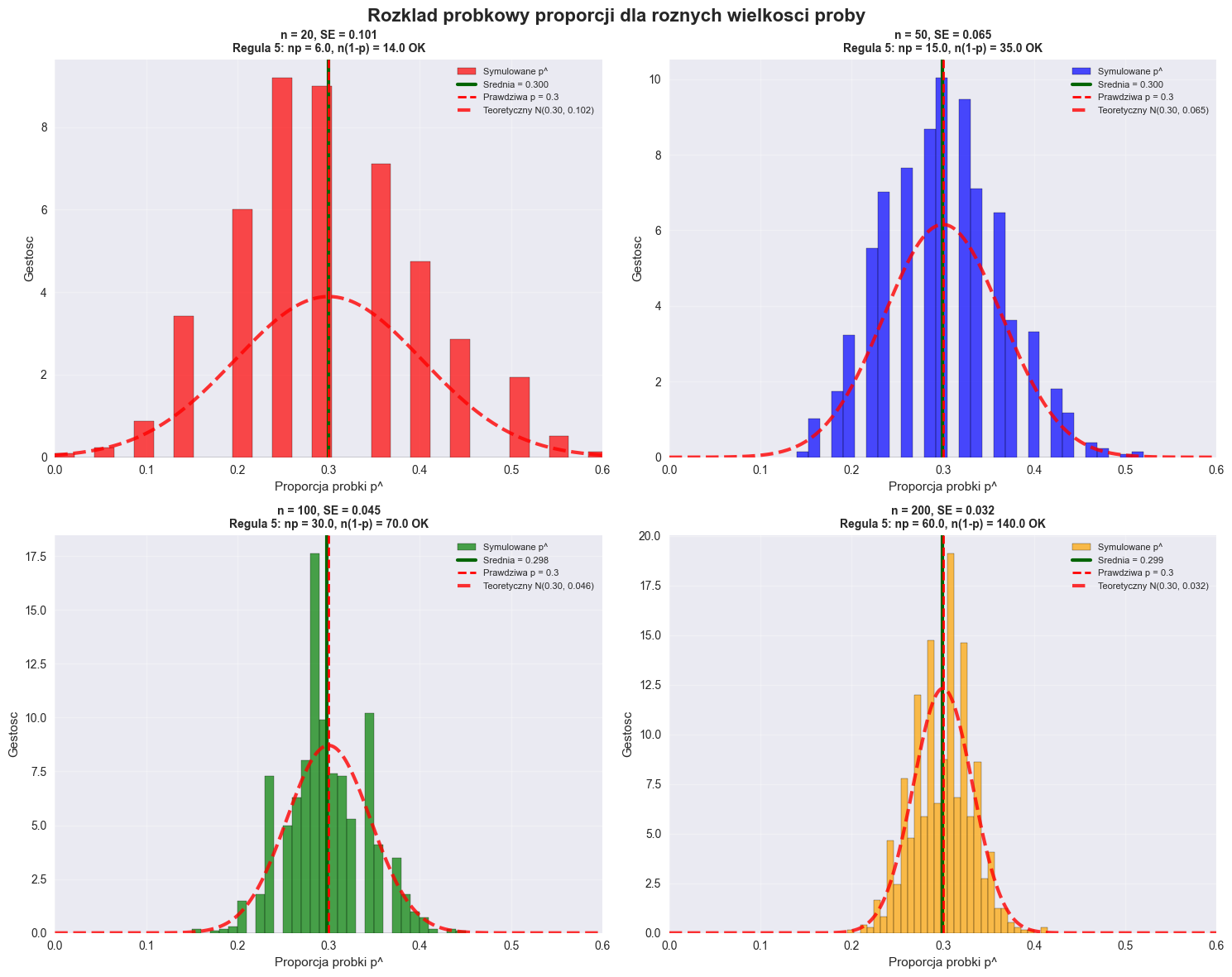
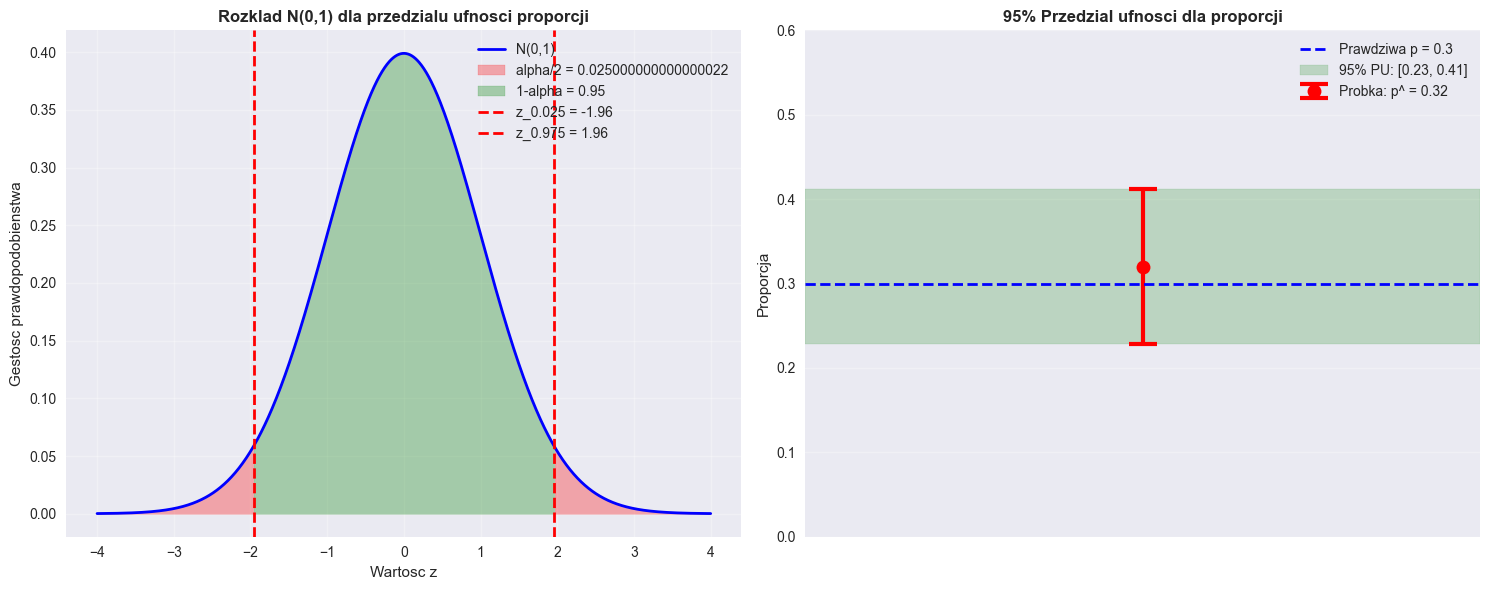

======================================================================
PODSUMOWANIE ESTYMACJI PROPORCJI
======================================================================
Prawdziwa proporcja populacji: p = 0.3
Wielkosc probki: n = 100
WYNIKI ESTYMACJI:
Liczba sukcesow: 32
Proporcja probkowa: p^ = 0.320
Blad standardowy: SE(p^) = 0.047
95% Przedzial ufnosci: [0.229, 0.411]
Margines bledu: ±0.091
SPRAWDZENIE REGULY 5:
np^ = 32.0 ≥ 5: TAK
n(1-p^) = 68.0 ≥ 5: TAK
WERYFIKACJA:
Czy przedzial zawiera prawdziwa wartosc? TAK
Szerokosc przedzialu: 0.183
Zadanie 3.¶
Oszacowanie proporcji:
Oblicz proporcję osób, które chcą kupić gadżety Udacity.
Oblicz przedział ufności dla tej proporcji.
Oblicz błąd standardowy.
Oblicz minimalną wielkość próby wymaganą do osiągnięcia określonej dokładności (np. 3%).
Wizualizuj wyniki za pomocą wykresu pudełkowego (proporcja, błędy standardowe, przedział ufności).
# twoje rozwiązanie tutajZadanie domowe¶
Twoim zadaniem jest przeanalizowanie danych ankietowych “Diagnoza społeczna” przeprowadzanych przez wiele lat w Polsce.
