Rozdziały 5-6-7¶
W kolejnych rozdziałach zagłębimy się w wizualizację danych.
Jak tworzyć wizualizacje w Pythonie?
O jakich zasadach powinniśmy pamiętać?
Jak współpracować z Matplotlib, Pyplot?
Jak pracować nad wizualizacjami w Seaborn?
Jakie są dobre praktyki tworzenia wizualizacji danych?
Następnie, zanim przystąpi do analizy statystycznej, będziemy pracować nad zarządzaniem i czyszczeniem naszych danych.
Jak radzić sobie z brakującymi wartościami?
Jak sobie poradzić z brudnymi danymi?
Jakie są podstawowe sposoby opisywania danych?
Pamiętajcie, ze te rozdziały to integralna część Eksploracyjnej Analizy Danych w Pythonie.
W tym rozdziale¶
Czym jest wizualizacja danych i dlaczego jest ważna?
Wprowadzenie do
matplotlib.Typy wykresów jednowymiarowych:
Histogramy (jednowymiarowe).
Wykresy rozrzutu (tzw. scatterplots - dwuwymiarowe).
Wykresy słupkowe (takze dwuwymiarowe).
Wprowadzenie: wizualizacja danych¶
Czym jest wizualizacja danych?¶
Wizualizacja danych odnosi się do procesu (i wyniku) graficznego przedstawiania danych.
Dla naszych celów w tym rozdziale będziemy mówić głównie o typowych metodach wykresów danych, w tym:
Histogramy
Wykresy punktowe
Wykresy liniowe
Wykresy słupkowe
Dlaczego wizualizacja danych jest ważna?¶
Eksploracyjna analiza danych
Przekazywanie spostrzeżeń
Pokazywanie ukrytych asocjacji w danych
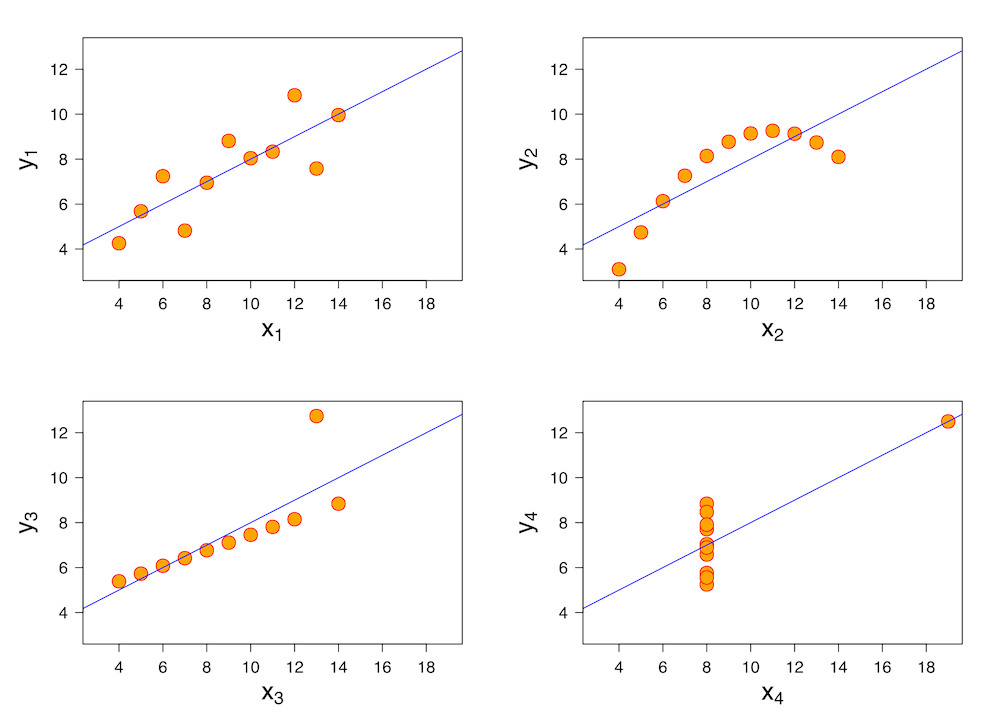
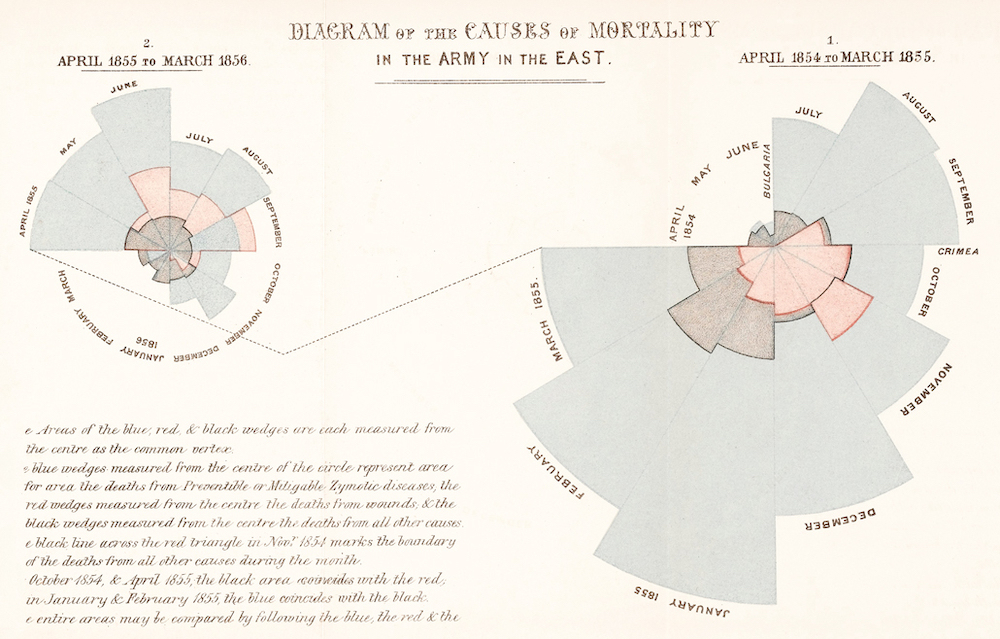
Wpływ na zrozumienie świata¶
Florence Nightingale (1820-1910) był reformatorem społecznym, statystykiem i założycielem nowoczesnego pielęgniarstwa.
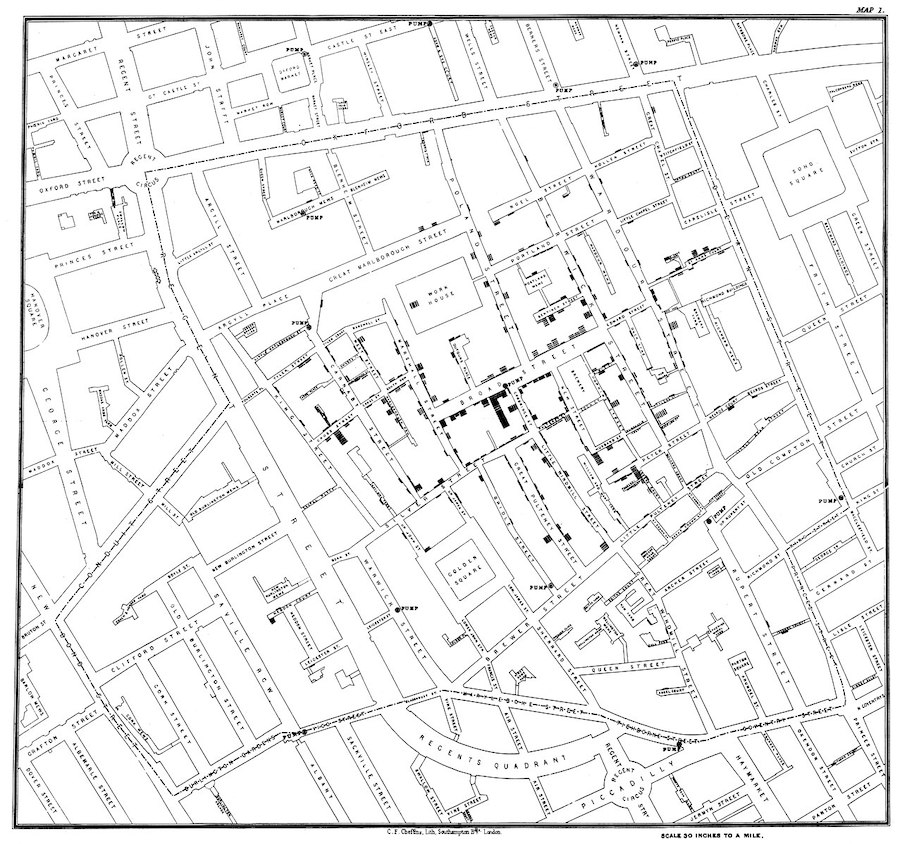
Wpływ na zrozumienie świata (cz. 2)¶
John Snow (1813-1858) był lekarzem, którego wizualizacja ognisk cholery pomogła zidentyfikować źródło i mechanizm rozprzestrzeniania się (zaopatrzenie w wodę).
Wprowadzenie do matplotlib¶
Ładowanie pakietów¶
Tutaj ładujemy podstawowe pakiety, których będziemy używać.
Dodajemy również kilka linijek kodu, które zapewniają, że nasze wizualizacje będą wykreślane „inline” z naszym kodem i że będą miały ładną, wyraźną jakość.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import scipy.stats as ss%matplotlib inline
%config InlineBackend.figure_format = 'retina'Czym jest matplotlib?¶
matplotlibto pakiet graficzny dla Pythona.
