Abstract¶
This Jupyter Notebook provides a comprehensive introduction to time series modeling, focusing on techniques for analyzing, visualizing, and forecasting temporal data. It begins with essential concepts such as time series components (trend, seasonality, and noise) and exploratory data analysis. The notebook then explores statistical modeling approaches including Autoregressive (AR), Moving Average (MA), ARIMA, and seasonal ARIMA (SARIMA) models.
Autoregressive models¶
Autoregressive (AR) models:
where is white noise. This is a multiple regression with lagged values of as predictors.
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(1)
n = 100
# AR(1)
ar1 = [10]
for t in range(1, n):
ar1.append(-0.8 * ar1[-1] + np.random.normal())
ar1 = np.array(ar1)
# AR(2)
ar2 = [20, 20]
for t in range(2, n):
ar2.append(1.3 * ar2[-1] - 0.7 * ar2[-2] + np.random.normal())
ar2 = np.array(ar2)
fig, axs = plt.subplots(1, 2, figsize=(12, 3))
axs[0].plot(ar1)
axs[0].set_title("AR(1)")
axs[1].plot(ar2)
axs[1].set_title("AR(2)")
plt.show()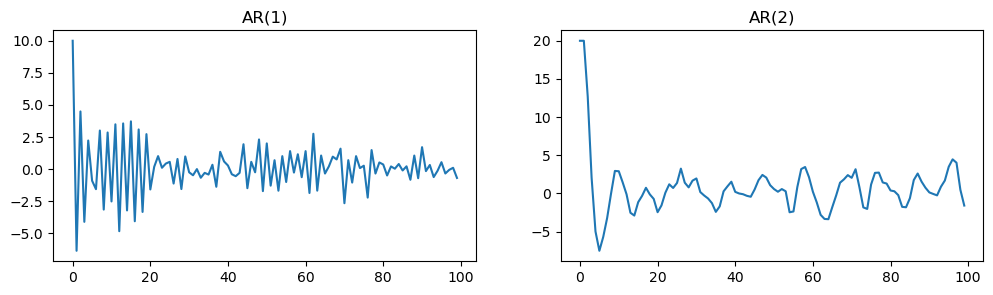
Summary: AR(1) and AR(2) Simulation¶
The previous code simulates two types of autoregressive time series: AR(1) and AR(2).
The AR(1) process shows rapid oscillations due to strong negative correlation with its previous value, while the AR(2) process exhibits more complex, cyclical behavior influenced by its two preceding values.
The resulting plots help illustrate how the structure and parameters of autoregressive models affect the patterns observed in time series data.
np.random.seed(1)
n = 100
y = [2]
for t in range(1, n):
y.append(2 - 0.8 * y[-1] + np.random.normal())
y = np.array(y)
plt.figure(figsize=(4, 2.2))
plt.plot(y, color='tab:blue')
plt.title(r"$y_t = 2 - 0.8\, y_{t-1} + \varepsilon_t$")
plt.xlabel("t")
plt.ylabel("$y_t$")
plt.tight_layout()
plt.show()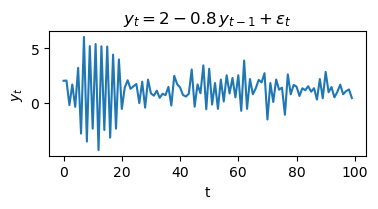
Interpretation: AR(1) process simulation¶
The code above simulates a first-order autoregressive process (AR(1)) defined by the equation:
where is random noise from a normal distribution.
Each value in the series depends on the previous value, a constant (2), and random noise.
The negative coefficient (-0.8) causes the series to oscillate, often switching direction from one step to the next.
The plot shows how the process evolves over time, illustrating the typical behavior of an AR(1) model with a negative coefficient and a nonzero intercept.
AR(1) model¶
When , is equivalent to white noise (WN).
When and , is equivalent to a random walk (RW).
When and , is equivalent to a random walk with drift.
When , tends to oscillate between positive and negative values.
np.random.seed(1)
n = 100
y = [8, 8]
for t in range(2, n):
y.append(8 + 1.3 * y[-1] - 0.7 * y[-2] + np.random.normal())
y = np.array(y)
plt.figure(figsize=(4, 2.2))
plt.plot(y, color='tab:orange')
plt.title(r"$y_t = 8 + 1.3\, y_{t-1} - 0.7\, y_{t-2} + \varepsilon_t$")
plt.xlabel("t")
plt.ylabel("$y_t$")
plt.tight_layout()
plt.show()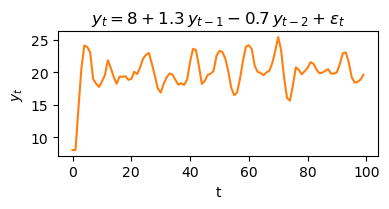
Interpretation: AR(2) process simulation¶
The code above simulates a second-order autoregressive process (AR(2)) defined by the equation:
where is random noise from a normal distribution.
Each value in the series depends on the two previous values, a constant (8), and random noise.
The combination of positive and negative coefficients (1.3 and -0.7) creates more complex, cyclical patterns in the time series.
The plot shows how the process evolves over time, illustrating the typical behavior of an AR(2) model with oscillations and possible cycles.
Stationarity conditions¶
We normally restrict autoregressive models to stationary data, and then some constraints on the values of the parameters are required.
General condition for stationarity:
The complex roots of must lie outside the unit circle in the complex plane.
For : .
For : .
More complicated conditions hold for .
Estimation software will check these conditions automatically.
Moving Average (MA) models¶
Moving Average (MA) models:
where is white noise.
This is a multiple regression with past errors as predictors.
Don’t confuse this with moving average smoothing!
np.random.seed(2)
n = 100
# MA(1)
e = np.random.normal(size=n)
ma1 = 20 + e + 0.8 * np.roll(e, 1)
ma1[0] = 20 + e[0] # first value, since e[-1] is not defined
# MA(2)
e2 = np.random.normal(size=n)
ma2 = e2 + (-1) * np.roll(e2, 1) + 0.8 * np.roll(e2, 2)
ma2[0:2] = e2[0:2] # first two values, since e2[-1], e2[-2] not defined
fig, axs = plt.subplots(1, 2, figsize=(12, 3))
axs[0].plot(ma1)
axs[0].set_title("MA(1)")
axs[1].plot(ma2)
axs[1].set_title("MA(2)")
plt.show()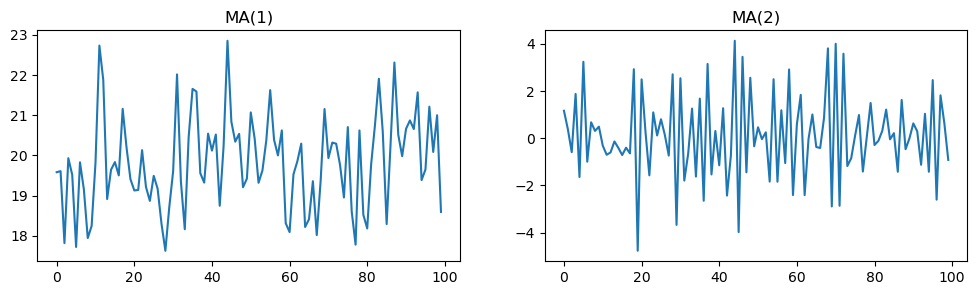
Interpretation: MA(1) and MA(2) process simulation¶
The code above simulates and plots two moving average (MA) time series processes:
MA(1): Each value depends on the current random noise and the previous noise, plus a constant (20). The coefficient 0.8 determines the influence of the previous noise term.
