Real world data is messy and often contains a lot of missing values. There could be multiple reasons for the missing values but primarily the reason for missingness can be attributed to
| Reason for missing Data |
|---|
| Data doesn’t exist |
| Data not collected due to human error. |
| Data deleted accidently |
Either way we need to address this issue before we proceed with the modeling stuff. It is also important to note that some algorithms like XGBoost and LightGBM can treat missing data without any preprocessing.
Objective¶
The objective of this notebook is to detect missing values and then go over some of the methods used for imputing them.
Data¶
There are two publically available datasets which will be used to explain the concepts:
Titanic Dataset for Non Time Series problem
Air Quality Data in India (2015 - 2020) for Time Series problem
Loading necessary libraries and datasets¶
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
from sklearn import preprocessing
from sklearn.model_selection import train_test_split, cross_val_score, StratifiedKFold
from sklearn.linear_model import LogisticRegression
import missingno as msnoReading in the dataset¶
Reading in the Titanic Dataset.
train=pd.read_csv('titanic/train.csv')
test=pd.read_csv('titanic/test.csv')
print('Training data shape: ', train.shape)
print('Testing data shape: ', test.shape)
# First few rows of the training dataset
train.head()
Training data shape: (891, 12)
Testing data shape: (418, 11)
Examining the Target column¶
For each passenger in the test set, we need to create a model that predicts whether or not the passengers survived the sinking of the Titanic. Hence Survived is that target column in the dataset. Let’s examine the Distribution of the target column
train['Survived'].value_counts()Survived
0 549
1 342
Name: count, dtype: int64s = sns.countplot(x = 'Survived',data = train)
sizes=[]
for p in s.patches:
height = p.get_height()
sizes.append(height)
s.text(p.get_x()+p.get_width()/2.,
height + 3,
'{:1.2f}%'.format(height/len(train)*100),
ha="center", fontsize=14) 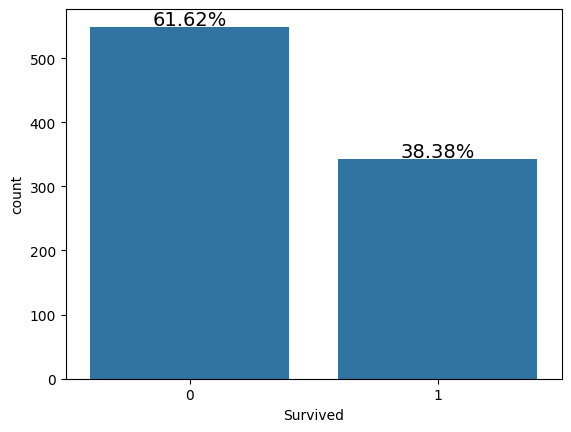
Here:
0: Did not Survive while
1: Survived.
Clearly, less people survived the accident.
Since the focus of the notebook is to detect and handle missing values, we’ll jump directly into it. Let’s now look at a step by step process to manage the missing values in a dataset.
Detecting Missing values¶
Detecting missing values numerically¶
The first step is to detect the count/percentage of missing values in every column of the dataset. This will give an idea about the distribution of missing values.
# credit: https://www.kaggle.com/willkoehrsen/start-here-a-gentle-introduction.
# One of the best notebooks on getting started with a ML problem.
def missing_values_table(df):
# Total missing values
mis_val = df.isnull().sum()
# Percentage of missing values
mis_val_percent = 100 * df.isnull().sum() / len(df)