Wiele tutoriali dostępnych online.
Również wiele przykładów
matplotlibw użyciu.
Zauważ, że seaborn, (który omówimy wkrótce) używa matplotlib „pod maską”.
Czym jest pyplot?¶
pyplotto zbiór funkcji w ramachmatplotlib, które naprawdę ułatwiają wykreślanie danych.
Z pyplot, możemy łatwo wykreślić takie rzeczy jak:
Histogramy (
plt.hist)Wykresy rozrzutu (
plt.scatter)Wykresy liniowe (
plt.plot)Wykresy słupkowe (
plt.bar)
Przykładowe dane¶
Załadujmy nasz znajomy zestaw danych Pokemon, który można znaleźć w sekcji data/pokemon.csv.
df_pokemon = pd.read_csv("data/pokemon.csv")
df_pokemon.head(3)Histogramy¶
Czym są histogramy?¶
Histogram to wizualizacja pojedynczej ciągłej zmiennej ilościowej (np. dochodu lub temperatury).
Histogramy są przydatne do sprawdzania, jak rozkłada się zmienna.
Mogą być używane do określenia, czy rozkład jest normalny, skośny lub bimodalny.
Histogram jest wykresem jednowymiarowym, tj. wyświetla tylko jedną zmienną.
Histogramy w matplotlib¶
Aby utworzyć histogram, wywołaj plt.hist z pojedynczą kolumną DataFrame (lub numpy.ndarray).
Pytanie: Co mówi nam ten wykres?
p = plt.hist(df_pokemon['Attack'])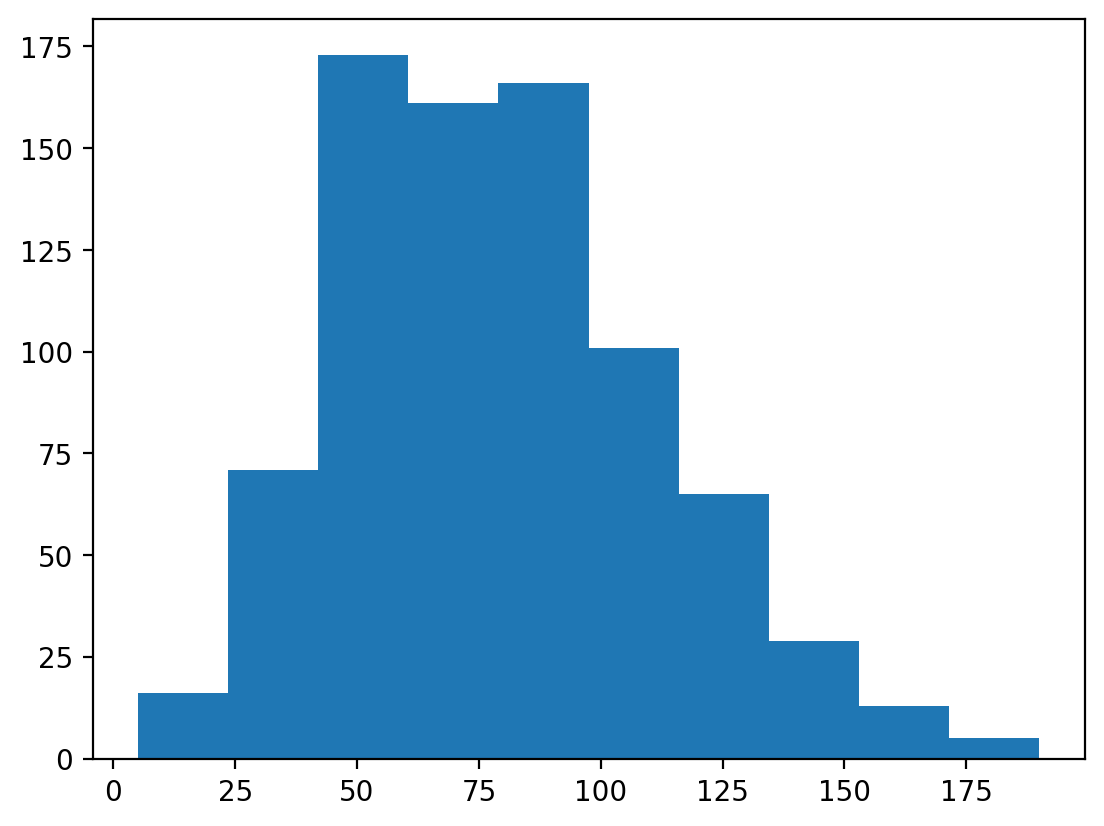
Zmiana liczby przedziałów¶
Histogram umieszcza dane ciągłe w przedziałach (np. 1-10, 11-20 itd.).
Wysokość każdego przedziału odzwierciedla liczbę obserwacji w tym przedziale.
Zwiększanie lub zmniejszanie liczby przedziałów zapewnia większą lub mniejszą szczegółowość rozkładu.
### Ten wykres ma wiele przedziałów - 30.
p = plt.hist(df_pokemon['Attack'], bins = 30)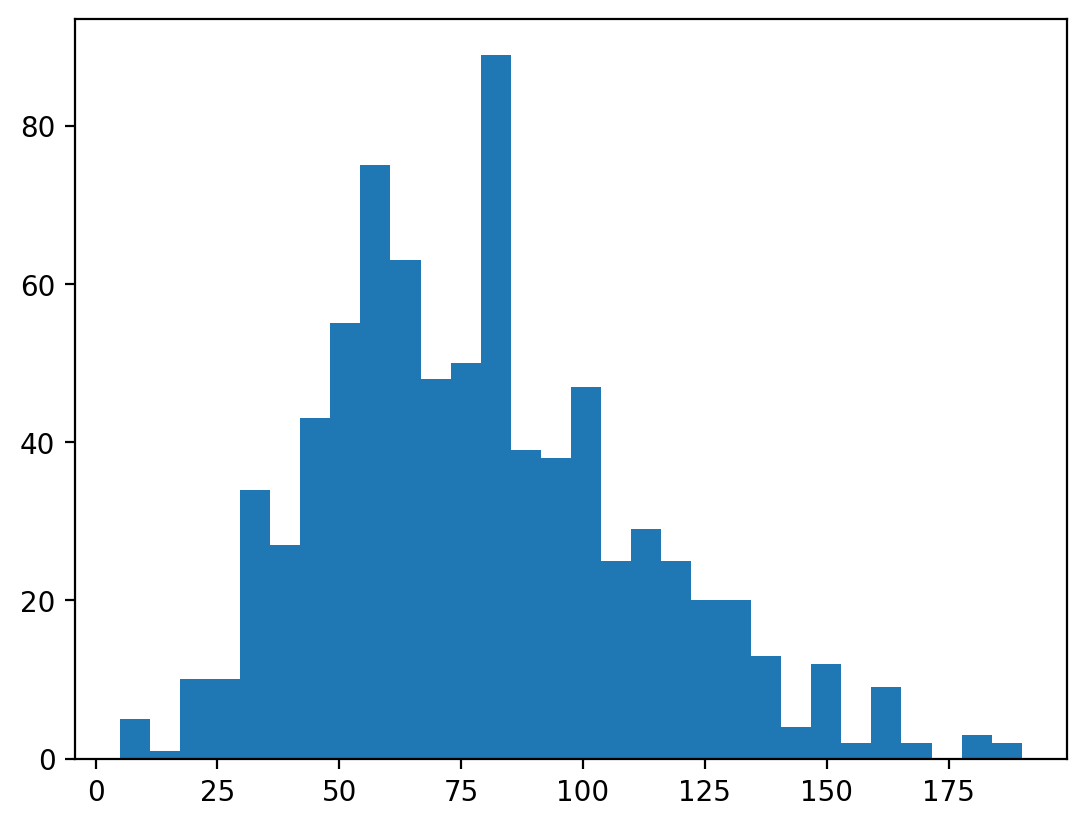
### Ten ma mniej
p = plt.hist(df_pokemon['Attack'], bins = 5)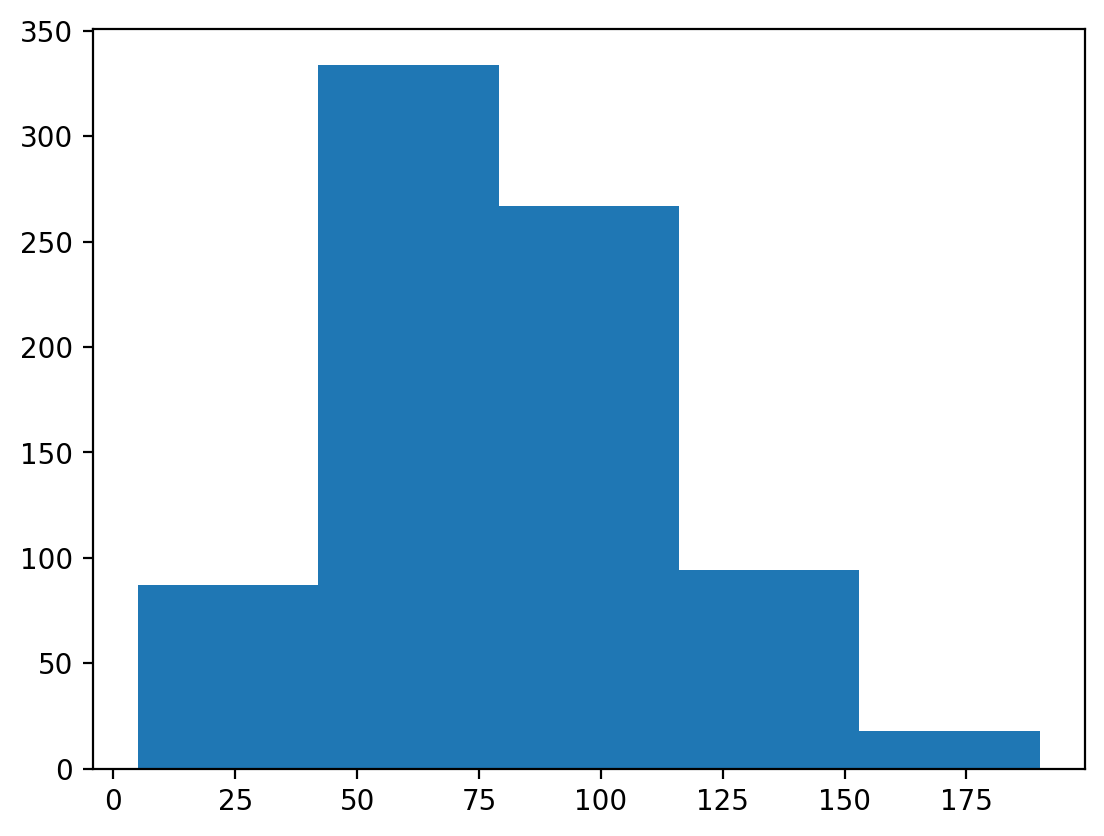
Zmiana poziomu alpha¶
Poziom alfa zmienia przezroczystość twojego wykresu.