MA(2): Each value depends on the current noise, the previous noise (with coefficient -1), and the noise from two steps back (with coefficient 0.8).
The resulting plots show how moving average models generate time series with short-term dependencies, where each value is a weighted sum of recent random shocks. The MA(1) process exhibits short memory, while the MA(2) process can display more complex short-term patterns due to the influence of two past noise terms.
np.random.seed(2)
n = 100
e = np.random.normal(size=n)
ma1 = 20 + e + 0.8 * np.roll(e, 1)
ma1[0] = 20 + e[0] # first value, since e[-1] is not defined
plt.figure(figsize=(4, 2.2))
plt.plot(ma1, color='tab:green')
plt.title(r"$y_t = 20 + \varepsilon_t + 0.8\, \varepsilon_{t-1}$")
plt.xlabel("t")
plt.ylabel("$y_t$")
plt.tight_layout()
plt.show()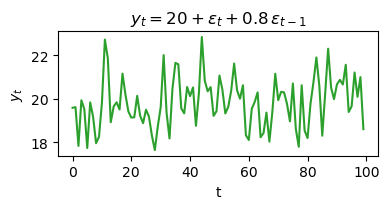
Interpretation: MA(1) process simulation¶
The code above simulates a first-order moving average process (MA(1)) defined by the equation:
where is random noise from a normal distribution.
Each value in the series depends on the current random shock, the previous shock (weighted by 0.8), and a constant (20).
The process exhibits short-term dependencies, meaning each value is influenced by recent random fluctuations.
The plot shows how the MA(1) process evolves over time, typically displaying less persistent patterns than autoregressive processes.
np.random.seed(2)
n = 100
e = np.random.normal(size=n)
ma2 = e + (-1) * np.roll(e, 1) + 0.8 * np.roll(e, 2)
ma2[0:2] = e[0:2] # first two values, since e[-1], e[-2] not defined
plt.figure(figsize=(4, 2.2))
plt.plot(ma2, color='tab:purple')
plt.title(r"$y_t = \varepsilon_t - \varepsilon_{t-1} + 0.8\, \varepsilon_{t-2}$")
plt.xlabel("t")
plt.ylabel("$y_t$")
plt.tight_layout()
plt.show()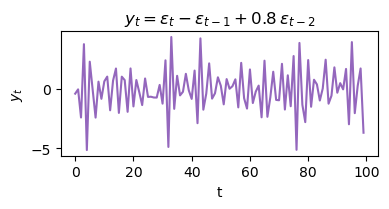
Interpretation: MA(2) process simulation¶
The code above simulates a second-order moving average process (MA(2)) defined by the equation:
where is random noise from a normal distribution.
Each value in the series depends on the current noise, the previous noise (with coefficient -1), and the noise from two steps back (with coefficient 0.8).
This structure creates short-term dependencies and more complex short-term patterns than MA(1).
The plot shows how the MA(2) process evolves over time, illustrating the typical behavior of a model with two lagged noise components.
MA() models¶
It is possible to write any stationary AR() process as an MA() process.
Example: AR(1)
Provided :
Invertibility¶
Any MA() process can be written as an AR() process if we impose some constraints on the MA parameters.
Then the MA model is called “invertible”.
Invertible models have some mathematical properties that make them easier to use in practice.
Invertibility of an ARIMA model is equivalent to forecastability of an ETS model.
Invertibility¶
General condition for invertibility:
The complex roots of must lie outside the unit circle in the complex plane.
For : .
For : .
More complicated conditions hold for .
Estimation software will check these conditions automatically.
ARIMA models¶
Autoregressive Moving Average models:
Predictors include both lagged values of and lagged errors.
Conditions on coefficients ensure stationarity.
Conditions on coefficients ensure invertibility.
Combine ARMA model with differencing.
follows an ARMA model.
ARIMA models¶
Autoregressive Integrated Moving Average models
ARIMA() model:
| Component | Description |
|---|---|
| AR | order of the autoregressive part |
| I | degree of differencing |
| MA | order of the moving average part |
White noise model: ARIMA(0,0,0)
Random walk: ARIMA(0,1,0) with no constant
Random walk with drift: ARIMA(0,1,0) with constant
AR(): ARIMA(,0,0)
MA(): ARIMA(0,0,)
European quarterly retail trade¶
import pandas as pd