# Make a table with the results
mis_val_table = pd.concat([mis_val, mis_val_percent], axis=1)
# Rename the columns
mis_val_table_ren_columns = mis_val_table.rename(
columns = {0 : 'Missing Values', 1 : '% of Total Values'})
# Sort the table by percentage of missing descending
mis_val_table_ren_columns = mis_val_table_ren_columns[
mis_val_table_ren_columns.iloc[:,1] != 0].sort_values(
'% of Total Values', ascending=False).round(1)
# Print some summary information
print ("Your selected dataframe has " + str(df.shape[1]) + " columns.\n"
"There are " + str(mis_val_table_ren_columns.shape[0]) +
" columns that have missing values.")
# Return the dataframe with missing information
return mis_val_table_ren_columns
train_missing= missing_values_table(train)
train_missingYour selected dataframe has 12 columns.
There are 3 columns that have missing values.
test_missing= missing_values_table(test)
test_missingYour selected dataframe has 11 columns.
There are 3 columns that have missing values.
Both the train and test set have the same proportion of the missing values.
Detecting missing data visually using Missingno library¶
To graphically analyse the missingness of the data, let’s use a library called Missingno It is a package for graphical analysis of missing values. To use this library, we need to import it as follows:
import missingno as msno
msno.bar(train)<Axes: >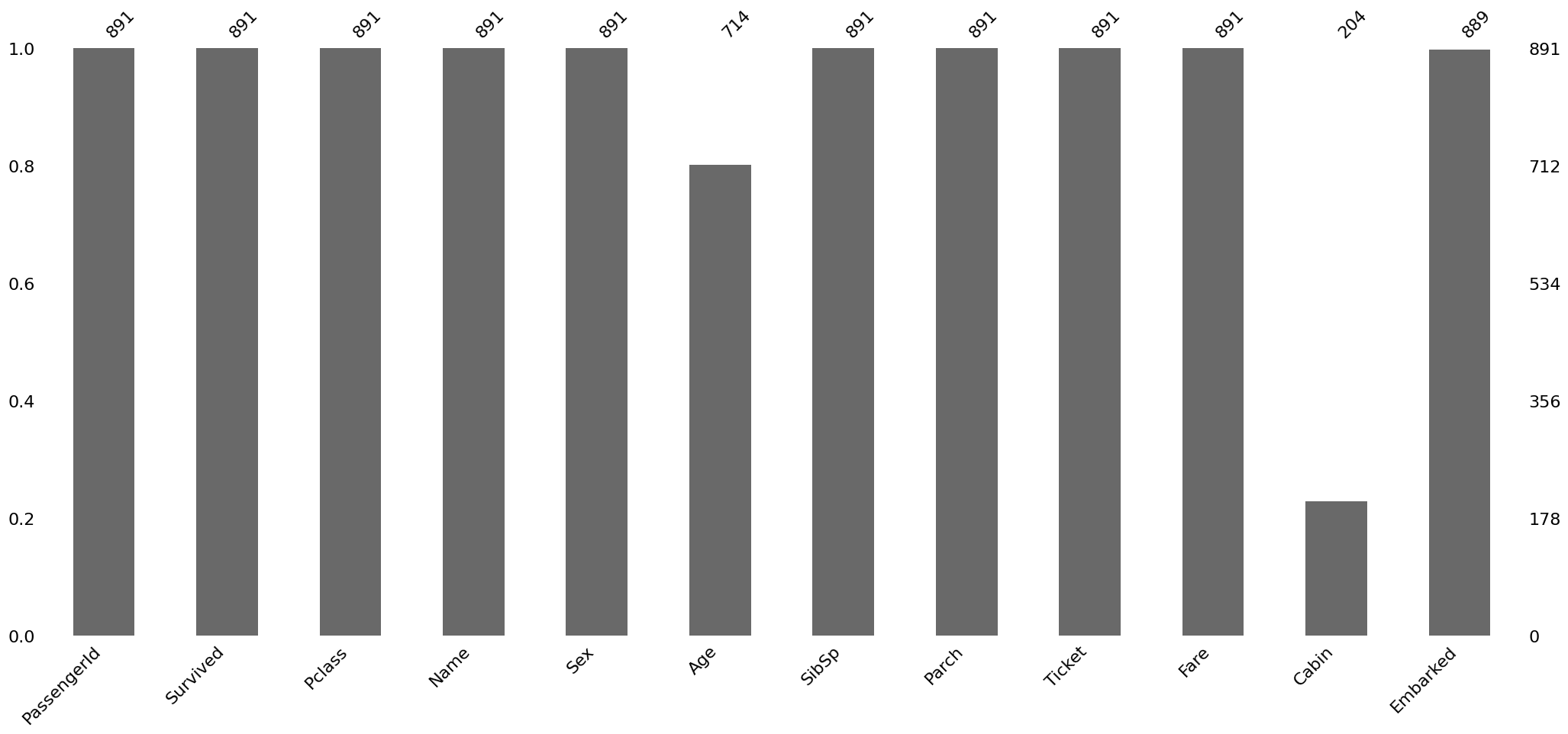
The bar chart above gives a quick graphical overview of the completeness of the dataset. We can see that Age, Cabin and embarked columns have missing values. Next,it would make sense to find out the locations of the missing data.
Visualizing the locations of the missing data¶
The msno.matrix nullity matrix is a data-dense display which lets you quickly visually pick out patterns in data completion.
msno.matrix(train)<Axes: >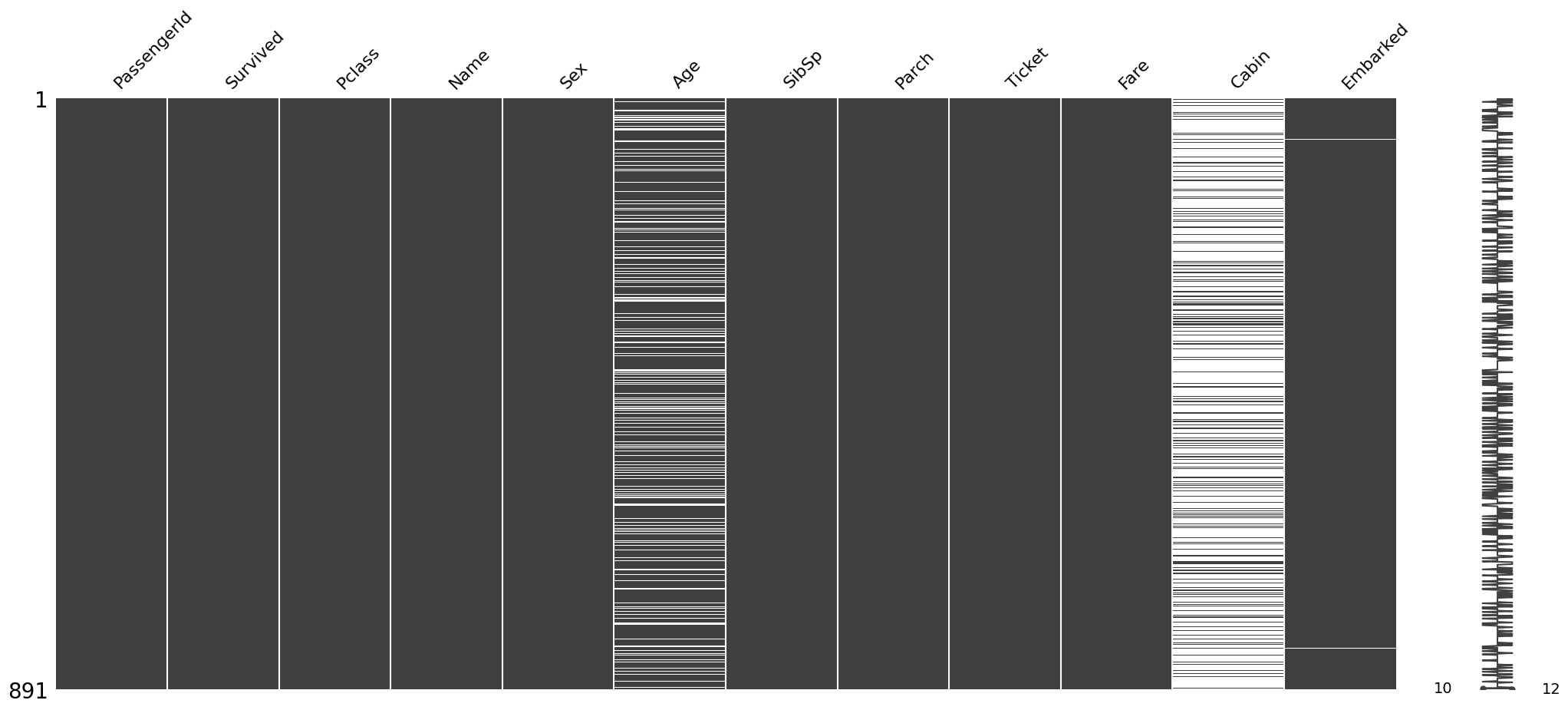
The plot appears blank(white) wherever there are missing values. For instance, in Embarked column there are only two instances of missing data, hence the two white lines.
The sparkline on the right gives an idea of the general shape of the completeness of the data and points out the row with the minimum nullities and the total number of columns in a given dataset, at the bottom.
It is also possible to sample the dataset to pinpoint the exact location of the missing values. For instance let’s check the first 100 rows.
msno.matrix(train.sample(100))<Axes: >
This shows that the Embarked column has no nullity in the first 100 cases.
Reasons for Missing Values¶
Before we start treating the missing values ,it is important to understand the various reasons for the missingness in data. Broadly speaking, there can be three possible reasons:
**1. Missing Completely at Random (MCAR) **
The missing values on a given variable (Y) are not associated with other variables in a given data set or with the variable (Y) itself. In other words, there is no particular reason for the missing values.