Dane są ładowane z pliku CSV dostępnego w kategorii data/ankiety. W pliku “diagnozaDict.csv” znajdują się szczegółowe opisy pytań zadanych respondentom.
Instrukcje
Załaduj dane:
Załaduj dane z pliku CSV.
Oblicz średnią zmiennej “gp64” - p64 Pana/Pani własny (osobisty) dochod miesieczny netto (na reke).
Oblicz odsetek osób, które *** (np. odpowiedziały na pytanie g54_04 “sukces w życiu odzwierciedlają posiadane dobra materialne”: “ZDECYDOWANIE TAK”, wg płci) *** lub inne kategoryczne wg płci.
Oszacowanie średniej i odsetka:
Oblicz przedział ufności dla średniej i odsetka.
Oblicz ich błędy standardowe.
Zwizualizuj wyniki za pomocą wykresu pudełkowego (średnia, błędy standardowe, przedział ufności).
ankieta = pd.read_csv("data/ankiety/diagnoza.csv")
ankieta.head()# twoje rozwiązanie tutajZałącznik¶
Przydatne funkcje Pythona w estymacji¶
W załączniku do tego rozdziału “funkcje_est.py” znajdziecie zestaw przydatnych funkcji Pythona, które można wykorzystać w estymacji parametrów populacji.
Zwróć uwagę, że w przypadku wizualizowania wyników wraz z estymacją - istnieje wiele rozwiązań graficznych, wedle uznania.
# exec(open('funkcje_est.py').read())