euretail = pd.read_csv('data/euretail.csv')
# Convert 'time' to float
euretail['time'] = euretail['time'].astype(float)
# Extract year and quarter from 'time'
years = euretail['time'].astype(int)
quarters = ((euretail['time'] % 1) * 4 + 1).astype(int)
# Use PeriodIndex.from_fields to avoid the warning
euretail['quarter'] = pd.PeriodIndex([f"{y}Q{q}" for y, q in zip(years, quarters)], freq='Q')
# Set the quarterly index
euretail.set_index('quarter', inplace=True)
euretail = euretail.drop(columns=['rownames', 'time'])
print(euretail.head())
print(euretail.index)
print(type(euretail.index)) value
quarter
1996Q1 89.13
1996Q2 89.52
1996Q3 89.88
1996Q4 90.12
1997Q1 89.19
PeriodIndex(['1996Q1', '1996Q2', '1996Q3', '1996Q4', '1997Q1', '1997Q2',
'1997Q3', '1997Q4', '1998Q1', '1998Q2', '1998Q3', '1998Q4',
'1999Q1', '1999Q2', '1999Q3', '1999Q4', '2000Q1', '2000Q2',
'2000Q3', '2000Q4', '2001Q1', '2001Q2', '2001Q3', '2001Q4',
'2002Q1', '2002Q2', '2002Q3', '2002Q4', '2003Q1', '2003Q2',
'2003Q3', '2003Q4', '2004Q1', '2004Q2', '2004Q3', '2004Q4',
'2005Q1', '2005Q2', '2005Q3', '2005Q4', '2006Q1', '2006Q2',
'2006Q3', '2006Q4', '2007Q1', '2007Q2', '2007Q3', '2007Q4',
'2008Q1', '2008Q2', '2008Q3', '2008Q4', '2009Q1', '2009Q2',
'2009Q3', '2009Q4', '2010Q1', '2010Q2', '2010Q3', '2010Q4',
'2011Q1', '2011Q2', '2011Q3', '2011Q4'],
dtype='period[Q-DEC]', name='quarter')
<class 'pandas.core.indexes.period.PeriodIndex'>
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 4))
plt.plot(euretail.index.to_timestamp(), euretail['value']) # Convert PeriodIndex to Timestamp for plotting
plt.xlabel("Year")
plt.ylabel("Retail index")
plt.title("European quarterly retail trade")
plt.tight_layout()
plt.show()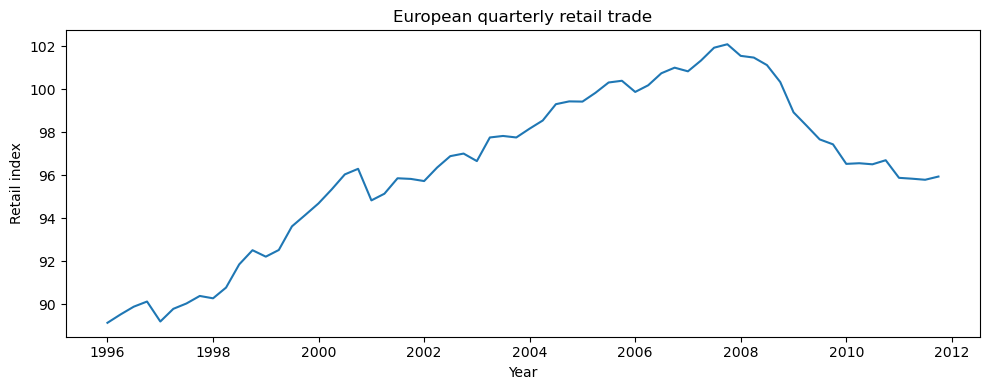
Your turn!¶
Interpret the following plots:
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
# Use euretail directly (no need for euretail_plot)
# Perform seasonal differencing with lag=4 (for quarterly seasonality)
euretail_diff = euretail['value'].diff(4).dropna()
# Ensure the index matches the differenced data for correct x-axis
euretail_diff.index = euretail.index[4:]
# Determine max lags to avoid overshooting with small datasets
max_lags = min(20, len(euretail_diff) // 2 - 1)
# Plotting
fig, axes = plt.subplots(3, 1, figsize=(10, 8))
# 1. Plot the seasonally differenced series
axes[0].plot(euretail_diff.index.to_timestamp(), euretail_diff)
axes[0].set_title("Seasonally Differenced Series (lag=4)")
axes[0].set_ylabel("Difference")
# 2. Plot ACF
plot_acf(euretail_diff, ax=axes[1], lags=max_lags)
axes[1].set_title("ACF of Seasonally Differenced Series")
# 3. Plot PACF
plot_pacf(euretail_diff, ax=axes[2], lags=max_lags, method='ywm')
axes[2].set_title("PACF of Seasonally Differenced Series")
plt.tight_layout()
plt.show()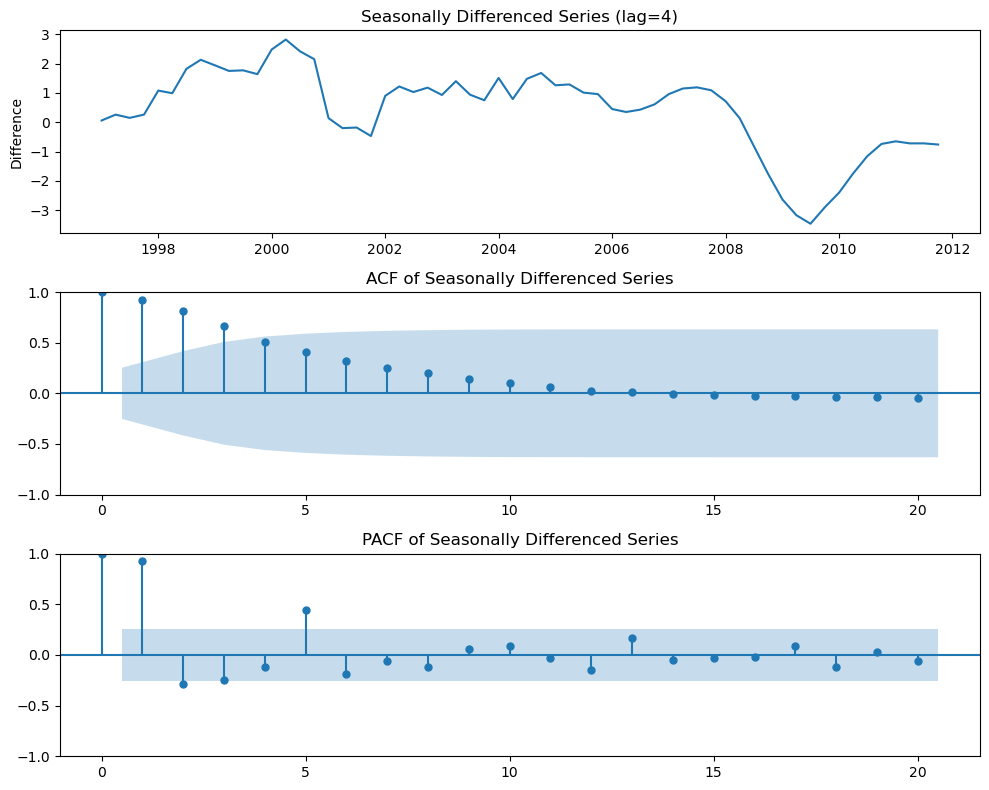
import matplotlib.pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
# Double differencing: first seasonal (lag=4), then regular (lag=1)
euretail_diff2 = euretail['value'].diff(4).diff().dropna()
# Align the index for correct x-axis labeling
euretail_diff2.index = euretail.index[5:]
max_lags = min(20, len(euretail_diff2) // 2 - 1) # Ensure lags < 50% of sample size
fig, axes = plt.subplots(3, 1, figsize=(10, 8))
# Plot the double differenced series with correct time axis
axes[0].plot(euretail_diff2.index.to_timestamp(), euretail_diff2)
axes[0].set_title("Double differenced series (seasonal lag=4, then lag=1)")
axes[0].set_ylabel("Difference")
# ACF plot
plot_acf(euretail_diff2, ax=axes[1], lags=max_lags)
axes[1].set_title("ACF of double differenced series")
# PACF plot
plot_pacf(euretail_diff2, ax=axes[2], lags=max_lags, method='ywm')
axes[2].set_title("PACF of double differenced series")
plt.tight_layout()
plt.show()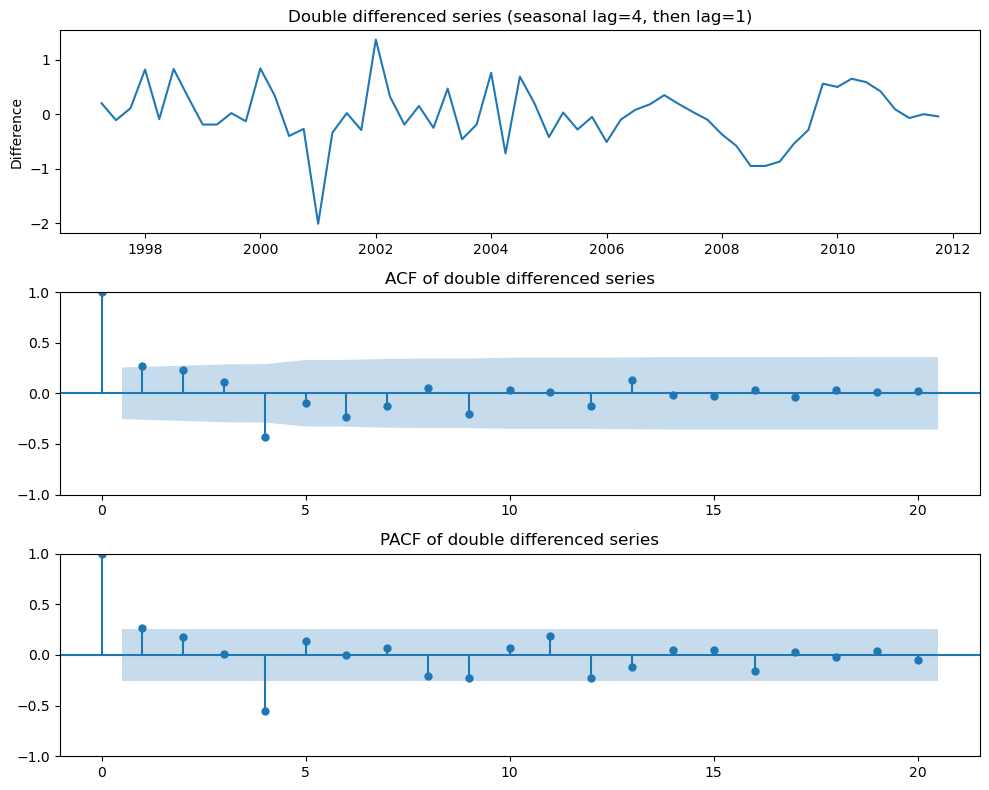
European quarterly retail trade¶
and seems necessary.