**2. Missing at Random (MAR) **
MAR occurs when the missingness is not random, but where missingness can be fully accounted for by variables where there is complete information.
**3. Missing Not at Random (MNAR) **
Missingness depends on unobserved data or the value of the missing data itself.
Now let us look at nullity matrix again to see if can find what type of missingness is present in the dataset.
Finding reason for missing data using matrix plot¶
msno.matrix(train)<Axes: >
The
EmbarkedColumn has very few missing values and donot seem to be correlated with any other column, Hence, the missingness in Embarked column can be attributed as Missing Completely at Random.
Both the
Ageand theCabincolumns have a lot of missing values.This could be a case of MAR as we cannot directly observe the reason for missingness of data in these columns.
The missingno package also let’s us sort the graph by a particluar column. Let’s sort the values by Age and Cabin column to see if there is a pattern in the missing values
#sorted by Age
sorted = train.sort_values('Age')
msno.matrix(sorted)<Axes: >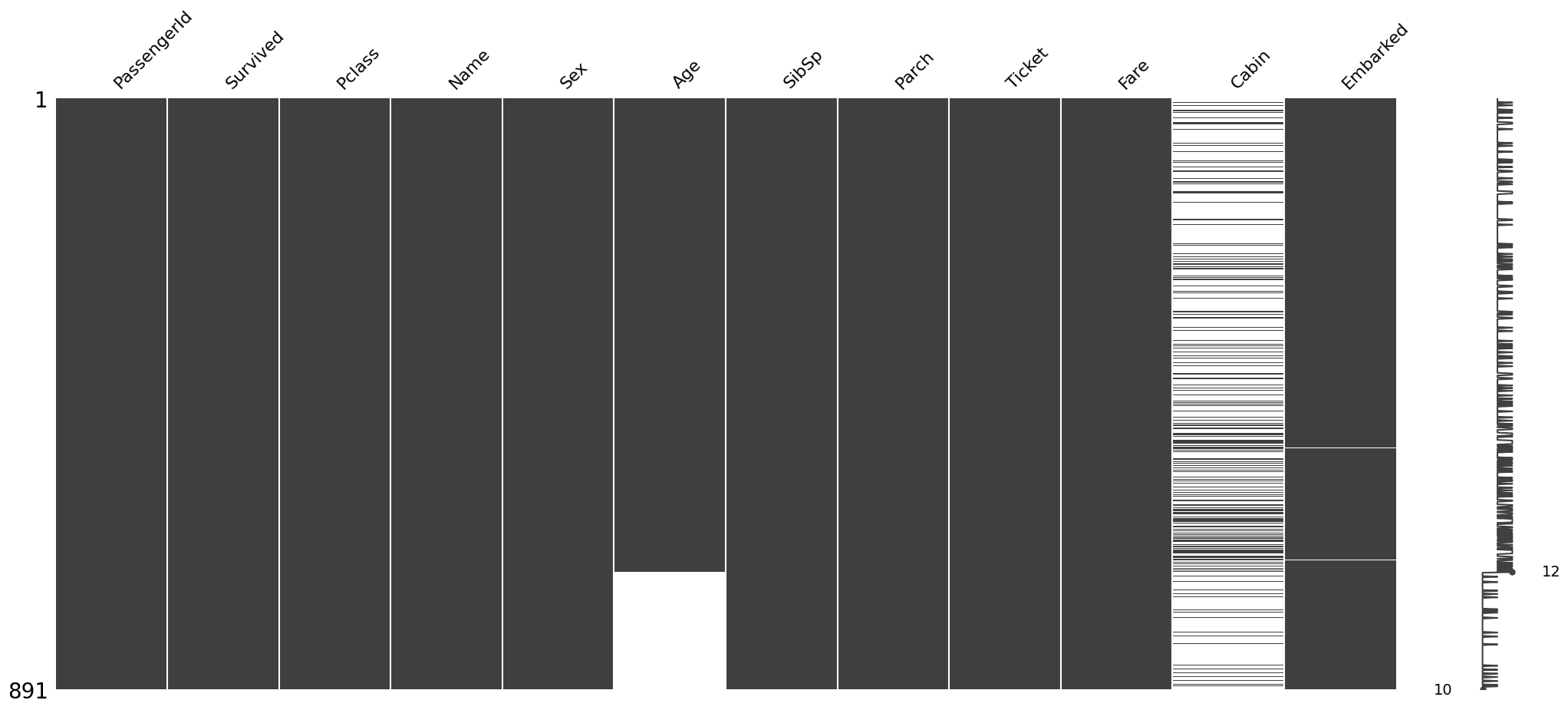
Hence it is clear that here is no relation between the missingness in Age and Cabin column.To cement this conclusion further we can also draw a Heatmap among the different variables in the dataset.