### ten ma mniej przedziałów
p = plt.hist(df_pokemon['Attack'], alpha = .6)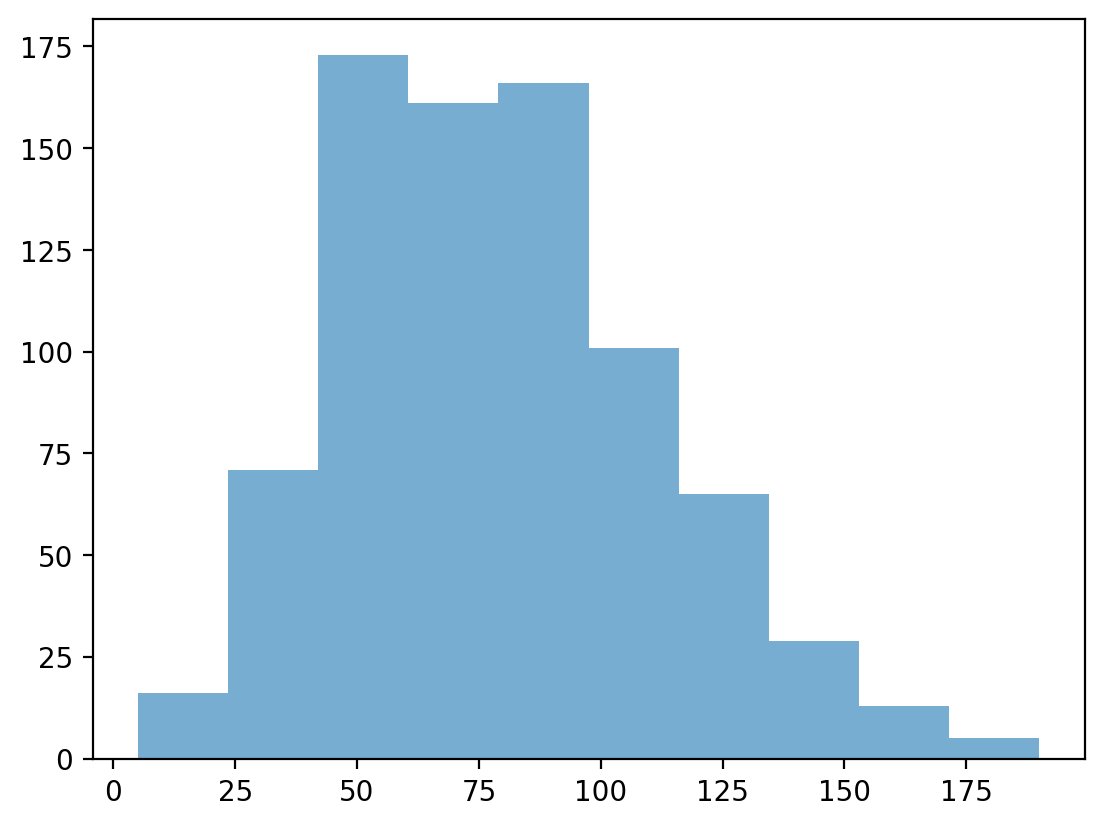
Sprawdź się¶
Jak stworzyć histogram wyników dla Defense?
### Twój kod tutajSprawdź się¶
Czy wiesz jak stworzyć histogram wyników dla Typu 1?
### Twój kod tutajInformacja z histogramów¶
Histogramy są niezwykle przydatne do poznawania kształtu naszego rozkładu.
Możemy zadawać pytania takie jak:
Czy ten rozkład jest względnie normalny?
Czy rozkład jest skośny?
Czy są wartości odstające?
Dane o rozkładzie normalnym¶
Możemy użyć funkcji numpy.random.normal, aby utworzyć rozkład normalny, a następnie go wykreślić.
Rozkład normalny ma następujące cechy:
Klasyczny kształt “dzwonu” (symetryczny).
Średnia, mediana i moda są identyczne.
norm = np.random.normal(loc = 10, scale = 1, size = 1000)
p = plt.hist(norm, alpha = .6)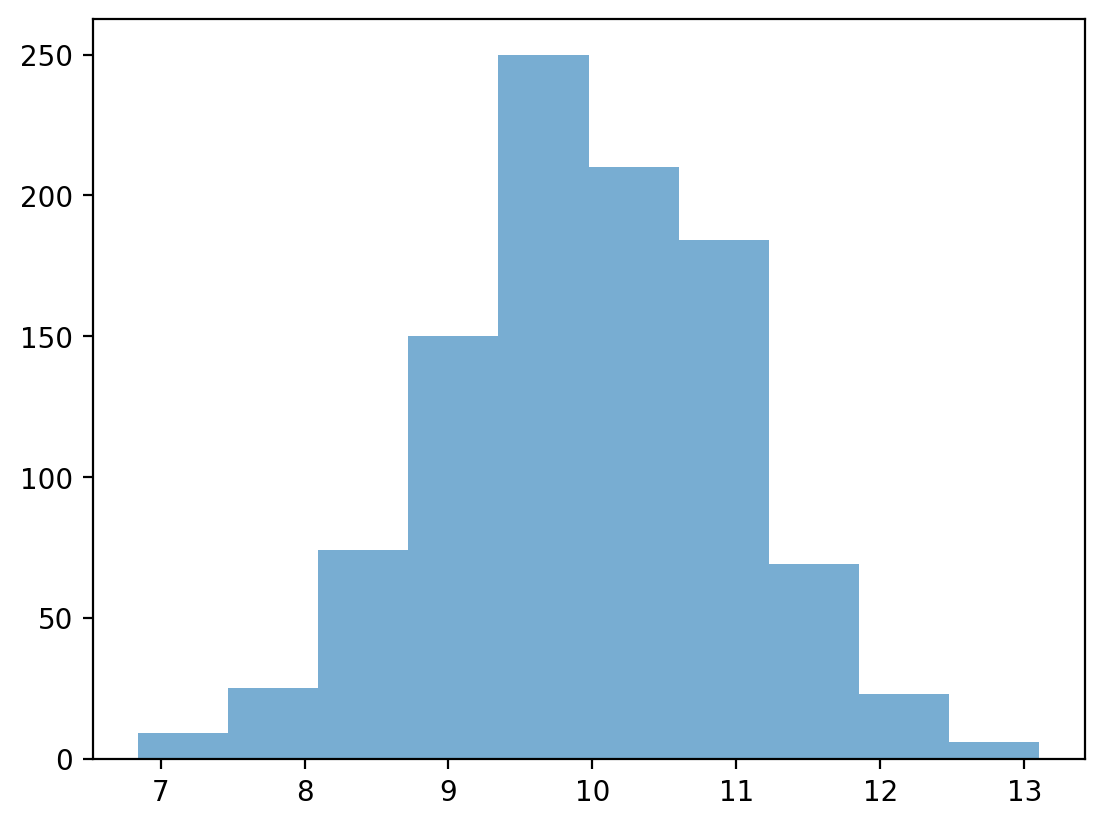
Skośne dane¶
Skośność oznacza, że istnieją wartości wydłużające jeden z „ogonów” rozkładu.
Skośność dodatnia/prawa: ogon jest skierowany w prawo.