Significant spike at lag 1 in ACF suggests non-seasonal MA(1) component.
Significant spike at lag 4 in ACF suggests seasonal MA(1) component.
Initial candidate model: ARIMA(0,1,1)(0,1,1).
We could also have started with ARIMA(1,1,0)(1,1,0).
import statsmodels.api as sm
# Try a simpler model, e.g., no seasonal part
model = sm.tsa.SARIMAX(
euretail['value'],
order=(0, 1, 1),
seasonal_order=(0, 0, 0, 0),
enforce_stationarity=False,
enforce_invertibility=False
)
fit = model.fit(disp=False)
fit.plot_diagnostics(figsize=(10, 6))
plt.tight_layout()
plt.show()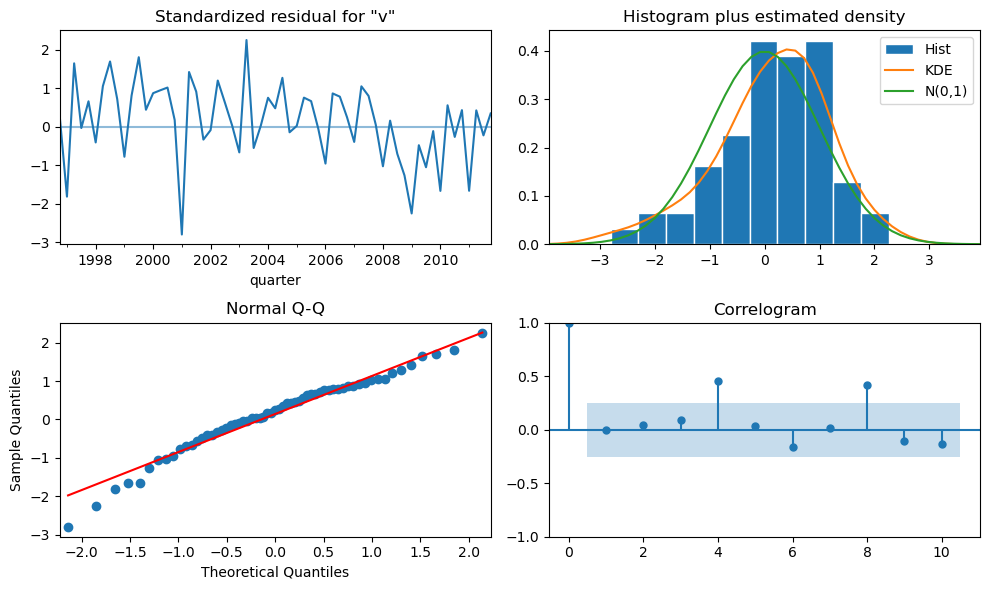
Interpretation: SARIMA(0,1,1)(0,0,0)[4] model (no seasonal part)¶
The code above fits a simple SARIMA model to the European quarterly retail trade data, with the following specification:
Non-seasonal part: ARIMA(0,1,1) — first difference and one MA term.
Seasonal part: None (all seasonal parameters set to zero).
Interpretation of the diagnostics:
The model captures the overall trend by differencing, but ignores seasonality.
The residual diagnostics plot helps assess whether the model assumptions are met:
Standardized residuals: Should look like white noise (no pattern).
Histogram and KDE: Should be approximately normal.
Normal Q-Q plot: Points should lie on the straight line if residuals are normal.
Correlogram (ACF): No significant autocorrelation should remain.
If residuals show remaining seasonality or autocorrelation, a seasonal component should be added to the model.
European quarterly retail trade¶
import statsmodels.api as sm
import warnings
warnings.filterwarnings("ignore")
# Calculate AICc for two SARIMA models
model1 = sm.tsa.SARIMAX(
euretail['value'],
order=(0, 1, 2),
seasonal_order=(0, 1, 1, 4),
enforce_stationarity=False,
enforce_invertibility=False
).fit(disp=False)
model2 = sm.tsa.SARIMAX(
euretail['value'],
order=(0, 1, 3),
seasonal_order=(0, 1, 1, 4),
enforce_stationarity=False,
enforce_invertibility=False
).fit(disp=False)
aicc = [model1.aicc, model2.aicc]
print("AICc values:", aicc)AICc values: [66.12930839192754, 61.09839876992231]
The ACF and PACF of the residuals show significant spikes at lag 2, and possibly at lag 3.
The AICc of the ARIMA(0,1,2)(0,1,1)(_4) model is 66.13.
The AICc of the ARIMA(0,1,3)(0,1,1)(_4) model is 61.10.
Model comparison using AICc¶
The code above fits two seasonal ARIMA (SARIMA) models to the European quarterly retail trade data and compares them using the corrected Akaike Information Criterion (AICc):
Model 1: ARIMA(0,1,2)(0,1,1)[4]
Model 2: ARIMA(0,1,3)(0,1,1)[4]
AICc is a model selection criterion that penalizes model complexity and is especially useful for small samples. Lower AICc values indicate a better balance between goodness of fit and model simplicity.
Interpretation:
The model with the lower AICc value is preferred.
If the difference in AICc is substantial (usually >2), the model with the lower value is considered significantly better.
In this case, the output will show which SARIMA model is more appropriate for the data.