Finding reason for missing data using a Heatmap¶
msno.heatmap(train)<Axes: >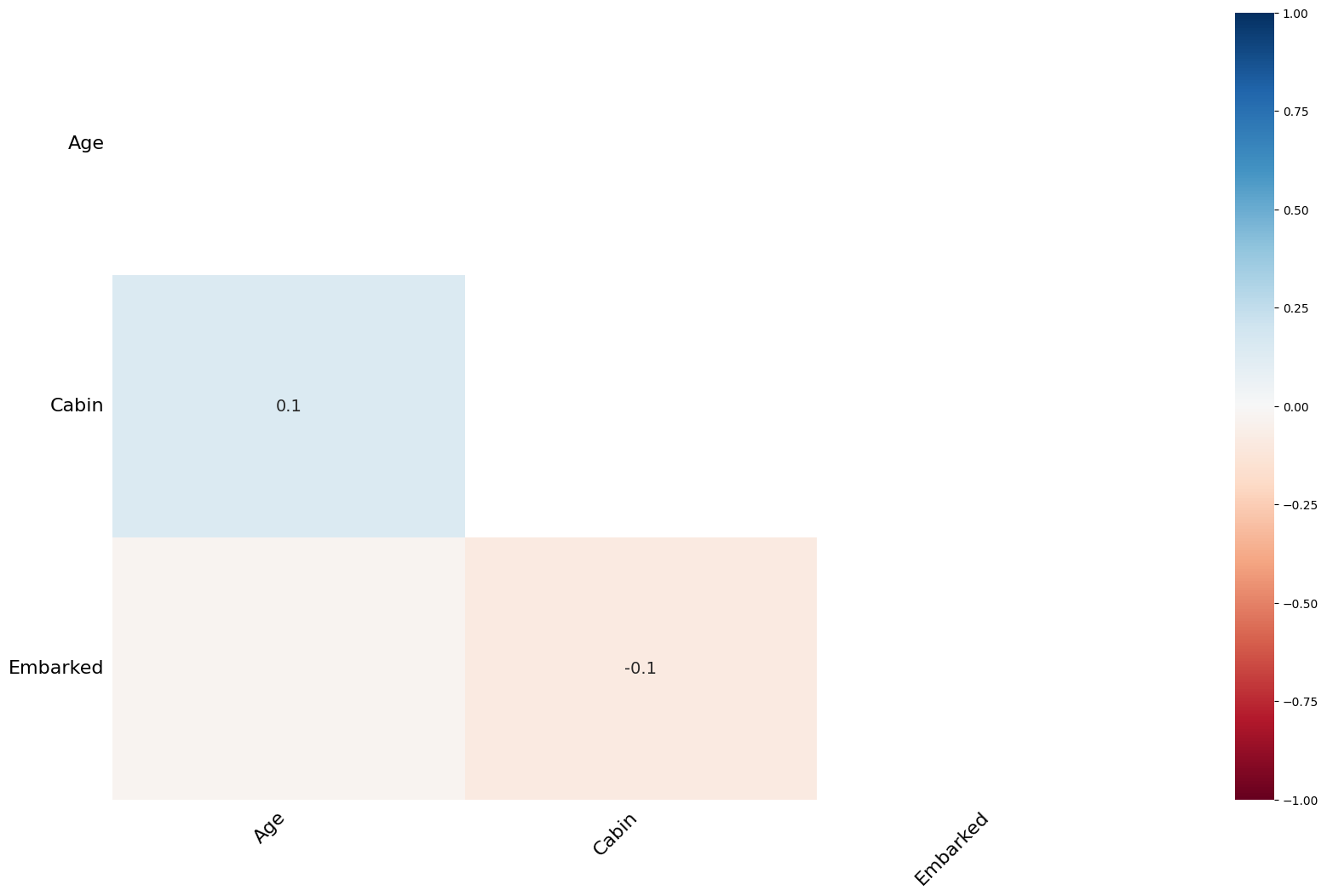
The heatmap function shows that there are no strong correlations between missing values of different features. This is good; low correlations further indicate that the data are MAR.
Finding reason for missing data using Dendrogram¶
A dendogram is a tree diagram of missingness. It groups the highly correlated variables together.
msno.dendrogram(train)<Axes: >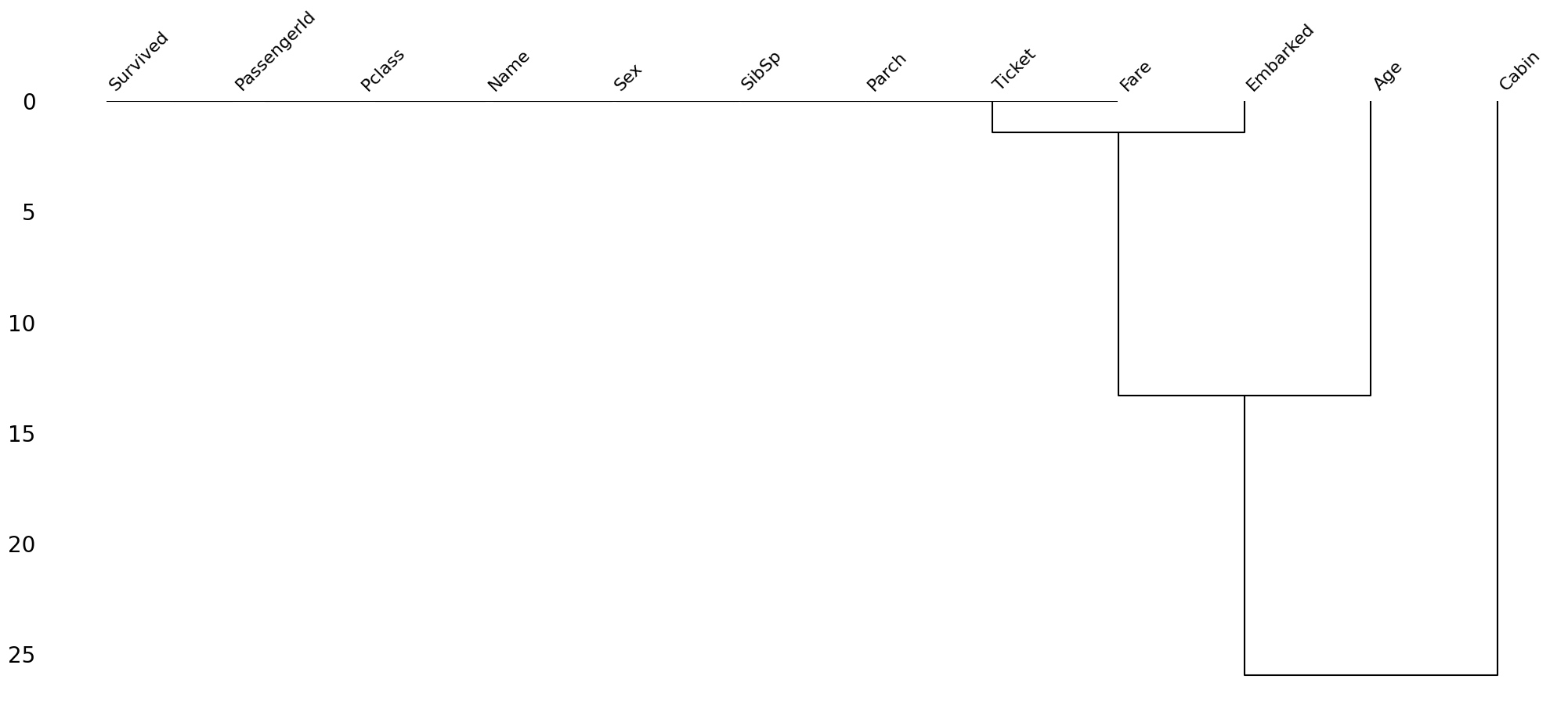
Let’s read the above dendrogram from a top-down perspective:
Cluster leaves which linked together at a distance of zero fully predict one another’s presence—one variable might always be empty when another is filled, or they might always both be filled or both empty, and so on(missingno documentation)
the missingness of Embarked tends to be more similar to Age than to Cabin and so on.However, in this particluar case, the correlation is high since Embarked column has a very few missing values.

This dataset doesn’t have much missing values but if you use the same methodology on datasets having a lot of missing values, some interesting pattern will definitely emerge.