Ujemny/lewy skośny: ogon jest skierowany w lewo.
rskew = ss.skewnorm.rvs(20, size = 1000) # tworzymy dane prawo-skośne
lskew = ss.skewnorm.rvs(-20, size = 1000) # tworzymy dane lewo-skośne
fig, axes = plt.subplots(1, 2)
axes[0].hist(rskew)
axes[0].set_title("Prawoskośne");
axes[1].hist(lskew)
axes[1].set_title("Lewoskośne");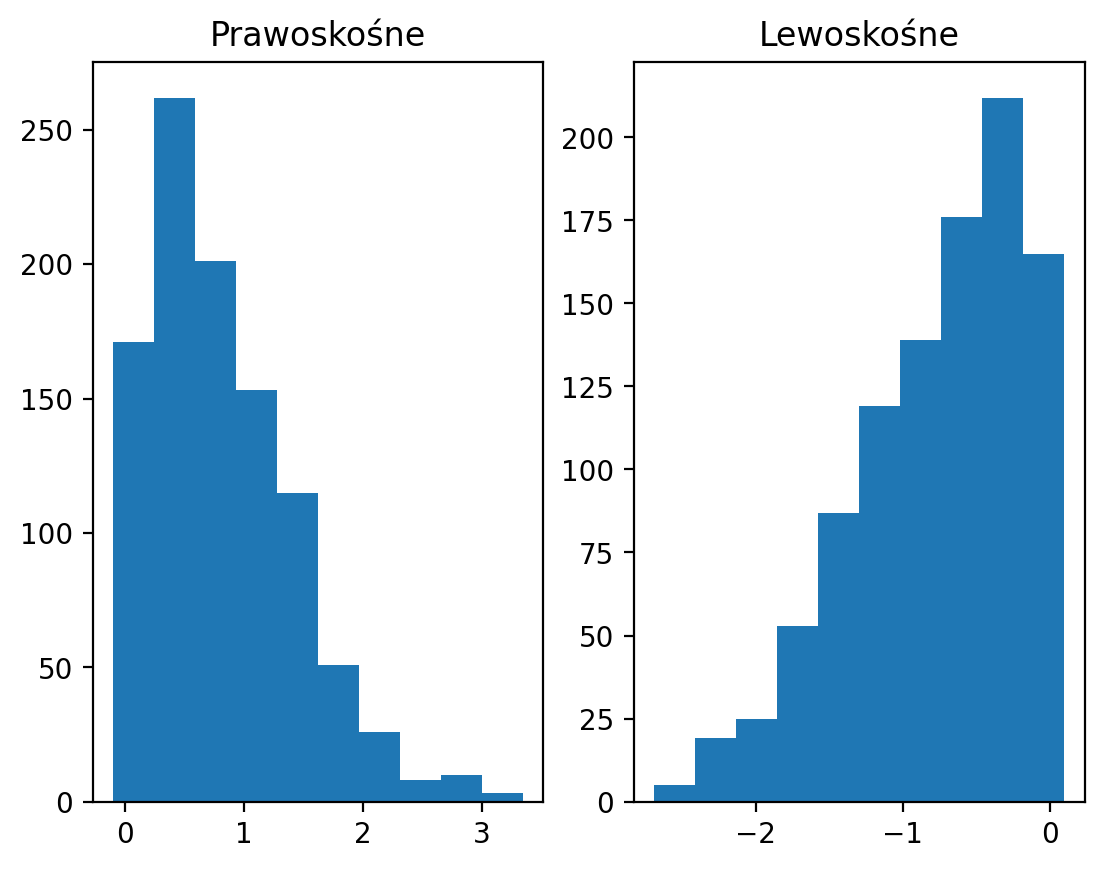
Punkty odstające¶
Punkty odstające to punkty danych, które znacznie różnią się od innych punktów w rozkładzie.
W przeciwieństwie do danych skośnych, wartości odstające są zazwyczaj nieciągłe w stosunku do reszty rozkładu.
W kolejnym rozdziale omówimy więcej sposobów identyfikacji wartości odstających; na razie możemy polegać na histogramach.
norm = np.random.normal(loc = 10, scale = 1, size = 1000)
upper_outliers = np.array([21, 21, 21, 21]) ## trochę odstających
data = np.concatenate((norm, upper_outliers))
p = plt.hist(data, alpha = .6)
plt.arrow(20, 100, dx = 0, dy = -50, width = .3, head_length = 10, facecolor = "red");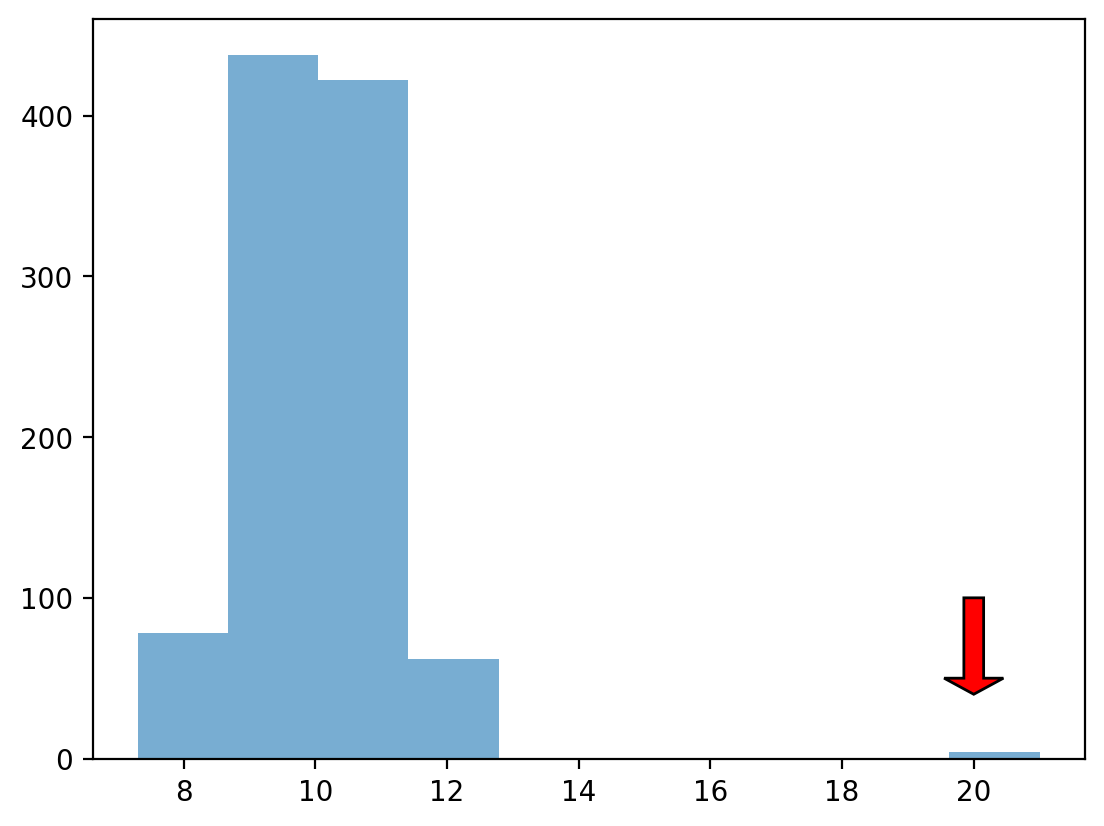
p = plt.hist(df_pokemon['HP'], alpha = .6)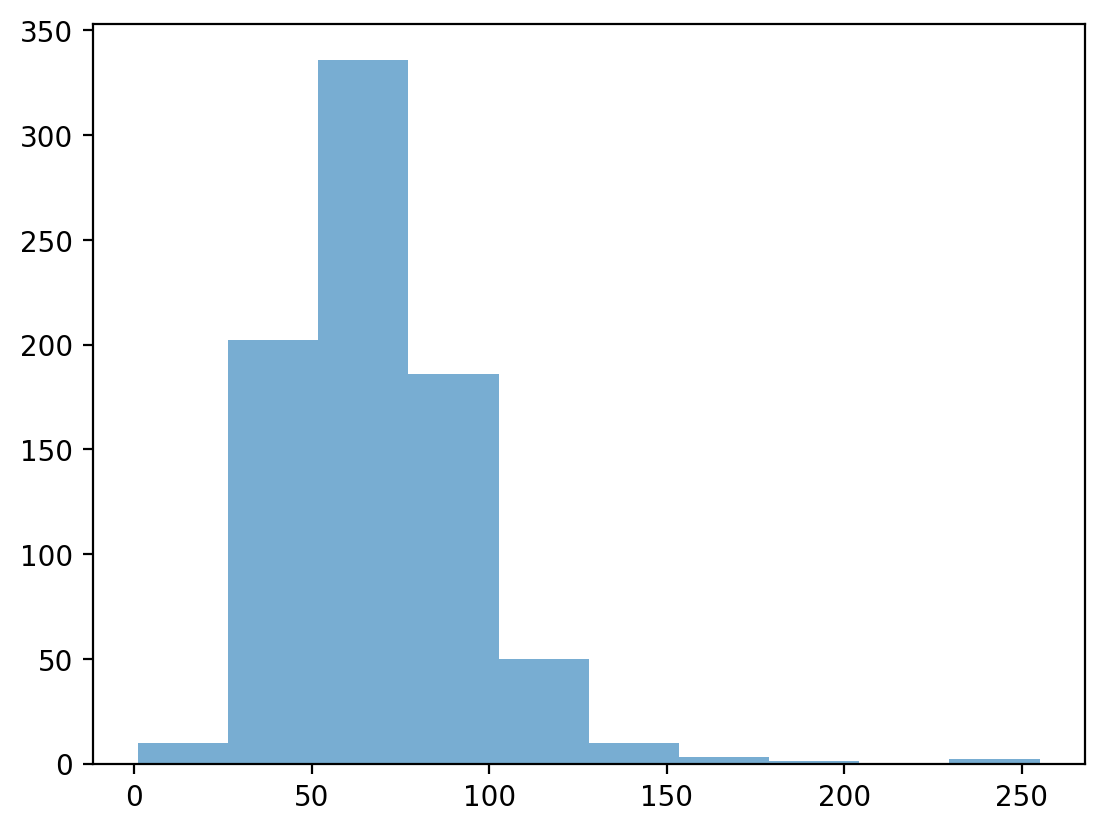