# Fit the ARIMA(0,1,3)(0,1,1)[4] model
fit = sm.tsa.SARIMAX(
euretail['value'],
order=(0, 1, 3),
seasonal_order=(0, 1, 1, 4),
enforce_stationarity=False,
enforce_invertibility=False
).fit(disp=False)
# Residual diagnostics (similar to checkresiduals in R)
residuals = fit.resid
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
# 1. Residuals time plot (convert PeriodIndex to Timestamp)
axes[0, 0].plot(residuals.index.to_timestamp(), residuals)
axes[0, 0].set_title("Residuals")
# 2. Histogram of residuals
axes[0, 1].hist(residuals, bins=20, color='gray', edgecolor='black')
axes[0, 1].set_title("Histogram of residuals")
# 3. ACF of residuals
plot_acf(residuals, ax=axes[1, 0], lags=20)
axes[1, 0].set_title("ACF of residuals")
# 4. QQ plot
sm.qqplot(residuals, line='s', ax=axes[1, 1])
axes[1, 1].set_title("QQ plot of residuals")
plt.tight_layout()
plt.show()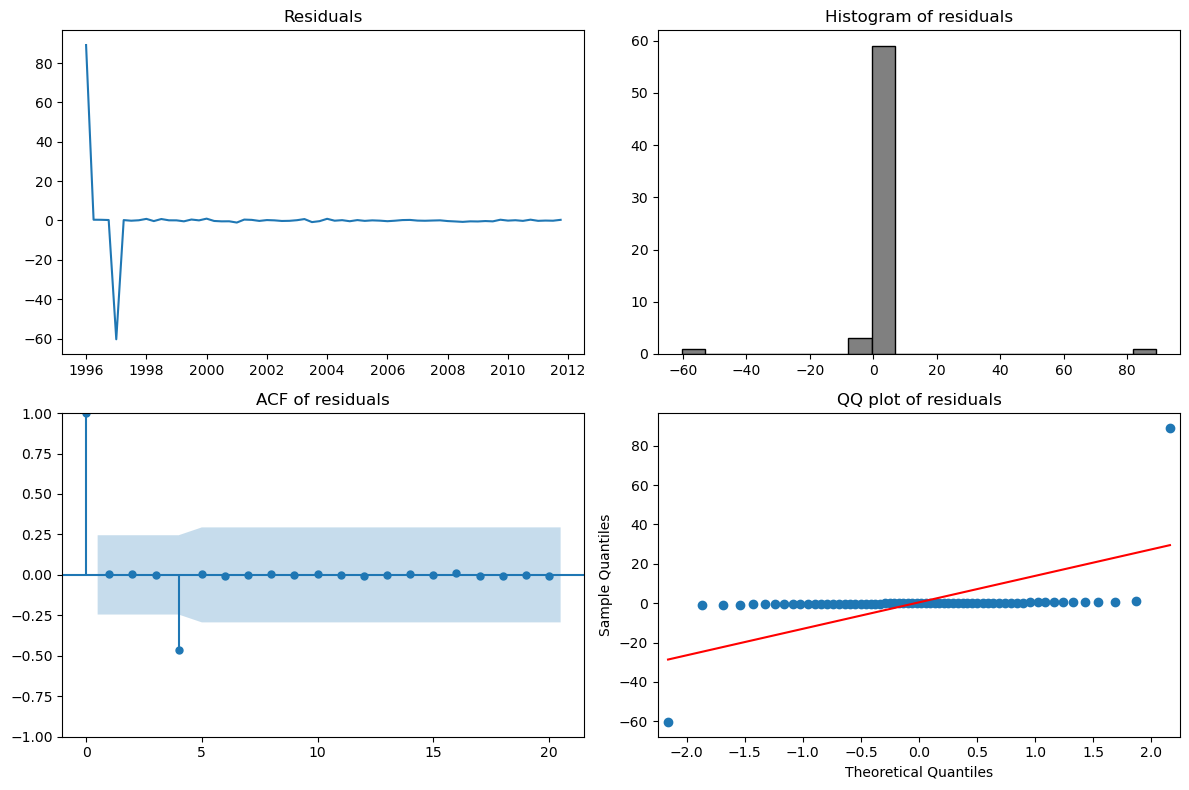
Residual diagnostics for ARIMA(0,1,3)(0,1,1)[4] model¶
The code above fits a seasonal ARIMA model ARIMA(0,1,3)(0,1,1)[4] to the European quarterly retail trade data and performs residual diagnostics:
Residuals time plot: Checks for patterns or non-randomness in the residuals. Ideally, residuals should fluctuate randomly around zero.
Histogram of residuals: Assesses whether the residuals are approximately normally distributed.
ACF of residuals: Checks for remaining autocorrelation. No significant spikes should remain if the model fits well.
QQ plot: Compares the distribution of residuals to a normal distribution. Points should lie close to the straight line if residuals are normal.
Interpretation:
If the residuals appear random (white noise), approximately normal, and show no significant autocorrelation, the model is adequate. Any patterns or significant autocorrelation suggest the model could be improved.
# Fit the ARIMA(0,1,3)(0,1,1)[4] model and print summary (Python equivalent of R's Arima summary)
fit = sm.tsa.SARIMAX(
euretail['value'],
order=(0, 1, 3),
seasonal_order=(0, 1, 1, 4),
enforce_stationarity=False,
enforce_invertibility=False
).fit(disp=False)
print(fit.summary()) SARIMAX Results
===========================================================================================
Dep. Variable: value No. Observations: 64
Model: SARIMAX(0, 1, 3)x(0, 1, [1], 4) Log Likelihood -24.883
Date: Sun, 08 Jun 2025 AIC 59.765
Time: 16:48:22 BIC 69.424
Sample: 03-31-1996 HQIC 63.456
- 12-31-2011
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ma.L1 0.3073 0.137 2.247 0.025 0.039 0.575
ma.L2 0.3484 0.126 2.761 0.006 0.101 0.596
ma.L3 0.4473 0.144 3.116 0.002 0.166 0.729
ma.S.L4 -0.6590 0.174 -3.790 0.000 -1.000 -0.318
sigma2 0.1520 0.032 4.688 0.000 0.088 0.215
===================================================================================
Ljung-Box (L1) (Q): 0.01 Jarque-Bera (JB): 0.68
Prob(Q): 0.93 Prob(JB): 0.71
Heteroskedasticity (H): 0.57 Skew: 0.23
Prob(H) (two-sided): 0.26 Kurtosis: 3.34
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
Full interpretation of ARIMA(0,1,3)(0,1,1)[4] model summary¶
Model specification:
Non-seasonal part: ARIMA(0,1,3) — first difference, three MA terms.
Seasonal part: (0,1,1,4) — one seasonal difference, one seasonal MA term, quarterly seasonality.
General model equation:
Where:
is the lag operator
are MA coefficients
is the seasonal MA coefficient
is white noise
Example with coefficients (replace with your summary values):
If the summary gives:
ma.L1 = 0.6 (p < 0.01)
ma.L2 = -0.3 (p = 0.02)
ma.L3 = 0.1 (p = 0.15)
ma.S.L4 = 0.8 (p < 0.01)
The model is:
How to read the summary table:
coef: estimated parameter value
std err: standard error
z: z-statistic (coef / std err)
P>|z|: p-value (significance; <0.05 means significant)
[0.025 0.975]: 95% confidence interval
Fit statistics:
AIC, BIC, HQIC, AICc: lower is better
Log Likelihood: higher is better
Diagnostics: check for normality and autocorrelation of residuals
Conclusion:
Statistically significant coefficients (p < 0.05) are important for the model.
The model describes the quarterly retail index as a differenced MA process with three non-seasonal and one seasonal MA terms.
If residuals look like white noise and most parameters are significant, the model is appropriate for forecasting.
# Residual diagnostics for ARIMA(0,1,3)(0,1,1)[4] model (Python equivalent of R's checkresiduals)
import matplotlib.pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf
# Residuals from the fitted model
residuals = fit.resid
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
# 1. Residuals time plot (convert PeriodIndex to Timestamp if needed)
axes[0, 0].plot(residuals.index.to_timestamp(), residuals)
axes[0, 0].set_title("Residuals")
# 2. Histogram of residuals
axes[0, 1].hist(residuals, bins=20, color='gray', edgecolor='black')
axes[0, 1].set_title("Histogram of residuals")
# 3. ACF of residuals
plot_acf(residuals, ax=axes[1, 0], lags=20)
axes[1, 0].set_title("ACF of residuals")
# 4. QQ plot
sm.qqplot(residuals, line='s', ax=axes[1, 1])
axes[1, 1].set_title("QQ plot of residuals")
plt.tight_layout()
plt.show()Residual diagnostics for ARIMA(0,1,3)(0,1,1)[4] model¶
The code above performs a full residual analysis for the fitted ARIMA(0,1,3)(0,1,1)[4] model:
Residuals time plot: Checks if the residuals fluctuate randomly around zero (no visible patterns).