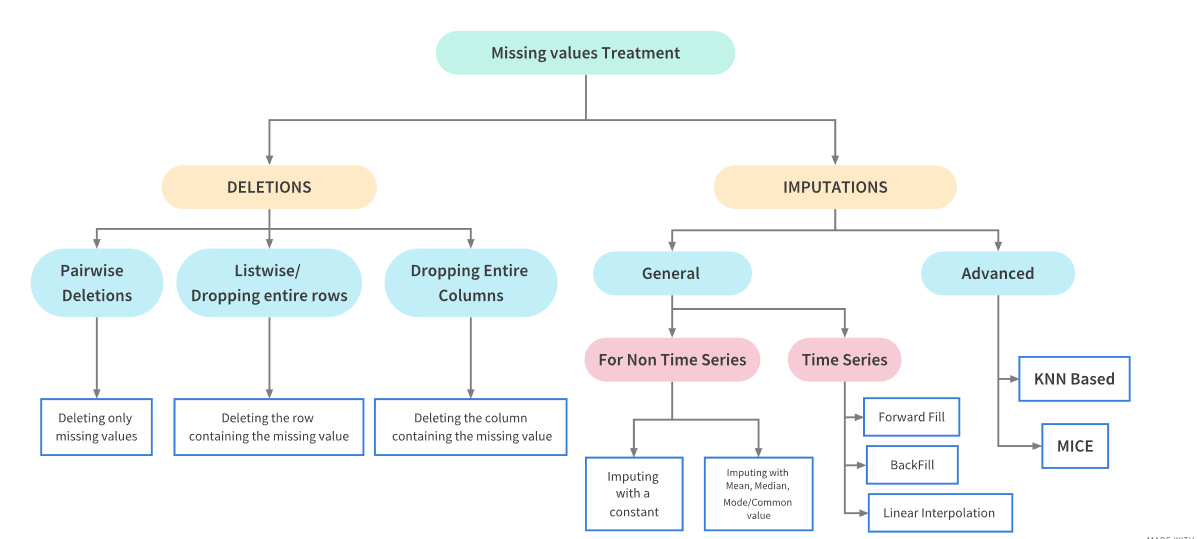
Treating Missing values¶
After having identified the patterns in missing values, it is important to treat them too. Here is a flowchart which could prove handy:
Deletions¶
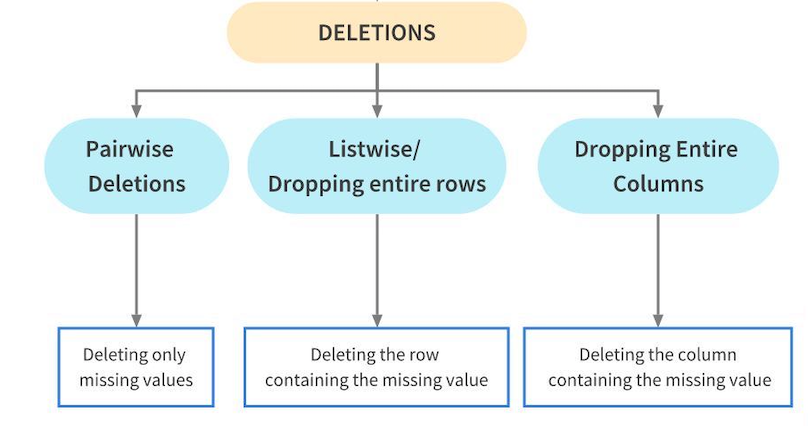
Deletion means to delete the missing values from a dataset. This is however not recommended as it might result in loss of information from the dataset. We should only delete the missing values from a dataset if their proportion is very small. Deletions are further of three types:
Pairwise Deletion¶
Parwise Deletion is used when values are missing completely at random i.e MCAR. During Pairwise deletion, only the missing values are deleted. All operations in pandas like mean,sum etc intrinsically skip missing values.
train.isnull().sum()PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64train_1 = train.copy()
train_1['Age'].mean() #pandas skips the missing values and calculates mean of the remaining values.np.float64(29.69911764705882)Listwise Deletion/ Dropping rows¶
During Listwise deletion, complete rows(which contain the missing values) are deleted. As a result, it is also called Complete Case deletion. Like Pairwise deletion, listwise deletions are also only used for MCAR values.
#Drop rows which contains any NaN or missing value for Age column
train_1.dropna(subset=['Age'],how='any',inplace=True)
train_1['Age'].isnull().sum()np.int64(0)The Age column doesn’t have any missing values.A major diadvantage of Listwise deletion is that a major chunk of data and hence a lot of information is lost. Hence, it is advisable to use it only when the number of missing values is very small.
Dropping complete columns¶
If a column contains a lot of missing values, say more than 80%, and the feature is not significant, you might want to delete that feature. However, again, it is not a good methodology to delete data.
Imputations Techniques for non Time Series Problems¶
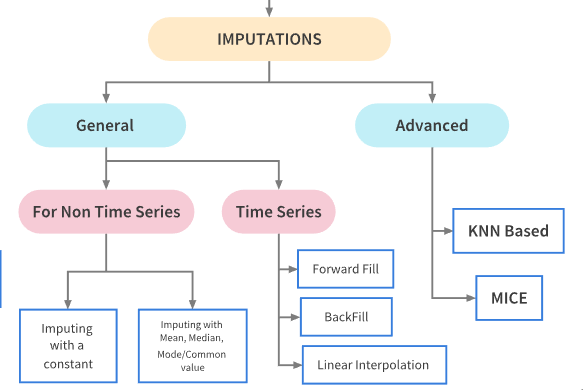
Imputation refers to replacing missing data with substituted values.There are a lot of ways in which the missing values can be imputed depending upon the nature of the problem and data. Dependng upon the nature of the problem, imputation techniques can be broadly they can be classified as follows:
Basic Imputation Techniques¶
Imputating with a constant value
Imputation using the statistics (mean, median or most frequent) of each column in which the missing values are located
For this we shall use the The SimpleImputer class from sklearn.