p = plt.hist(df_pokemon['Sp. Atk'], alpha = .6)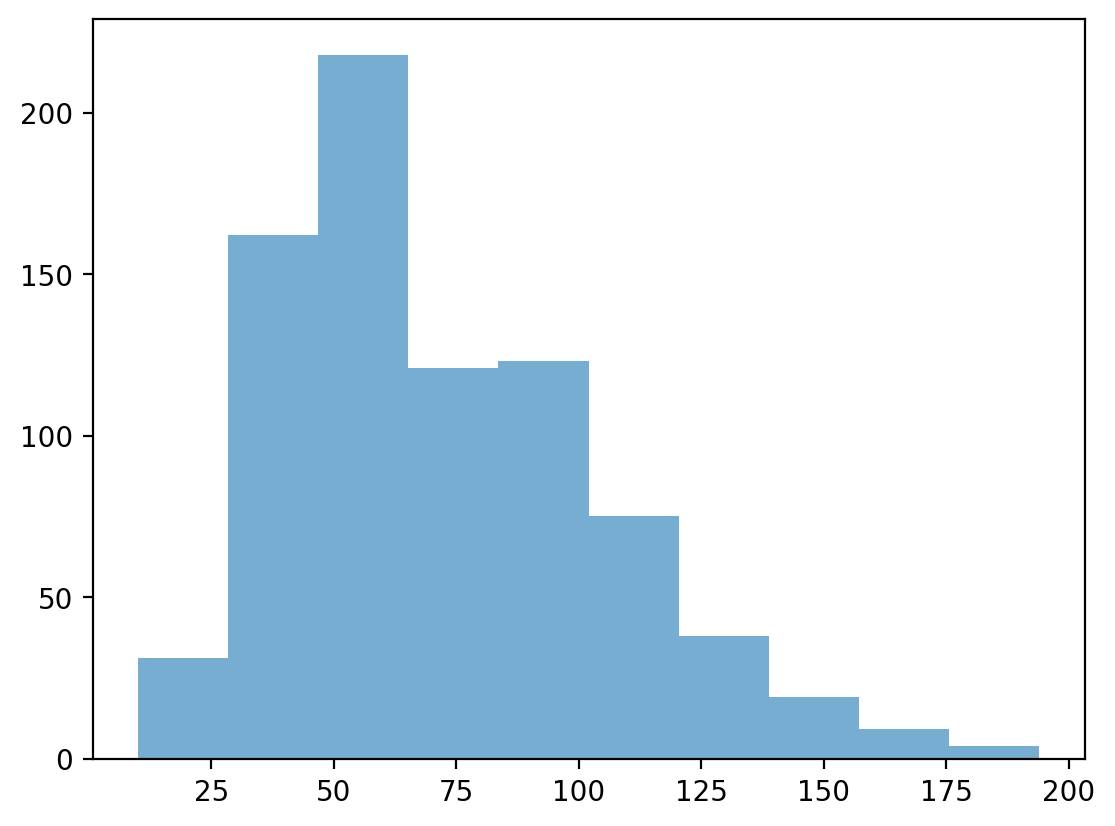
Sprawdź się¶
W nieco prawoskośnym rozkładzie (jak poniżej), co jest większe - średnia czy mediana?
p = plt.hist(df_pokemon['Sp. Atk'], alpha = .6)Rozwiązanie¶
Średnia jest najbardziej dotknięta skośnością, więc jest ciągnięta najdalej w prawo w rozkładzie prawoskośnym.
p = plt.hist(df_pokemon['Sp. Atk'], alpha = .6)
plt.axvline(df_pokemon['Sp. Atk'].mean(), linestyle = "dashed", color = "green");
plt.axvline(df_pokemon['Sp. Atk'].median(), linestyle = "dotted", color = "red");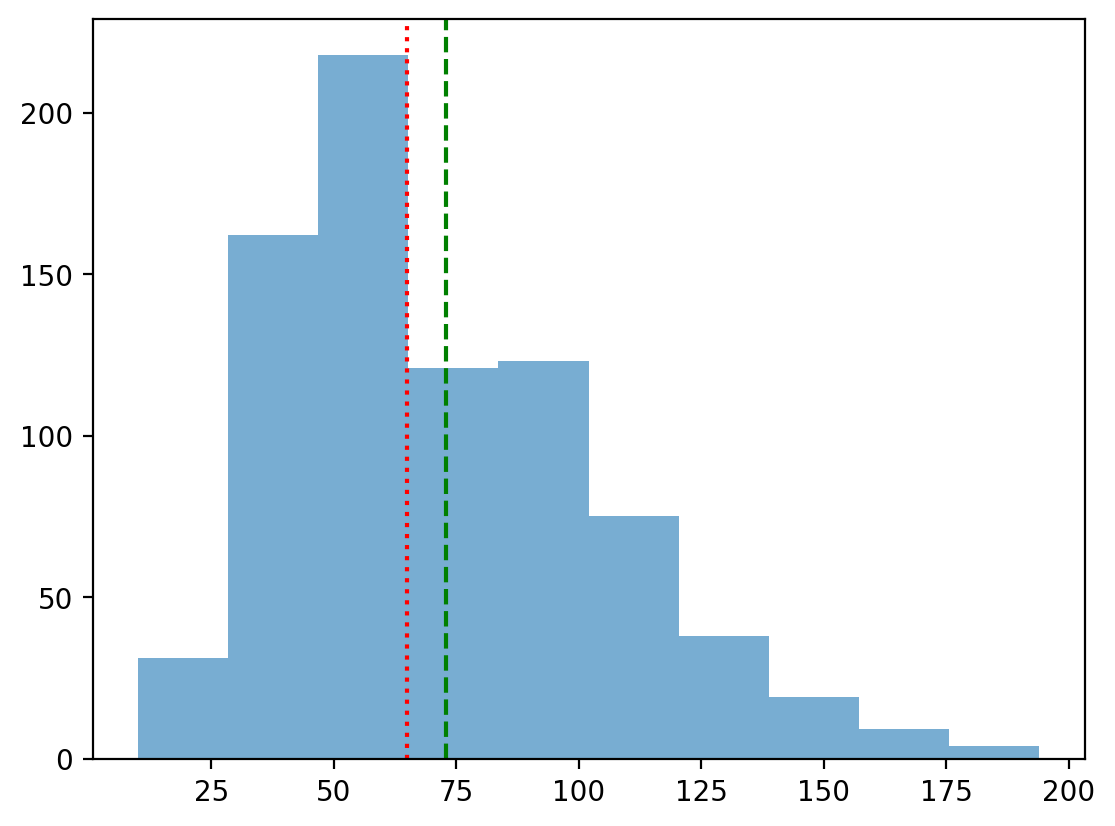
Modyfikacja naszego wykresu¶
Dobra wizualizacja danych powinna również wyjaśniać, co jest wykreślane.
Wyraźnie oznaczone osie
xiy, tytuł.
Czasami możemy również chcieć dodać nakładki.
Np. przerywaną pionową linię reprezentującą „średnią”.
Etykiety osi¶
p = plt.hist(df_pokemon['Attack'], alpha = .6)
plt.xlabel("Atak")
plt.ylabel("Liczebność")
plt.title("Rozkład punktów za atak");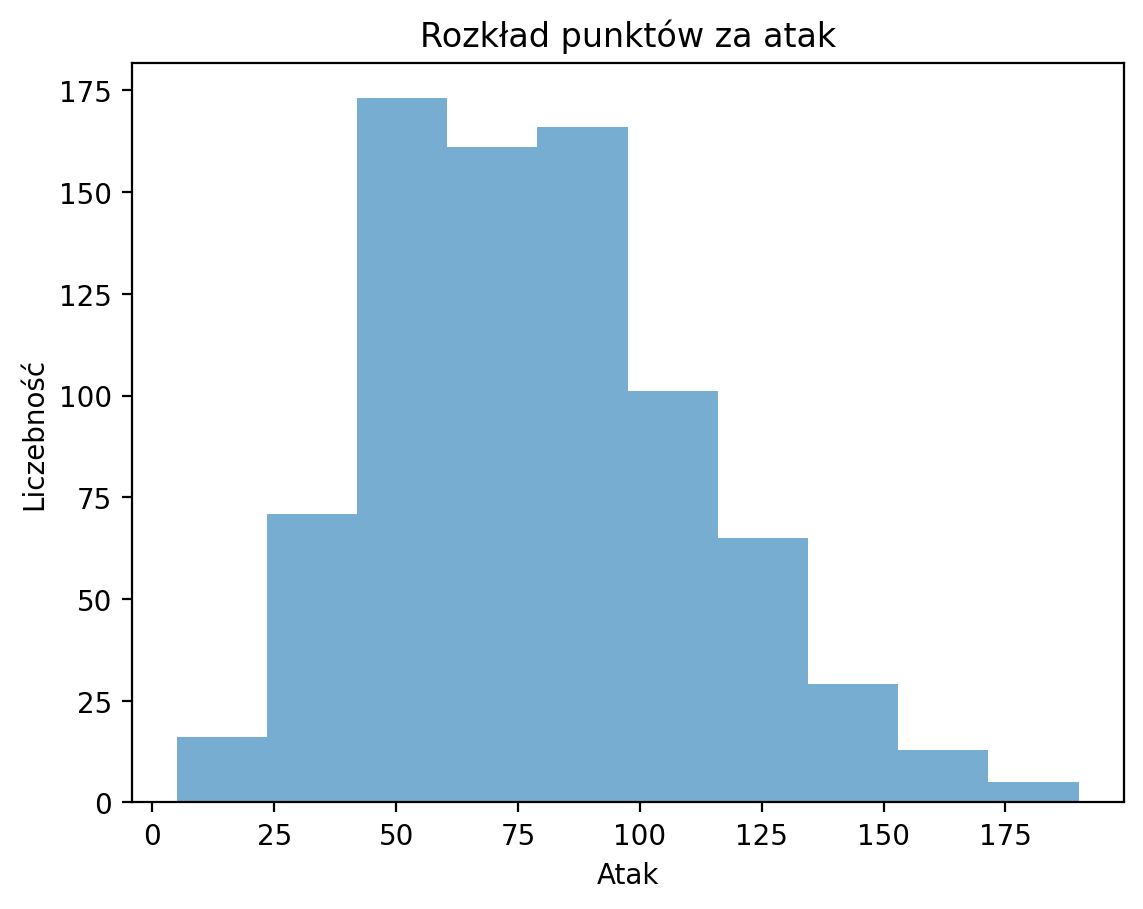
Linie pionowe¶
plt.axvline pozwala nam narysować pionową linię w określonej pozycji, np. średnią kolumny Attack.