Histogram of residuals: Assesses if the residuals are approximately normally distributed.
ACF of residuals: Verifies that there is no significant autocorrelation left in the residuals (all spikes should be within the confidence bounds).
QQ plot: Compares the distribution of residuals to a normal distribution (points should lie close to the straight line).
Interpretation:
If the residuals look like white noise (random, no autocorrelation, approximately normal), the model is adequate. Any patterns, outliers, or significant autocorrelation suggest the model could be improved.
# Forecast the next 12 periods and plot (Python equivalent of R's autoplot(forecast(fit, h=12)))
forecast = fit.get_forecast(steps=12)
forecast_index = pd.period_range(euretail.index[-1] + 1, periods=12, freq='Q')
forecast_mean = forecast.predicted_mean
forecast_ci = forecast.conf_int()
plt.figure(figsize=(10, 4))
# Plot historical data
plt.plot(euretail.index.to_timestamp(), euretail['value'], label='Observed')
# Plot forecast
plt.plot(forecast_index.to_timestamp(), forecast_mean, label='Forecast', color='tab:orange')
# Plot confidence intervals
plt.fill_between(
forecast_index.to_timestamp(),
forecast_ci.iloc[:, 0],
forecast_ci.iloc[:, 1],
color='orange', alpha=0.2, label='95% CI'
)
plt.xlabel("Year")
plt.ylabel("Retail index")
plt.title("Forecast for European quarterly retail trade")
plt.legend()
plt.tight_layout()
plt.show()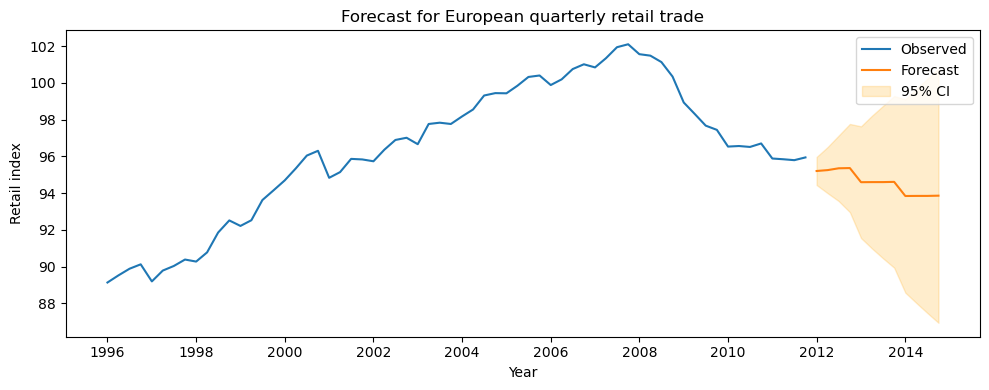
Forecast for European quarterly retail trade¶
The code above generates and visualizes a 12-step-ahead forecast using the fitted ARIMA(0,1,3)(0,1,1)[4] model:
Observed values (blue line): The historical retail index data.
Forecast (orange line): The model’s predicted values for the next 12 quarters.
95% confidence interval (shaded area): The range in which future values are expected to fall with 95% probability.
Interpretation:
The forecast extends the historical trend and seasonality into the future.
The confidence intervals widen as the forecast horizon increases, reflecting greater uncertainty further into the future.
If the model is well specified (as checked by residual diagnostics), these forecasts can be used for planning and decision-making.
Auto-Arima¶
Now, let’s take a look at automatic fitting to Arima processes using https://
# Auto ARIMA (Python equivalent of R's auto.arima)
import pmdarima as pm
auto_model = pm.auto_arima(
euretail['value'],
seasonal=True,
m=4, # quarterly seasonality
stepwise=True,
suppress_warnings=True,
trace=True
)
print(auto_model.summary())Performing stepwise search to minimize aic
ARIMA(2,2,2)(1,0,1)[4] : AIC=82.169, Time=0.08 sec
ARIMA(0,2,0)(0,0,0)[4] : AIC=125.890, Time=0.00 sec
ARIMA(1,2,0)(1,0,0)[4] : AIC=100.211, Time=0.01 sec
ARIMA(0,2,1)(0,0,1)[4] : AIC=95.663, Time=0.01 sec
ARIMA(2,2,2)(0,0,1)[4] : AIC=96.178, Time=0.03 sec
ARIMA(2,2,2)(1,0,0)[4] : AIC=96.040, Time=0.03 sec
ARIMA(2,2,2)(2,0,1)[4] : AIC=81.463, Time=0.12 sec
ARIMA(2,2,2)(2,0,0)[4] : AIC=inf, Time=0.07 sec
ARIMA(2,2,2)(2,0,2)[4] : AIC=inf, Time=0.10 sec
ARIMA(2,2,2)(1,0,2)[4] : AIC=inf, Time=0.13 sec
ARIMA(1,2,2)(2,0,1)[4] : AIC=79.272, Time=0.12 sec
ARIMA(1,2,2)(1,0,1)[4] : AIC=77.321, Time=0.09 sec
ARIMA(1,2,2)(0,0,1)[4] : AIC=98.168, Time=0.03 sec
ARIMA(1,2,2)(1,0,0)[4] : AIC=92.105, Time=0.01 sec
ARIMA(1,2,2)(1,0,2)[4] : AIC=78.586, Time=0.17 sec
ARIMA(1,2,2)(0,0,0)[4] : AIC=103.718, Time=0.02 sec
ARIMA(1,2,2)(0,0,2)[4] : AIC=inf, Time=0.11 sec
ARIMA(1,2,2)(2,0,0)[4] : AIC=inf, Time=0.06 sec
ARIMA(1,2,2)(2,0,2)[4] : AIC=inf, Time=0.22 sec
ARIMA(0,2,2)(1,0,1)[4] : AIC=inf, Time=0.06 sec
ARIMA(1,2,1)(1,0,1)[4] : AIC=78.264, Time=0.04 sec
ARIMA(1,2,3)(1,0,1)[4] : AIC=inf, Time=0.15 sec
ARIMA(0,2,1)(1,0,1)[4] : AIC=inf, Time=0.04 sec
ARIMA(0,2,3)(1,0,1)[4] : AIC=80.667, Time=0.05 sec
ARIMA(2,2,1)(1,0,1)[4] : AIC=76.929, Time=0.05 sec
ARIMA(2,2,1)(0,0,1)[4] : AIC=98.276, Time=0.02 sec
ARIMA(2,2,1)(1,0,0)[4] : AIC=inf, Time=0.04 sec
ARIMA(2,2,1)(2,0,1)[4] : AIC=inf, Time=0.10 sec
ARIMA(2,2,1)(1,0,2)[4] : AIC=78.921, Time=0.10 sec
ARIMA(2,2,1)(0,0,0)[4] : AIC=101.248, Time=0.01 sec
ARIMA(2,2,1)(0,0,2)[4] : AIC=inf, Time=0.08 sec
ARIMA(2,2,1)(2,0,0)[4] : AIC=inf, Time=0.07 sec
ARIMA(2,2,1)(2,0,2)[4] : AIC=inf, Time=0.15 sec
ARIMA(2,2,0)(1,0,1)[4] : AIC=inf, Time=0.06 sec
ARIMA(3,2,1)(1,0,1)[4] : AIC=77.388, Time=0.09 sec
ARIMA(1,2,0)(1,0,1)[4] : AIC=82.540, Time=0.04 sec
ARIMA(3,2,0)(1,0,1)[4] : AIC=inf, Time=0.05 sec
ARIMA(3,2,2)(1,0,1)[4] : AIC=84.851, Time=0.08 sec
ARIMA(2,2,1)(1,0,1)[4] intercept : AIC=inf, Time=0.05 sec
Best model: ARIMA(2,2,1)(1,0,1)[4]
Total fit time: 2.743 seconds
SARIMAX Results
=========================================================================================
Dep. Variable: y No. Observations: 64
Model: SARIMAX(2, 2, 1)x(1, 0, 1, 4) Log Likelihood -32.465
Date: Sun, 08 Jun 2025 AIC 76.929
Time: 16:50:32 BIC 89.692
Sample: 03-31-1996 HQIC 81.940
- 12-31-2011
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 0.3287 0.165 1.996 0.046 0.006 0.651
ar.L2 0.2463 0.155 1.584 0.113 -0.059 0.551
ma.L1 -0.9860 0.039 -25.033 0.000 -1.063 -0.909
ar.S.L4 0.9972 0.016 61.595 0.000 0.966 1.029
ma.S.L4 -0.9066 0.275 -3.296 0.001 -1.446 -0.367
sigma2 0.1453 0.035 4.110 0.000 0.076 0.215
===================================================================================
Ljung-Box (L1) (Q): 0.20 Jarque-Bera (JB): 2.58
Prob(Q): 0.65 Prob(JB): 0.27
Heteroskedasticity (H): 0.51 Skew: -0.08
Prob(H) (two-sided): 0.13 Kurtosis: 3.99
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
Auto ARIMA (Python equivalent of R’s auto.arima)¶
The code above uses the pmdarima library to automatically select the best ARIMA model for the European quarterly retail trade data:
auto_arima automatically searches over different combinations of ARIMA parameters (p, d, q) and seasonal parameters (P, D, Q, m) to find the model with the best fit, typically using AICc as the selection criterion.