# imputing with a constant
from sklearn.impute import SimpleImputer
train_constant = train.copy()
#setting strategy to 'constant'
mean_imputer = SimpleImputer(strategy='constant') # imputing using constant value
train_constant.iloc[:,:] = mean_imputer.fit_transform(train_constant)
train_constant.isnull().sum()/var/folders/52/jywb2x0n3tbfhc83q6yhpn5c0000gn/T/ipykernel_49385/903951254.py:7: FutureWarning: Setting an item of incompatible dtype is deprecated and will raise in a future error of pandas. Value '[22.0, 38.0, 26.0, 35.0, 35.0, 'missing_value', 54.0, 2.0, 27.0, 14.0, 4.0, 58.0, 20.0, 39.0, 14.0, 55.0, 2.0, 'missing_value', 31.0, 'missing_value', 35.0, 34.0, 15.0, 28.0, 8.0, 38.0, 'missing_value', 19.0, 'missing_value', 'missing_value', 40.0, 'missing_value', 'missing_value', 66.0, 28.0, 42.0, 'missing_value', 21.0, 18.0, 14.0, 40.0, 27.0, 'missing_value', 3.0, 19.0, 'missing_value', 'missing_value', 'missing_value', 'missing_value', 18.0, 7.0, 21.0, 49.0, 29.0, 65.0, 'missing_value', 21.0, 28.5, 5.0, 11.0, 22.0, 38.0, 45.0, 4.0, 'missing_value', 'missing_value', 29.0, 19.0, 17.0, 26.0, 32.0, 16.0, 21.0, 26.0, 32.0, 25.0, 'missing_value', 'missing_value', 0.83, 30.0, 22.0, 29.0, 'missing_value', 28.0, 17.0, 33.0, 16.0, 'missing_value', 23.0, 24.0, 29.0, 20.0, 46.0, 26.0, 59.0, 'missing_value', 71.0, 23.0, 34.0, 34.0, 28.0, 'missing_value', 21.0, 33.0, 37.0, 28.0, 21.0, 'missing_value', 38.0, 'missing_value', 47.0, 14.5, 22.0, 20.0, 17.0, 21.0, 70.5, 29.0, 24.0, 2.0, 21.0, 'missing_value', 32.5, 32.5, 54.0, 12.0, 'missing_value', 24.0, 'missing_value', 45.0, 33.0, 20.0, 47.0, 29.0, 25.0, 23.0, 19.0, 37.0, 16.0, 24.0, 'missing_value', 22.0, 24.0, 19.0, 18.0, 19.0, 27.0, 9.0, 36.5, 42.0, 51.0, 22.0, 55.5, 40.5, 'missing_value', 51.0, 16.0, 30.0, 'missing_value', 'missing_value', 44.0, 40.0, 26.0, 17.0, 1.0, 9.0, 'missing_value', 45.0, 'missing_value', 28.0, 61.0, 4.0, 1.0, 21.0, 56.0, 18.0, 'missing_value', 50.0, 30.0, 36.0, 'missing_value', 'missing_value', 9.0, 1.0, 4.0, 'missing_value', 'missing_value', 45.0, 40.0, 36.0, 32.0, 19.0, 19.0, 3.0, 44.0, 58.0, 'missing_value', 42.0, 'missing_value', 24.0, 28.0, 'missing_value', 34.0, 45.5, 18.0, 2.0, 32.0, 26.0, 16.0, 40.0, 24.0, 35.0, 22.0, 30.0, 'missing_value', 31.0, 27.0, 42.0, 32.0, 30.0, 16.0, 27.0, 51.0, 'missing_value', 38.0, 22.0, 19.0, 20.5, 18.0, 'missing_value', 35.0, 29.0, 59.0, 5.0, 24.0, 'missing_value', 44.0, 8.0, 19.0, 33.0, 'missing_value', 'missing_value', 29.0, 22.0, 30.0, 44.0, 25.0, 24.0, 37.0, 54.0, 'missing_value', 29.0, 62.0, 30.0, 41.0, 29.0, 'missing_value', 30.0, 35.0, 50.0, 'missing_value', 3.0, 52.0, 40.0, 'missing_value', 36.0, 16.0, 25.0, 58.0, 35.0, 'missing_value', 25.0, 41.0, 37.0, 'missing_value', 63.0, 45.0, 'missing_value', 7.0, 35.0, 65.0, 28.0, 16.0, 19.0, 'missing_value', 33.0, 30.0, 22.0, 42.0, 22.0, 26.0, 19.0, 36.0, 24.0, 24.0, 'missing_value', 23.5, 2.0, 'missing_value', 50.0, 'missing_value', 'missing_value', 19.0, 'missing_value', 'missing_value', 0.92, 'missing_value', 17.0, 30.0, 30.0, 24.0, 18.0, 26.0, 28.0, 43.0, 26.0, 24.0, 54.0, 31.0, 40.0, 22.0, 27.0, 30.0, 22.0, 'missing_value', 36.0, 61.0, 36.0, 31.0, 16.0, 'missing_value', 45.5, 38.0, 16.0, 'missing_value', 'missing_value', 29.0, 41.0, 45.0, 45.0, 2.0, 24.0, 28.0, 25.0, 36.0, 24.0, 40.0, 'missing_value', 3.0, 42.0, 23.0, 'missing_value', 15.0, 25.0, 'missing_value', 28.0, 22.0, 38.0, 'missing_value', 'missing_value', 40.0, 29.0, 45.0, 35.0, 'missing_value', 30.0, 60.0, 'missing_value', 'missing_value', 24.0, 25.0, 18.0, 19.0, 22.0, 3.0, 'missing_value', 22.0, 27.0, 20.0, 19.0, 42.0, 1.0, 32.0, 35.0, 'missing_value', 18.0, 1.0, 36.0, 'missing_value', 17.0, 36.0, 21.0, 28.0, 23.0, 24.0, 22.0, 31.0, 46.0, 23.0, 28.0, 39.0, 26.0, 21.0, 28.0, 20.0, 34.0, 51.0, 3.0, 21.0, 'missing_value', 'missing_value', 'missing_value', 33.0, 'missing_value', 44.0, 'missing_value', 34.0, 18.0, 30.0, 10.0, 'missing_value', 21.0, 29.0, 28.0, 18.0, 'missing_value', 28.0, 19.0, 'missing_value', 32.0, 28.0, 'missing_value', 42.0, 17.0, 50.0, 14.0, 21.0, 24.0, 64.0, 31.0, 45.0, 20.0, 25.0, 28.0, 'missing_value', 4.0, 13.0, 34.0, 5.0, 52.0, 36.0, 'missing_value', 30.0, 49.0, 'missing_value', 29.0, 65.0, 'missing_value', 50.0, 'missing_value', 48.0, 34.0, 47.0, 48.0, 'missing_value', 38.0, 'missing_value', 56.0, 'missing_value', 0.75, 'missing_value', 38.0, 33.0, 23.0, 22.0, 'missing_value', 34.0, 29.0, 22.0, 2.0, 9.0, 'missing_value', 50.0, 63.0, 25.0, 'missing_value', 35.0, 58.0, 30.0, 9.0, 'missing_value', 21.0, 55.0, 71.0, 21.0, 'missing_value', 54.0, 'missing_value', 25.0, 24.0, 17.0, 21.0, 'missing_value', 37.0, 16.0, 18.0, 33.0, 'missing_value', 28.0, 26.0, 29.0, 'missing_value', 36.0, 54.0, 24.0, 47.0, 34.0, 'missing_value', 36.0, 32.0, 30.0, 22.0, 'missing_value', 44.0, 