p = plt.hist(df_pokemon['Attack'], alpha = .6)
plt.xlabel("Atak")
plt.ylabel("Liczebność")
plt.title("Rozkład liczby ataków")
plt.axvline(df_pokemon['Attack'].mean(), linestyle = "dotted");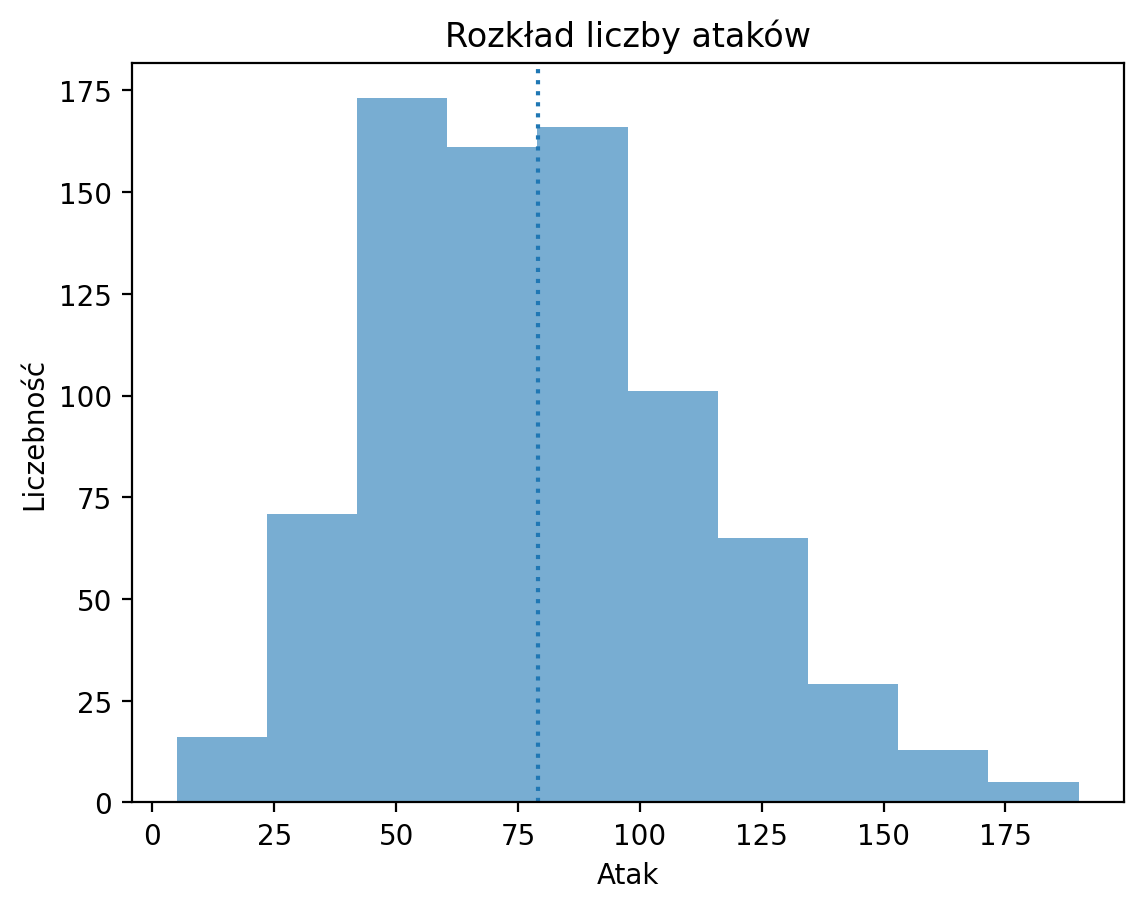
Histogramy z pyplot express¶
Z pyplot express równiez mozemy tworzyć histogramy:
import plotly.express as px
df = px.data.tips()
fig = px.histogram(df, x="total_bill")
fig.show()Z pyplot express mozemy narysować kilka histogramów dla różnych wartości jednej kolumny:
import plotly.express as px
df = px.data.tips()
fig = px.histogram(df, x="total_bill", color="sex")
fig.show()Grupowanie histogramów¶
Najciekawsze jest jednak kopanie w danych głębiej - tzw. faceting - grupowanie wykresów:
import plotly.express as px
df = px.data.tips()
fig = px.histogram(df, x="total_bill", y="tip", color="sex", facet_row="time", facet_col="day",
category_orders={"day": ["Thur", "Fri", "Sat", "Sun"], "time": ["Lunch", "Dinner"]})
fig.show()Wykresy rozrzutu¶
Czym są wykresy rozrzutu?¶
Wykres rozrzutu to wizualizacja tego, jak dwa różne rozkłady ciągłe odnoszą się do siebie.
Każdy pojedynczy punkt reprezentuje obserwację.
Bardzo przydatne do eksploracyjnej analizy danych.
Czy te zmienne są dodatnio czy ujemnie skorelowane?
Wykres rozrzutu jest wykresem dwuwymiarowym, tj. wyświetla co najmniej dwie zmienne.
Wykresy rozrzutu z matplotlib¶
Możemy utworzyć scatterplot używając plt.scatter(x, y), gdzie x i y to dwie zmienne, które chcemy wizualizować.
x = np.arange(1, 10)
y = np.arange(11, 20)
p = plt.scatter(x, y)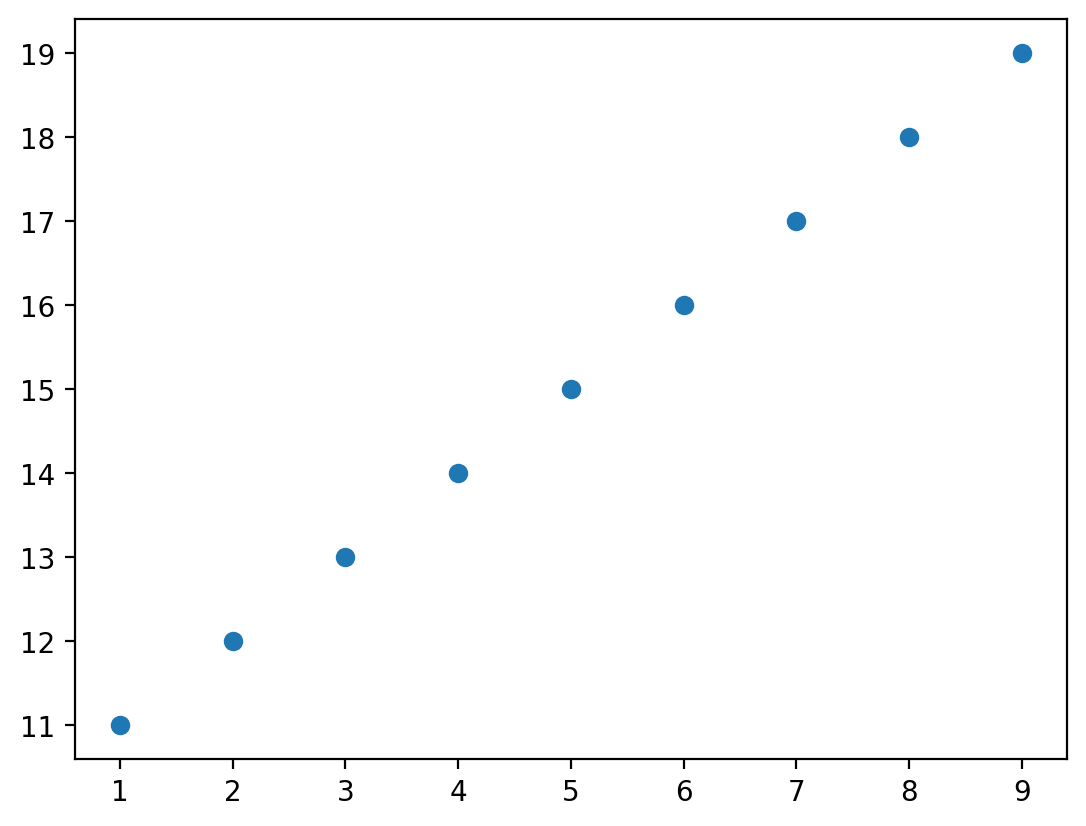
Sprawdź się¶
Czy te zmienne są ze sobą powiązane? Jeśli tak, to w jaki sposób?