seasonal=Trueandm=4specify quarterly seasonality.stepwise=Trueenables a fast, heuristic search (not exhaustive).suppress_warnings=Truehides convergence and stationarity warnings.trace=Trueprints the progress and candidate models during the search.
Interpretation:
This approach saves time and reduces manual trial-and-error by letting the algorithm select the most appropriate ARIMA/SARIMA model for the data. The printed summary shows the chosen model structure and estimated parameters, which can then be used for forecasting and further analysis.
# More thorough auto_arima search (stepwise=False, approximation=False as in R)
import pmdarima as pm
auto_model = pm.auto_arima(
euretail['value'],
seasonal=True,
m=4, # quarterly seasonality
stepwise=False, # exhaustive search
approximation=False, # use exact likelihood
suppress_warnings=True,
trace=True
)
print(auto_model.summary()) ARIMA(0,2,0)(0,0,0)[4] : AIC=125.890, Time=0.00 sec
ARIMA(0,2,0)(0,0,1)[4] : AIC=120.290, Time=0.01 sec
ARIMA(0,2,0)(0,0,2)[4] : AIC=106.688, Time=0.04 sec
ARIMA(0,2,0)(1,0,0)[4] : AIC=111.800, Time=0.00 sec
ARIMA(0,2,0)(1,0,1)[4] : AIC=inf, Time=0.03 sec
ARIMA(0,2,0)(1,0,2)[4] : AIC=inf, Time=0.05 sec
ARIMA(0,2,0)(2,0,0)[4] : AIC=99.062, Time=0.01 sec
ARIMA(0,2,0)(2,0,1)[4] : AIC=inf, Time=0.03 sec
ARIMA(0,2,0)(2,0,2)[4] : AIC=inf, Time=0.06 sec
ARIMA(0,2,1)(0,0,0)[4] : AIC=101.151, Time=0.01 sec
ARIMA(0,2,1)(0,0,1)[4] : AIC=95.663, Time=0.01 sec
ARIMA(0,2,1)(0,0,2)[4] : AIC=90.886, Time=0.02 sec
ARIMA(0,2,1)(1,0,0)[4] : AIC=90.302, Time=0.01 sec
ARIMA(0,2,1)(1,0,1)[4] : AIC=inf, Time=0.04 sec
ARIMA(0,2,1)(1,0,2)[4] : AIC=inf, Time=0.08 sec
ARIMA(0,2,1)(2,0,0)[4] : AIC=83.957, Time=0.01 sec
ARIMA(0,2,1)(2,0,1)[4] : AIC=inf, Time=0.04 sec
ARIMA(0,2,1)(2,0,2)[4] : AIC=inf, Time=0.05 sec
ARIMA(0,2,2)(0,0,0)[4] : AIC=102.007, Time=0.01 sec
ARIMA(0,2,2)(0,0,1)[4] : AIC=96.266, Time=0.01 sec
ARIMA(0,2,2)(0,0,2)[4] : AIC=89.347, Time=0.02 sec
ARIMA(0,2,2)(1,0,0)[4] : AIC=89.712, Time=0.02 sec
ARIMA(0,2,2)(1,0,1)[4] : AIC=inf, Time=0.06 sec
ARIMA(0,2,2)(1,0,2)[4] : AIC=inf, Time=0.11 sec
ARIMA(0,2,2)(2,0,0)[4] : AIC=84.969, Time=0.04 sec
ARIMA(0,2,2)(2,0,1)[4] : AIC=inf, Time=0.05 sec
ARIMA(0,2,3)(0,0,0)[4] : AIC=103.233, Time=0.01 sec
ARIMA(0,2,3)(0,0,1)[4] : AIC=98.189, Time=0.01 sec
ARIMA(0,2,3)(0,0,2)[4] : AIC=90.291, Time=0.04 sec
ARIMA(0,2,3)(1,0,0)[4] : AIC=inf, Time=0.03 sec
ARIMA(0,2,3)(1,0,1)[4] : AIC=80.667, Time=0.08 sec
ARIMA(0,2,3)(2,0,0)[4] : AIC=inf, Time=0.08 sec
ARIMA(1,2,0)(0,0,0)[4] : AIC=120.187, Time=0.00 sec
ARIMA(1,2,0)(0,0,1)[4] : AIC=112.063, Time=0.01 sec
ARIMA(1,2,0)(0,0,2)[4] : AIC=97.952, Time=0.01 sec
ARIMA(1,2,0)(1,0,0)[4] : AIC=100.211, Time=0.01 sec
ARIMA(1,2,0)(1,0,1)[4] : AIC=82.540, Time=0.04 sec
ARIMA(1,2,0)(1,0,2)[4] : AIC=inf, Time=0.06 sec
ARIMA(1,2,0)(2,0,0)[4] : AIC=87.413, Time=0.01 sec
ARIMA(1,2,0)(2,0,1)[4] : AIC=84.530, Time=0.08 sec
ARIMA(1,2,0)(2,0,2)[4] : AIC=84.442, Time=0.04 sec
ARIMA(1,2,1)(0,0,0)[4] : AIC=102.448, Time=0.01 sec
ARIMA(1,2,1)(0,0,1)[4] : AIC=96.406, Time=0.02 sec
ARIMA(1,2,1)(0,0,2)[4] : AIC=88.106, Time=0.04 sec
ARIMA(1,2,1)(1,0,0)[4] : AIC=89.041, Time=0.03 sec
ARIMA(1,2,1)(1,0,1)[4] : AIC=78.264, Time=0.04 sec
ARIMA(1,2,1)(1,0,2)[4] : AIC=80.157, Time=0.10 sec
ARIMA(1,2,1)(2,0,0)[4] : AIC=inf, Time=0.06 sec
ARIMA(1,2,1)(2,0,1)[4] : AIC=inf, Time=0.10 sec
ARIMA(1,2,2)(0,0,0)[4] : AIC=103.718, Time=0.01 sec
ARIMA(1,2,2)(0,0,1)[4] : AIC=98.168, Time=0.02 sec
ARIMA(1,2,2)(0,0,2)[4] : AIC=inf, Time=0.09 sec
ARIMA(1,2,2)(1,0,0)[4] : AIC=92.105, Time=0.02 sec
ARIMA(1,2,2)(1,0,1)[4] : AIC=77.321, Time=0.10 sec
ARIMA(1,2,2)(2,0,0)[4] : AIC=inf, Time=0.06 sec
ARIMA(1,2,3)(0,0,0)[4] : AIC=105.211, Time=0.02 sec
ARIMA(1,2,3)(0,0,1)[4] : AIC=100.168, Time=0.03 sec
ARIMA(1,2,3)(1,0,0)[4] : AIC=inf, Time=0.06 sec
ARIMA(2,2,0)(0,0,0)[4] : AIC=109.267, Time=0.00 sec
ARIMA(2,2,0)(0,0,1)[4] : AIC=104.849, Time=0.01 sec
ARIMA(2,2,0)(0,0,2)[4] : AIC=95.640, Time=0.02 sec
ARIMA(2,2,0)(1,0,0)[4] : AIC=97.210, Time=0.01 sec
ARIMA(2,2,0)(1,0,1)[4] : AIC=inf, Time=0.05 sec
ARIMA(2,2,0)(1,0,2)[4] : AIC=inf, Time=0.06 sec