'missing_value', 40.5, 50.0, 'missing_value', 39.0, 23.0, 2.0, 'missing_value', 17.0, 'missing_value', 30.0, 7.0, 45.0, 30.0, 'missing_value', 22.0, 36.0, 9.0, 11.0, 32.0, 50.0, 64.0, 19.0, 'missing_value', 33.0, 8.0, 17.0, 27.0, 'missing_value', 22.0, 22.0, 62.0, 48.0, 'missing_value', 39.0, 36.0, 'missing_value', 40.0, 28.0, 'missing_value', 'missing_value', 24.0, 19.0, 29.0, 'missing_value', 32.0, 62.0, 53.0, 36.0, 'missing_value', 16.0, 19.0, 34.0, 39.0, 'missing_value', 32.0, 25.0, 39.0, 54.0, 36.0, 'missing_value', 18.0, 47.0, 60.0, 22.0, 'missing_value', 35.0, 52.0, 47.0, 'missing_value', 37.0, 36.0, 'missing_value', 49.0, 'missing_value', 49.0, 24.0, 'missing_value', 'missing_value', 44.0, 35.0, 36.0, 30.0, 27.0, 22.0, 40.0, 39.0, 'missing_value', 'missing_value', 'missing_value', 35.0, 24.0, 34.0, 26.0, 4.0, 26.0, 27.0, 42.0, 20.0, 21.0, 21.0, 61.0, 57.0, 21.0, 26.0, 'missing_value', 80.0, 51.0, 32.0, 'missing_value', 9.0, 28.0, 32.0, 31.0, 41.0, 'missing_value', 20.0, 24.0, 2.0, 'missing_value', 0.75, 48.0, 19.0, 56.0, 'missing_value', 23.0, 'missing_value', 18.0, 21.0, 'missing_value', 18.0, 24.0, 'missing_value', 32.0, 23.0, 58.0, 50.0, 40.0, 47.0, 36.0, 20.0, 32.0, 25.0, 'missing_value', 43.0, 'missing_value', 40.0, 31.0, 70.0, 31.0, 'missing_value', 18.0, 24.5, 18.0, 43.0, 36.0, 'missing_value', 27.0, 20.0, 14.0, 60.0, 25.0, 14.0, 19.0, 18.0, 15.0, 31.0, 4.0, 'missing_value', 25.0, 60.0, 52.0, 44.0, 'missing_value', 49.0, 42.0, 18.0, 35.0, 18.0, 25.0, 26.0, 39.0, 45.0, 42.0, 22.0, 'missing_value', 24.0, 'missing_value', 48.0, 29.0, 52.0, 19.0, 38.0, 27.0, 'missing_value', 33.0, 6.0, 17.0, 34.0, 50.0, 27.0, 20.0, 30.0, 'missing_value', 25.0, 25.0, 29.0, 11.0, 'missing_value', 23.0, 23.0, 28.5, 48.0, 35.0, 'missing_value', 'missing_value', 'missing_value', 36.0, 21.0, 24.0, 31.0, 70.0, 16.0, 30.0, 19.0, 31.0, 4.0, 6.0, 33.0, 23.0, 48.0, 0.67, 28.0, 18.0, 34.0, 33.0, 'missing_value', 41.0, 20.0, 36.0, 16.0, 51.0, 'missing_value', 30.5, 'missing_value', 32.0, 24.0, 48.0, 57.0, 'missing_value', 54.0, 18.0, 'missing_value', 5.0, 'missing_value', 43.0, 13.0, 17.0, 29.0, 'missing_value', 25.0, 25.0, 18.0, 8.0, 1.0, 46.0, 'missing_value', 16.0, 'missing_value', 'missing_value', 25.0, 39.0, 49.0, 31.0, 30.0, 30.0, 34.0, 31.0, 11.0, 0.42, 27.0, 31.0, 39.0, 18.0, 39.0, 33.0, 26.0, 39.0, 35.0, 6.0, 30.5, 'missing_value', 23.0, 31.0, 43.0, 10.0, 52.0, 27.0, 38.0, 27.0, 2.0, 'missing_value', 'missing_value', 1.0, 'missing_value', 62.0, 15.0, 0.83, 'missing_value', 23.0, 18.0, 39.0, 21.0, 'missing_value', 32.0, 'missing_value', 20.0, 16.0, 30.0, 34.5, 17.0, 42.0, 'missing_value', 35.0, 28.0, 'missing_value', 4.0, 74.0, 9.0, 16.0, 44.0, 18.0, 45.0, 51.0, 24.0, 'missing_value', 41.0, 21.0, 48.0, 'missing_value', 24.0, 42.0, 27.0, 31.0, 'missing_value', 4.0, 26.0, 47.0, 33.0, 47.0, 28.0, 15.0, 20.0, 19.0, 'missing_value', 56.0, 25.0, 33.0, 22.0, 28.0, 25.0, 39.0, 27.0, 19.0, 'missing_value', 26.0, 32.0]' has dtype incompatible with float64, please explicitly cast to a compatible dtype first.
train_constant.iloc[:,:] = mean_imputer.fit_transform(train_constant)
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 0
Embarked 0
dtype: int64from sklearn.impute import SimpleImputer
train_most_frequent = train.copy()
#setting strategy to 'mean' to impute by the mean
mean_imputer = SimpleImputer(strategy='most_frequent')# strategy can also be mean or median
train_most_frequent.iloc[:,:] = mean_imputer.fit_transform(train_most_frequent)train_most_frequent.isnull().sum()PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 0
Embarked 0
dtype: int64Imputations Techniques for Time Series Problems¶
Now let’s look at ways to impute data in a typical time series problem. Tackling missing values in time Series problem is a bit different. The fillna() method is used for imputing missing values in such problems.
Basic Imputation Techniques
‘ffill’ or ‘pad’ - Replace NaN s with last observed value
‘bfill’ or ‘backfill’ - Replace NaN s with next observed value
Linear interpolation method
Time Series dataset¶
The dataset is called Air Quality Data in India (2015 - 2020) Tand it contains air quality data and AQI (Air Quality Index) at hourly and daily level of various stations across multiple cities in India.The dataset has a lot of missing values and and is a classic Time series problem.
city_day = pd.read_csv('archive/city_day.csv',parse_dates=True,index_col='Date')
city_day1=city_day.copy(deep=True)
city_day.head()I won’t go much into explaining the data since I have done a lot of relatedw work in my kernel titled 😷 Breathe India: COVID-19 effect on Pollution.In this notebook, let’s keep our focus on the missing values only. As id evident, city_day dataframe consists of daily pollution level data of some of the prominent cities in India.