x = np.random.normal(loc = 10, scale = 1, size = 100)
y = x * 2 + np.random.normal(loc = 0, scale = 2, size = 100)
plt.scatter(x, y, alpha = .6);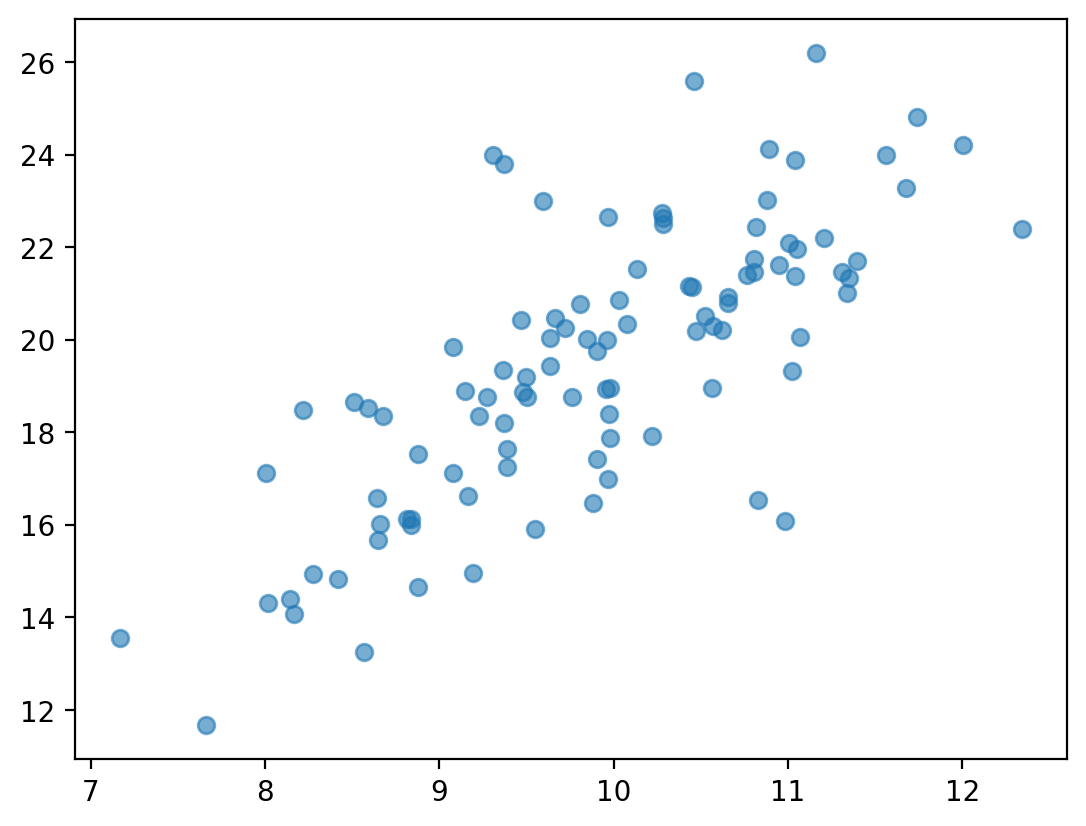
Sprawdź się¶
Czy te zmienne są ze sobą powiązane? Jeśli tak, to w jaki sposób?
x = np.random.normal(loc = 10, scale = 1, size = 100)
y = -x * 2 + np.random.normal(loc = 0, scale = 2, size = 100)
plt.scatter(x, y, alpha = .6);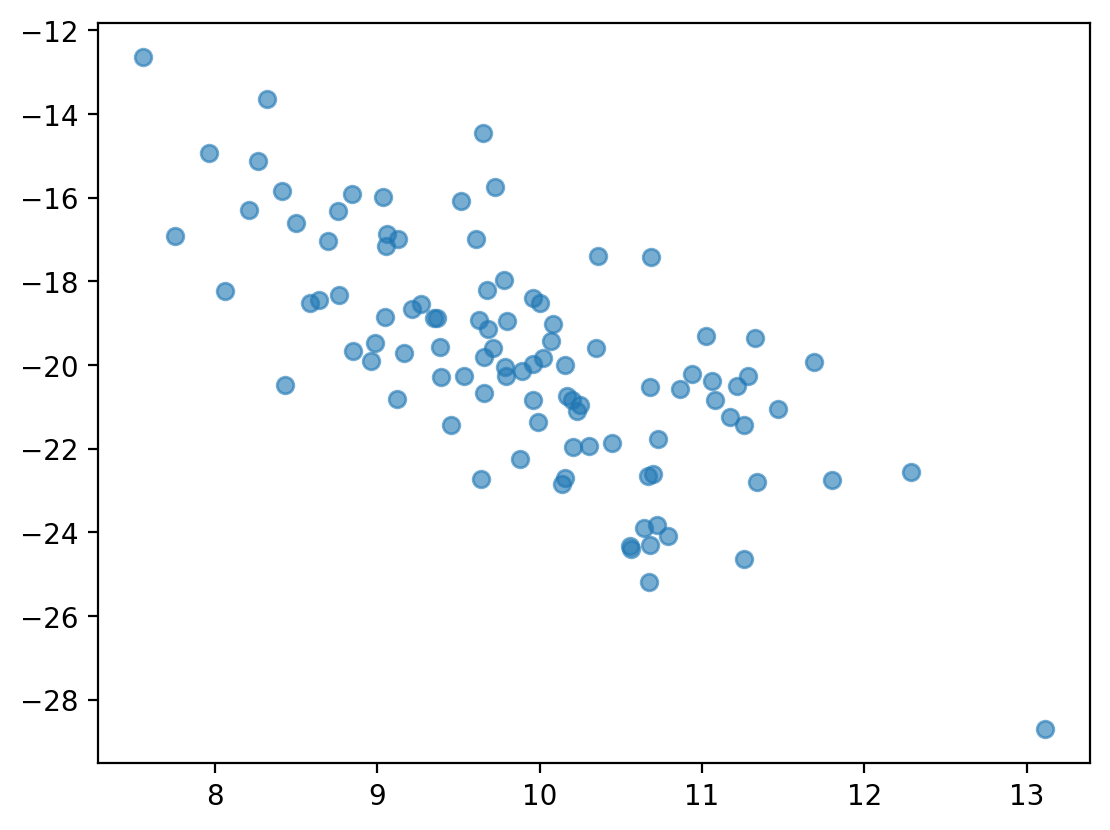
Wykrywanie zależności nieliniowych¶
x = np.random.normal(loc = 10, scale = 1, size = 100)
y = np.sin(x)
plt.scatter(x, y, alpha = .6);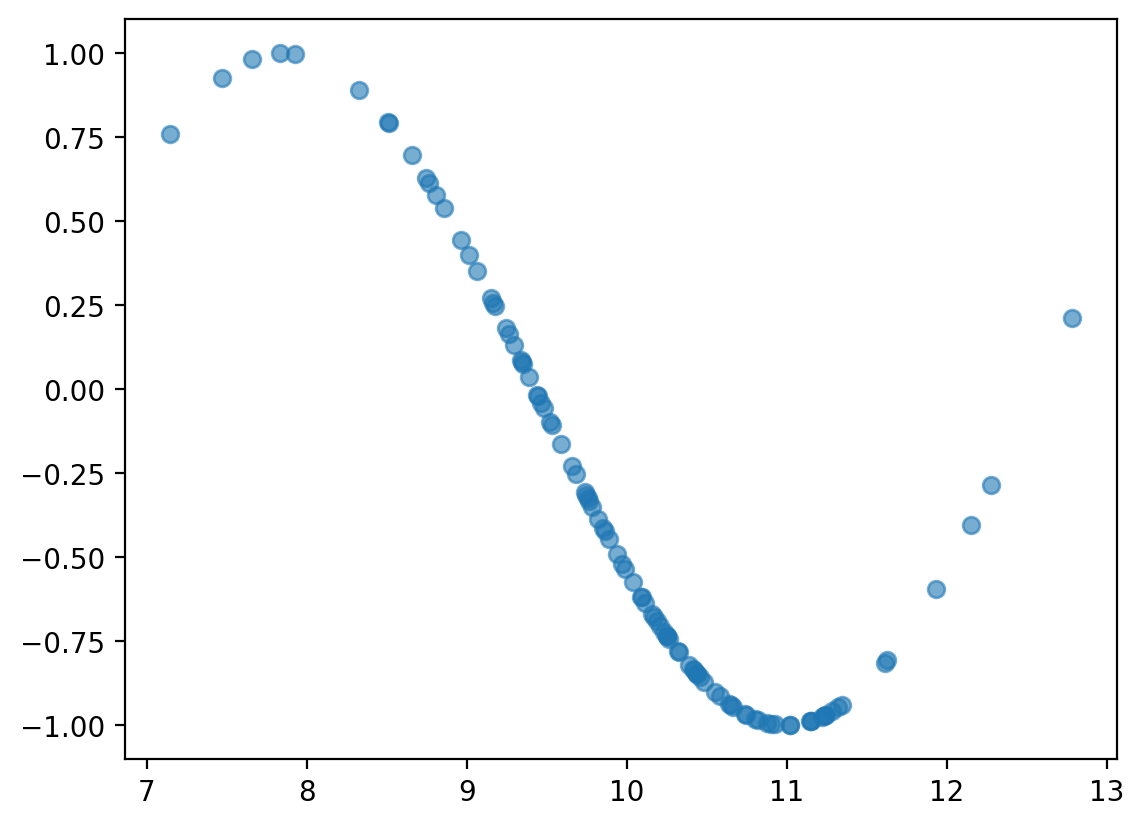
Sprawdź się¶
Jak moglibyśmy zwizualizować związek między Attack i Speed w naszym zbiorze danych Pokemonów?