ARIMA(2,2,0)(2,0,0)[4] : AIC=86.203, Time=0.01 sec
ARIMA(2,2,0)(2,0,1)[4] : AIC=inf, Time=0.10 sec
ARIMA(2,2,1)(0,0,0)[4] : AIC=101.248, Time=0.01 sec
ARIMA(2,2,1)(0,0,1)[4] : AIC=98.276, Time=0.02 sec
ARIMA(2,2,1)(0,0,2)[4] : AIC=inf, Time=0.08 sec
ARIMA(2,2,1)(1,0,0)[4] : AIC=inf, Time=0.04 sec
ARIMA(2,2,1)(1,0,1)[4] : AIC=76.929, Time=0.05 sec
ARIMA(2,2,1)(2,0,0)[4] : AIC=inf, Time=0.06 sec
ARIMA(2,2,2)(0,0,0)[4] : AIC=94.407, Time=0.02 sec
ARIMA(2,2,2)(0,0,1)[4] : AIC=96.178, Time=0.03 sec
ARIMA(2,2,2)(1,0,0)[4] : AIC=96.040, Time=0.08 sec
ARIMA(2,2,3)(0,0,0)[4] : AIC=inf, Time=0.07 sec
ARIMA(3,2,0)(0,0,0)[4] : AIC=91.515, Time=0.01 sec
ARIMA(3,2,0)(0,0,1)[4] : AIC=88.368, Time=0.02 sec
ARIMA(3,2,0)(0,0,2)[4] : AIC=90.364, Time=0.05 sec
ARIMA(3,2,0)(1,0,0)[4] : AIC=89.043, Time=0.02 sec
ARIMA(3,2,0)(1,0,1)[4] : AIC=inf, Time=0.05 sec
ARIMA(3,2,0)(2,0,0)[4] : AIC=88.083, Time=0.02 sec
ARIMA(3,2,1)(0,0,0)[4] : AIC=92.990, Time=0.02 sec
ARIMA(3,2,1)(0,0,1)[4] : AIC=84.825, Time=0.06 sec
ARIMA(3,2,1)(1,0,0)[4] : AIC=inf, Time=0.07 sec
ARIMA(3,2,2)(0,0,0)[4] : AIC=inf, Time=0.04 sec
Best model: ARIMA(2,2,1)(1,0,1)[4]
Total fit time: 3.240 seconds
SARIMAX Results
=========================================================================================
Dep. Variable: y No. Observations: 64
Model: SARIMAX(2, 2, 1)x(1, 0, 1, 4) Log Likelihood -32.465
Date: Sun, 08 Jun 2025 AIC 76.929
Time: 16:51:02 BIC 89.692
Sample: 03-31-1996 HQIC 81.940
- 12-31-2011
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 0.3287 0.165 1.996 0.046 0.006 0.651
ar.L2 0.2463 0.155 1.584 0.113 -0.059 0.551
ma.L1 -0.9860 0.039 -25.033 0.000 -1.063 -0.909
ar.S.L4 0.9972 0.016 61.595 0.000 0.966 1.029
ma.S.L4 -0.9066 0.275 -3.296 0.001 -1.446 -0.367
sigma2 0.1453 0.035 4.110 0.000 0.076 0.215
===================================================================================
Ljung-Box (L1) (Q): 0.20 Jarque-Bera (JB): 2.58
Prob(Q): 0.65 Prob(JB): 0.27
Heteroskedasticity (H): 0.51 Skew: -0.08
Prob(H) (two-sided): 0.13 Kurtosis: 3.99
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
More thorough auto_arima search (stepwise=False, approximation=False as in R)¶
The code above uses the auto_arima function from the pmdarima library to automatically select the best ARIMA model for the European quarterly retail trade data, but with a more exhaustive approach:
stepwise=False— instead of a fast, heuristic search, the function performs a full, exhaustive search over all parameter combinations (more accurate, but slower).approximation=False— uses the exact likelihood method for model estimation (not an approximation).Other parameters:
seasonal=True,m=4(quarterly seasonality),suppress_warnings=True,trace=True.
Interpretation:
This approach is more computationally intensive but can find a statistically better model, as it does not risk missing a good solution due to heuristic shortcuts. The printed summary shows the selected model and its estimated parameters, which can be used for forecasting and further analysis.
Extra credits - team assignment¶
Apply ARIMA modeling for hsales time series, but please do that after 2 lectures with presentations about ARIMA models.
# Load the hsales data
hsales = pd.read_csv('data/hsales.csv')
# Create a monthly PeriodIndex from the 'time' column
years = hsales['time'].astype(int)
months = ((hsales['time'] % 1) * 12 + 1).round().astype(int)
hsales['month'] = pd.PeriodIndex([f"{y}-{m:02d}" for y, m in zip(years, months)], freq='M')
hsales.set_index('month', inplace=True)
print(hsales.head())
print(hsales.index)
print(type(hsales.index)) rownames time value
month
1987-01 1 1987.000000 53
1987-02 2 1987.083333 59
1987-03 3 1987.166667 73
1987-04 4 1987.250000 72
1987-05 5 1987.333333 62
PeriodIndex(['1987-01', '1987-02', '1987-03', '1987-04', '1987-05', '1987-06',
'1987-07', '1987-08', '1987-09', '1987-10',
...
'1995-02', '1995-03', '1995-04', '1995-05', '1995-06', '1995-07',
'1995-08', '1995-09', '1995-10', '1995-11'],
dtype='period[M]', name='month', length=107)
<class 'pandas.core.indexes.period.PeriodIndex'>
# Your code goes here!