#Missing Values
city_day_missing= missing_values_table(city_day)
city_day_missingYour selected dataframe has 15 columns.
There are 14 columns that have missing values.
There are a lot of missing values and some of the columns like Xylene and PM10 have more than 50% of the values missing. Let’s now see how we can impute these missing values.
# Imputation using ffill/pad
# Imputing Xylene value
city_day['Xylene'][50:64]
Date
2015-02-20 7.48
2015-02-21 15.44
2015-02-22 8.47
2015-02-23 28.46
2015-02-24 6.05
2015-02-25 0.81
2015-02-26 NaN
2015-02-27 NaN
2015-02-28 NaN
2015-03-01 1.32
2015-03-02 0.22
2015-03-03 2.25
2015-03-04 1.55
2015-03-05 4.13
Name: Xylene, dtype: float64Above we see, there are 3 missing values in the Xylene column.
Imputing using ffill¶
city_day.fillna(method='ffill',inplace=True)
city_day['Xylene'][50:65]/var/folders/52/jywb2x0n3tbfhc83q6yhpn5c0000gn/T/ipykernel_49385/831388782.py:1: FutureWarning: DataFrame.fillna with 'method' is deprecated and will raise in a future version. Use obj.ffill() or obj.bfill() instead.
city_day.fillna(method='ffill',inplace=True)
Date
2015-02-20 7.48
2015-02-21 15.44
2015-02-22 8.47
2015-02-23 28.46
2015-02-24 6.05
2015-02-25 0.81
2015-02-26 0.81
2015-02-27 0.81
2015-02-28 0.81
2015-03-01 1.32
2015-03-02 0.22
2015-03-03 2.25
2015-03-04 1.55
2015-03-05 4.13
2015-03-06 4.13
Name: Xylene, dtype: float64We can see that all missing values have been filled with the last observed values.
Imputation using bfill¶
# Imputing AQI value
city_day['AQI'][20:30]Date
2015-01-21 NaN
2015-01-22 NaN
2015-01-23 NaN
2015-01-24 NaN
2015-01-25 NaN
2015-01-26 NaN
2015-01-27 NaN
2015-01-28 NaN
2015-01-29 209.0
2015-01-30 328.0
Name: AQI, dtype: float64city_day.fillna(method='bfill',inplace=True)
city_day['AQI'][20:30]/var/folders/52/jywb2x0n3tbfhc83q6yhpn5c0000gn/T/ipykernel_49385/4086047996.py:1: FutureWarning: DataFrame.fillna with 'method' is deprecated and will raise in a future version. Use obj.ffill() or obj.bfill() instead.
city_day.fillna(method='bfill',inplace=True)
Date
2015-01-21 209.0
2015-01-22 209.0
2015-01-23 209.0
2015-01-24 209.0
2015-01-25 209.0
2015-01-26 209.0
2015-01-27 209.0
2015-01-28 209.0
2015-01-29 209.0
2015-01-30 328.0
Name: AQI, dtype: float64We can see that all missing values have been filled with the next observed values.
Imputation using Linear Interpolation method¶
Time series data has a lot of variations against time. Hence, imputing using backfill and forward fill isn’t the ebst possible solution to address the missing value problem. A more apt alternative would be to use interpolation methods, where the values are filled with incrementing or decrementing values.
Linear interpolation is an imputation technique that assumes a linear relationship between data points and utilises non-missing values from adjacent data points to compute a value for a missing data point.
Refer to the official documentation for a complete list of interpolation strategies here
city_day1['Xylene'][50:65]Date
2015-02-20 7.48
2015-02-21 15.44
2015-02-22 8.47
2015-02-23 28.46
2015-02-24 6.05
2015-02-25 0.81
2015-02-26 NaN
2015-02-27 NaN
2015-02-28 NaN
2015-03-01 1.32
2015-03-02 0.22
2015-03-03 2.25
2015-03-04 1.55
2015-03-05 4.13
2015-03-06 NaN
Name: Xylene, dtype: float64# Interpolate using the linear method
city_day1.interpolate(limit_direction="both",inplace=True)
city_day1['Xylene'][50:65]/var/folders/52/jywb2x0n3tbfhc83q6yhpn5c0000gn/T/ipykernel_49385/2164861449.py:2: FutureWarning: DataFrame.interpolate with object dtype is deprecated and will raise in a future version. Call obj.infer_objects(copy=False) before interpolating instead.
city_day1.interpolate(limit_direction="both",inplace=True)
Date
2015-02-20 7.4800
2015-02-21 15.4400
2015-02-22 8.4700
2015-02-23 28.4600
2015-02-24 6.0500
2015-02-25 0.8100
2015-02-26 0.9375
2015-02-27 1.0650
2015-02-28 1.1925
2015-03-01 1.3200
2015-03-02 0.2200
2015-03-03 2.2500
2015-03-04 1.5500
2015-03-05 4.1300
2015-03-06 2.2600
Name: Xylene, dtype: float64Advanced Imputation Techniques¶
Advanced imputation techniques uses machine learning algorithms to impute the missing values in a dataset unlike the previous techniques where we used other column values to predict the missing values. We shall look at the following two techniques in this notebook:
K-Nearest Neighbor Imputation¶
The KNNImputer class provides imputation for filling in missing values using the k-Nearest Neighbors approach.Each missing feature is imputed using values from n_neighbors nearest neighbors that have a value for the feature. The feature of the neighbors are averaged uniformly or weighted by distance to each neighbor.
train_knn = train.copy(deep=True)from sklearn.impute import KNNImputer
train_knn = train.copy(deep=True)
knn_imputer = KNNImputer(n_neighbors=2, weights="uniform")
train_knn['Age'] = knn_imputer.fit_transform(train_knn[['Age']])train_knn['Age'].isnull().sum()
np.int64(0)Multivariate feature imputation - Multivariate imputation by chained equations (MICE)¶
A strategy for imputing missing values by modeling each feature with missing values as a function of other features in a round-robin fashion. It performns multiple regressions over random sample ofthe data, then takes the average ofthe multiple regression values and uses that value to impute the missing value. In sklearn, it is implemented as follows:
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
train_mice = train.copy(deep=True)
mice_imputer = IterativeImputer()
train_mice['Age'] = mice_imputer.fit_transform(train_mice[['Age']])train_mice['Age'].isnull().sum()np.int64(0)Algorithms which handle missing values¶
Some algprithms like XGBoost and LightGBM can handle missing values without any preprocessing, by supplying relevant parameters.


Conclusion¶
Well, there is no single best way to handle missing values. One needs to experiment with different methods and then decide which method is best for a particular problem.