### Twój kod tutajWykresy rozrzutu z pyplot express¶
Wykresy bąbelkowe¶
Wykresy punktowe z okrągłymi znacznikami o zmiennym rozmiarze są często nazywane wykresami bąbelkowymi. Należy pamiętać, że dane dotyczące koloru i rozmiaru są dodawane do informacji o najechaniu kursorem. Można dodać inne kolumny do danych najechania kursorem za pomocą argumentu hover_data w px.scatter.
import plotly.express as px
df = px.data.iris()
fig = px.scatter(df, x="sepal_width", y="sepal_length", color="species",
size='petal_length', hover_data=['petal_width'])
fig.show()Kolor może być ciągły, jak poniżej, lub dyskretny/kategorialny, jak powyżej.
df = px.data.iris()
fig = px.scatter(df, x="sepal_width", y="sepal_length", color='petal_length')
fig.show()Argument symbolu może być również mapowany na kolumnę. Dostępna jest szeroka gama symboli.
df = px.data.iris()
fig = px.scatter(df, x="sepal_width", y="sepal_length", color="species", symbol="species")
fig.show()Grupowane wykresy rozrzutu¶
Wykresy rozrzutu wspierają grupowanie - tzw. faceting.
df = px.data.tips()
fig = px.scatter(df, x="total_bill", y="tip", color="smoker", facet_col="sex", facet_row="time")
fig.show()Dodawanie linii¶
Na wykres rozrzutu nałozyć mozna oszacowaną funkcję liniową:
df = px.data.tips()
fig = px.scatter(df, x="total_bill", y="tip", trendline="ols")
fig.show()Wykresy słupkowe¶
Czym jest barplot?¶
Wykres słupkowy wizualizuje związek pomiędzy jedną zmienną ciągłą a zmienną kategorialną.
Wysokość każdego słupka zazwyczaj wskazuje średnią zmiennej ciągłej.
Każdy słupek reprezentuje inny poziom zmiennej kategorialnej.
Wykres słupkowy jest wykresem dwuwymiarowym, tj. wyświetla co najmniej dwie zmienne.
Wykresy słupkowe z matplotlib¶
plt.bar może być użyty do stworzenia wykresu słupkowego naszych danych.
Na przykład, średni
AttackwedługLegendarnegostatusu.Jednak najpierw musimy użyć
groupby, aby obliczyć średniąAttackna poziom.
Krok 1: Wykorzystanie groupby¶
summary = df_pokemon[['Legendary', 'Attack']].groupby("Legendary").mean().reset_index()
summary### Zmiana "Legendary" na str
summary['Legendary'] = summary['Legendary'].apply(lambda x: str(x))
summaryKrok 2: Przekazanie wartości na plt.bar¶
Sprawdź się:
Czego dowiadujemy się z tego wykresu?
Czego brakuje w tej opowieści?
plt.bar(x = summary['Legendary'],
height = summary['Attack'],
alpha = .6)
plt.xlabel("Status")
plt.ylabel("Atak")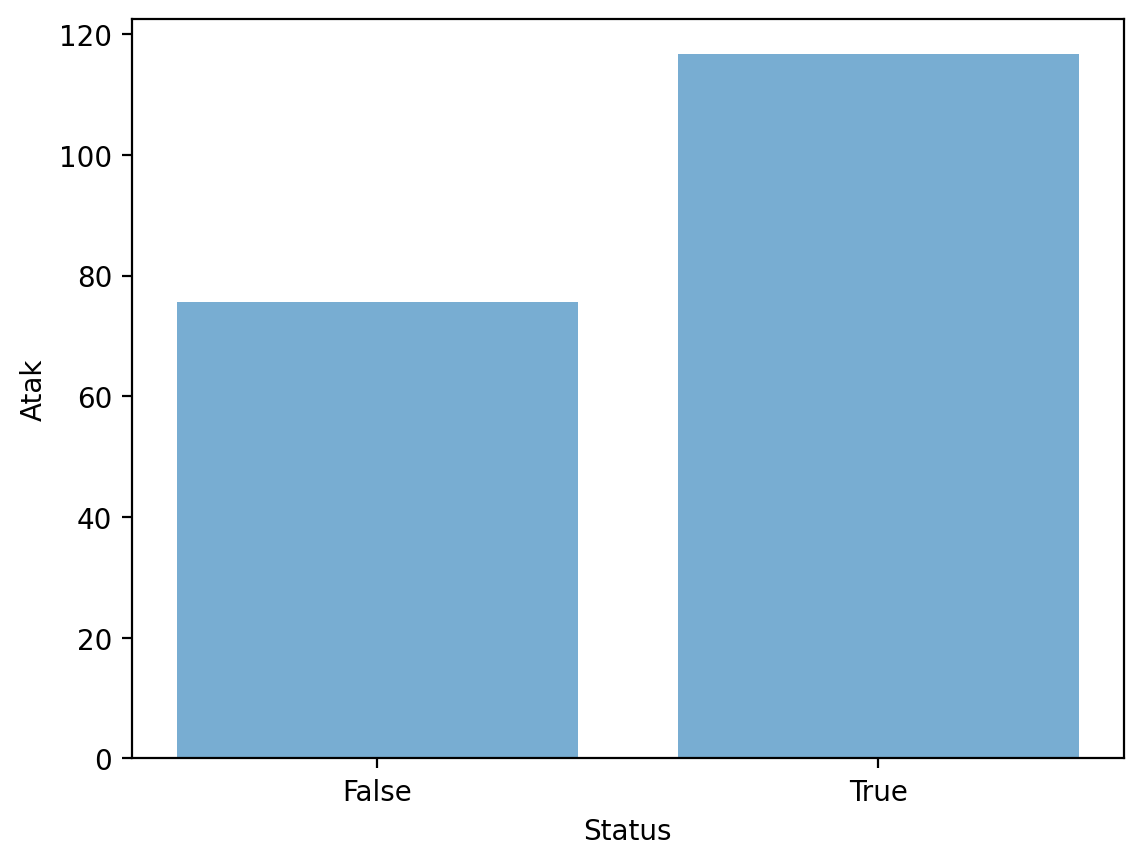
Plotly express¶
Plotly Express to łatwy w użyciu, wysokopoziomowy interfejs do Plotly, który działa na różnych typach danych i tworzy łatwe do stylizacji wykresy.
Dzięki px.bar każdy wiersz ramki DataFrame jest reprezentowany jako prostokątny znak. Aby zagregować wiele punktów danych w ten sam prostokątny znak, należy zapoznać się z dokumentacją histogramu.
W poniższym przykładzie jest tylko jeden wiersz danych na rok, więc wyświetlany jest jeden słupek na rok.
import plotly.express as px
data_canada = px.data.gapminder().query("country == 'Canada'")
fig = px.bar(data_canada, x='year', y='pop')
fig.show()Wykresy słupkowe z danymi w formacie long¶
Dane w długim formacie mają jeden wiersz na obserwację i jedną kolumnę na zmienną. Jest to odpowiednie do przechowywania i wyświetlania danych wielowymiarowych, tj. o wymiarze większym niż 2. Format ten jest czasami nazywany „uporządkowanym”.
Aby dowiedzieć się więcej o tym, jak dostarczyć konkretną formę danych zorientowanych na kolumny do funkcji 2D-Cartesian Plotly Express, takich jak px.bar, zobacz dokumentację Plotly Express Wide-Form Support in Python.
long_df = px.data.medals_long()
fig = px.bar(long_df, x="nation", y="count", color="medal", title="Dane w formacie long")
fig.show()Podejrzyjmy dane:
long_dfWykresy słupkowe z danymi w formacie wide¶
Dane w szerokim formacie mają jeden wiersz na wartość jednej z pierwszych zmiennych i jedną kolumnę na wartość drugiej zmiennej.
Jest to odpowiednie do przechowywania i wyświetlania danych dwuwymiarowych.
wide_df = px.data.medals_wide()
fig = px.bar(wide_df, x="nation", y=["gold", "silver", "bronze"], title="Dane w formacie wide")
fig.show()Zobaczmy jak wyglądają dane w formacie wide:
wide_dfKolorowane słupki¶
Wykres słupkowy można dostosować za pomocą argumentów słów kluczowych, na przykład w celu użycia koloru ciągłego, jak poniżej, lub koloru dyskretnego, jak powyżej.
df = px.data.gapminder().query("country == 'Poland'")
fig = px.bar(df, x='year', y='pop',
hover_data=['lifeExp', 'gdpPercap'], color='lifeExp',
labels={'pop':'ludność w Polsce'}, height=400)
fig.show()df = px.data.gapminder().query("continent == 'Oceania'")
fig = px.bar(df, x='year', y='pop',
hover_data=['lifeExp', 'gdpPercap'], color='country',
labels={'pop':'population of Canada'}, height=400)
fig.show()Stos vs grupowane słupki¶
Gdy kilka wierszy ma tę samą wartość x (tutaj Kobieta lub Mężczyzna), prostokąty są domyślnie ułożone jeden na drugim.
df = px.data.tips()
fig = px.bar(df, x="sex", y="total_bill", color='time')
fig.show()Domyślne zachowanie skumulowanego wykresu słupkowego można zmienić na zgrupowane (znane również jako klastrowane) za pomocą argumentu barmode:
df = px.data.tips()
fig = px.bar(df, x="sex", y="total_bill",
color='smoker', barmode='group',
height=400)
fig.show()Grupowanie wykresów słupkowych¶
Użycie argumentów słowa kluczowego facet_row (lub facet_col), utworzy nam grupowane subploty, w których różne wiersze (lub kolumny) odpowiadają różnym wartościom kolumny ramki danych określonej w facet_row.
df = px.data.tips()
fig = px.bar(df, x="sex", y="total_bill", color="smoker", barmode="group",
facet_row="time", facet_col="day",
category_orders={"day": ["Thur", "Fri", "Sat", "Sun"],
"time": ["Lunch", "Dinner"]})
fig.show()